




Questa è la posizione da unire al Recommended Unique Concern High Quality Information,semplicemente perche' non potrebbe proprio esistere attraverso dei Duplicati e per avere il loro Opposto, l'unica possibilita' che esiste Realmente è quella dell'Original;Unique e Content Value, ed è meglio fare l'AVOID GENERALE,rispetto a "qualsiasi tattica alternativa",perche' in realta' non esiste nessuna:)

Per avere questa posizione è arrivato il Pass Generale del Divertimento,ed è il Signore sotto:)



Le descrizioni fatte servono a giustificare la scelta del nome per questa FGL SEP 2024,ed è nata dalle posizioni dell'Holy Grail TFD Google Merchant per il Recommended High Quality Information,mentre l'Unique Concern Value deriva dalla Logica stessa e da FGL SEP 2024 avra un riferimento esatto e poteva essere solo il Time Glory Data,dedicato a tutti gli straordinari Developers dell'anno meraviglioso 2019:)



Per conoscere le differenze,rispetto ai volumi selezionati,la migliore posizione è quella sopra,ed è possibile avere anche il collegamento strutturale,attraverso il banner centrale del dominio (attualmente è quello del Frame Global Limit) e si ha lo spazio dedicato a Page Solemn.

e non è mai esistita una selezione uguale alla precedente,anche possedendo minime differenze e l'unica ragione deriva dalle dimensioni dei Content stessi,perche' attraverso volumi del genere,è oggettivamente impossibile che possano esistere tante differenze e quindi l'unica possibilita' deriva dal fatto che sono diversi i contenuti e per averli occorre che siano diverse anche le dimensioni e questa è la posizione piu' bella per festeggiare FGL SEP 2024,perche' il contesto descritto occorre poi unirlo al Recommended High Quality Information e l'unione non puo essere realizzata dai Duplicati:)

L'unione tra il Recommended High Quality Information dell'Holy Grail TFD Google Merchant e la Logica di Unique Concern Value,avra' un ruolo oggettivo,semplicemente perche' le selezioni di JULY e AUG 2024,non hanno le divisioni degli anni nelle loro rispettive pubblicazioni e li avranno in questo FGL SEP 2024 e grazie alle loro differenze,nonostante i volumi colossali a cui sono uniti,diventera' semplicissimo comprendere il valore dell'High Quality Information e nello stesso tempo,sara' facilissimo comprendere quello dell'Unique Concern Value:) https://dinpoststory.blogspot.com/2024/08/hb-just-time-juice-events-litigation.html
https://dinpoststory.blogspot.com/2024/08/hb-just-time-juice-events-litigation.html
Questo è il Top delle PREOCCUPAZIONI,raggiunto dal "Capo dell'Informatica Populista" Ionos e grazie all'Holy Grail TFD Google Merchant,l'emoticon "dell'High Funny Ranking" probabilmente avra' "presenze inflazionate",perche' sono tantissime le posizioni a cui poterlo unire e il riferimento è sempre ai presunti Top Domini,semplicemente perche' sono i piu' Divertenti da "prendere per il culo" e grazie a Google Merchant,il Divertimento è amplificato notevolmente,perche' i presunti domini Top,a loro volta,sono uniti ai Prodotti e Servizi e la compatibilita con High Quality Information è molto scarsa e il Divertimento reale è unito a Unique Concern Value e cioe' sono "Le Grandi Preoccupazioni" degli operatori (simili a Ionos sistemato sopra:) per arrivare a Dati palesemente Falsi:)
Questo è il Top delle PREOCCUPAZIONI,raggiunto dal "Capo dell'Informatica Populista" Ionos e grazie all'Holy Grail TFD Google Merchant,l'emoticon "dell'High Funny Ranking" probabilmente avra' "presenze inflazionate",perche' sono tantissime le posizioni a cui poterlo unire e il riferimento è sempre ai presunti Top Domini,semplicemente perche' sono i piu' Divertenti da "prendere per il culo" e grazie a Google Merchant,il Divertimento è amplificato notevolmente,perche' i presunti domini Top,a loro volta,sono uniti ai Prodotti e Servizi e la compatibilita con High Quality Information è molto scarsa e il Divertimento reale è unito a Unique Concern Value e cioe' sono "Le Grandi Preoccupazioni" degli operatori (simili a Ionos sistemato sopra:) per arrivare a Dati palesemente Falsi:)

Tornando alle pubblicazioni protagoniste delle selezioni,per arrivare al Recommended High Quality Information,esistono le due selezioni di July e AUG 2024 e sono Divertenti loro stesse,perche' hanno esattamente lo stesso numero di pubblicazioni e i volumi sono separati da soli 32 termini effettivi,all'interno di 1 sola posizione e i contenuti non sono uniti a una "Categoria Generica e Super Easy" nello stesso tempo,ma è esattamente l'opposto,perche' l'Information Technology è in assoluto la categoria piu' Ostica dell'intero Contesto Online:)

Per distinguere le pubblicazioni,naturalmente esistono le date,pero' non sono presenti nei Match e per ricordare il contesto specifico del report,esiste l'evidenza unita ai Broken e agli Skipped e quelli sistemati sopra appartengono a FGL AUG 2024.

Esistono sempre 216 pubblicazioni nelle selezioni,pero' nei reports dei Duplicati non sono presenti le date e per distinguere FGL JULY 2024,esistono le evidenze sistemate sopra,unite ai Broken,agli Skipped e ai Duplicati.

Il senso è in Status Limiting Illogical Sense Main Content Content IT e la pubblicazione è proprio quella di FGL JULY 2024,pero' nella sua selezione il NOT FOUND in Sitemap,rispetto agli elementi degli Skipped ancora non era presente e la posizione attuale è davvero fantastica da unire al Recommended High Quality Information,perche' se dovesse esistere il Found in Sitemap,significa semplicemente che sono molto elevate le operazioni Unnatural e grazie a questa posizione,diventa semplice comprendere anche quanto sia pertinente l'Unique Concern Value,perche' avere la Preoccupazione di eliminare le pubblicazioni presenti nelle Sitemap (il Limiting Rate insieme agli Skipped hanno proprio l'eliminazione come Senso:),significa possedere l'Idiozia Totale,perche' non esiste nessuna possibilita',nel vero senso delle parole,di arrivare al Recommended dell'High Quality Information e cioe' ai Dati Veri,passando dagli Skipped anche delle Sitemap:)
Per l'Holy Grail TFD Google Merchant,esistono le stesse condizioni,utilizzate per i Bugs e a parte tutte le descrizioni per arrivarci,sono presenti anche i reports per i Bugs dell'intero Sistema e l'errore ha lo 0% (ZERO:) e quindi realmente non esiste nessuna possibilita di arrivare ai Dati Veri,utilizzando anche il Limiting Rate nelle Sitemap (è il senso reale dello Skipped sistemato sopra).

https://dinpoststory.blogspot.com/2024/05/size-solemn-quality-intelligence-score.html
A MAY 2024 esiste una larga descrizione dedicata al Clean delle Sitemap,ed è possibile anche attualizzare i suoi contenuti,grazie all'aiuto dell'Holy Grail TFD Google Merchant e del suo Recommended High Quality Information,perche' la prima posizione per averla è quella di evitare i Duplicati e poi a scalare tutte le altre possibili violazioni e quella di avere gli Skipped nelle Sitemap,è decisamente tra le piu' stupide violazioni e il contesto delle verifiche interne ai domini,restituisce l'idiozia oggettiva,perche' è Vero che è presente "il Vasto Ignore",pero' in compenso,nelle verifiche interne ai domini è presente "il Miglior Alleato Possibile" e sono le Irrelevant Keywords e per FGL SEP 2024 e per tutte le verifiche interne ai domini in generale,rispetto a qualsiasi dominio,esiste il contesto temporale piu' bello in assoluto, perche' i reports che seguiranno sono sistemati "tra Due Colonne dei Dati Veri" e sono i Just Time finali per i festeggiamenti del percorso in K5 e solo la presenza dei loro reports,significa che i dati delle verifiche,sono realmente i piu' vicini ai Major e occorre aggiungere anche ai Trust Engines:)
Naturalmente è possibile che i dati siano diversi nel contesto online effettivo,pero' se dovesse accadere,esistono elevate probabilita che sia l'Autore ad essere Disonesto e l'esempio migliore è quello di Wikimedia,perche' quasi sempre le Sitemap non le possiede nemmeno e se fossero presenti,è sicuro che Wikimedia,inventerebbe anche gli EDITS delle Sitemap:)

Qui è sistemata la pagina completa e sono 33 gli Errori presenti nelle selezioni e sono uniti tutti ai Target:)

Solo come esempio ho scelto l'anno 2019/05 tra gli errori degli Skipped e poi ne esistono altri 32 e tutti hanno la posizione sopra e cioe' effettivamente non esistono,pero' non sono state Eliminate le pubblicazioni (è il senso reale dello Status Code 404:) ,ma semplicemente i Target non sono abilitati e l'informazione è importantissima,perche' fornisce la migliore qualifica ai dati che seguiranno e cioe' le pubblicazioni non hanno nessun Skipped in realta',perche' esistono e tantissime di loro hanno partecipato ai match tra le selezioni di FGL SEP 2024:)







E' tratta dall'esempio evidenziato sopra e la Casualita' ha scelto come prima pubblicazione la data di AUG 2019 e cioe' del Time Glory Data e da sola è capace di rendere pertinentissimi gli High Quality Information,insieme all'Unique Concern Value,perche' dopo i developers del Time Glory data,avere la Preoccupazione dei Disallow,significa possedere l'idiozia assoluta e sara' particolarmente Divertente vederla applicata alle grandi organizzazioni e alle aziende Enterprise,insieme agli investimenti economici che hanno fatto e alle Custom CMS che utilizzano:)






https://dinpoststory.blogspot.com/2024/08/hb-fgl-holy-litigation-demonstrate-true.html
La presenza di The Verge è unita a questa posizione e diventera' facile comprendere cosa sono i NoIndex rispetto ai collegamenti interni dei domini e poi altri particolari ci saranno tra un po' e in questa posizione è utile ricordare la pubblicazione unita al collegamento sopra,ed è AUG 2024 e tra un po' ci saranno anche i suoi dati.



Sono state 11 le pubblicazioni selezionate.

Sono stati 106 i conflitti e la scelta di queste selezioni deriva solo dalla semplicita' dei reports,perche' sarebbe possibile sistemare anche le percentuali e il numero di termini stessi eliminati,pero' diventerebbe molto difficile sistemare tutti i reports e quindi per rendere semplice la collocazione dei dati,esiste la selezione del numero di pubblicazioni in Match e da sola ha gia' elevatissime capacita di evidenziare l'intero contesto,perche' avere 106 pubblicazioni in Match,solo in una selezione di 1 anno,rende semplicissimo comprendere cosa significa arrivare all'High Quality Information dell'Holy Grail TFD Google Merchant ,ed è sufficente unire l'operativita specifica unita a Prodotti e Servizi e quindi ai colossali investimenti economici uniti ad essi e si ha anche "il senso pratico" di Unique Concern Value e cioe di Comprendere quali sono le Vere Preoccupazioni per gli operatori online,uniti a qualsiasi Prodotto e Servizio:)






All'interno esiste realmente di tutto,oltre agli autori tradizionali e nei contenuti sono presenti anche i discorsi dei Presidenti USA e nella prima dimensione delle pubblicazioni di Novel Guide per il suo SEP 2024,è presente Kennedy e alla 4° posizione esiste il fantastico scienziato italiano,Galileo Galilei e la posizione deriva solo dalle dimensioni,rispetto alle selezioni fatte,perche' esistono altri celebri personaggi italiani,presenti nello stesso dominio e uno è Dante Alighieri e l'altro è Raffaello Sanzio:)
Lo spazio sembra realizzato "dagli oppositori totali" all'Unique Concern Value e non seguono assolutamente il Recommended dell'High Quality Information e cioe' l'unica Preoccupazione per chi opera nel contesto online (è l'Unique Concern Value) è quello di avere Unique;Original e Valore dei Content e cioe' l'High Quality Information e fuori da questo contesto,è tutto Artificial e Invalid Traffic e non occorre molta fantasia per immaginare cosa sarebbe il contesto online,se esistessero le "menti operative di Novel Guide" in opposizione completa anche alla Logica,perche' i contenuti del dominio sono presenti in altre migliaia di spazi:)



Sono le prime categorie unite alle False Quotes di Novelguide e nello stesso dominio esistono poi i contenuti uniti alle varie categorie (ad esempio Government possiede i discorsi dei Presidenti USA)

Da quest'insieme derivano i dati sopra e sono importanti in questa posizione, per rendere ancora piu' straordinarie le differenze delle selezioni per FGL July e AUG 2024 e il riferimento delle selezioni sono gli anni 2023 e 2022:)

Applicando il dato a tutto il volume di Novelguide per la sua SEP 2024,le dimensioni sopra formano quasi la sua meta' e se venisse applicato solo il Calculator degli Average,la differenza sistemata sopra,applicata all'intero volume di Novelguide,i dati sarebbero quelli sotto:)
 L'evidenza di colore blu ha il volume di Novelguide,realizzato attraverso "il metodo unico" descritto sopra,mentre l'evidenza di colore verde contiene il calcolo degli Average e il volume applicato,deriva solo dalle differenze tra le selezioni di FGL JULY e AUG 2024 e naturalmente nei calcoli non sono sistemati i Main Content e i Multi fact Check e nemmeno l'Unicita' dei dati perche' Novelguide è arrivata al 26% e anche ipotizzando che esistano pubblicazioni completamente immuni da qualsiasi Match precedente,applicando il 26% all'Average di Novelguide,si arriverebbe vicino ai Thin Content e quindi le pubblicazioni sarebbero proprio eliminate per sempre,senza nessuna necessita di applicare alcun Match:)
L'evidenza di colore blu ha il volume di Novelguide,realizzato attraverso "il metodo unico" descritto sopra,mentre l'evidenza di colore verde contiene il calcolo degli Average e il volume applicato,deriva solo dalle differenze tra le selezioni di FGL JULY e AUG 2024 e naturalmente nei calcoli non sono sistemati i Main Content e i Multi fact Check e nemmeno l'Unicita' dei dati perche' Novelguide è arrivata al 26% e anche ipotizzando che esistano pubblicazioni completamente immuni da qualsiasi Match precedente,applicando il 26% all'Average di Novelguide,si arriverebbe vicino ai Thin Content e quindi le pubblicazioni sarebbero proprio eliminate per sempre,senza nessuna necessita di applicare alcun Match:)
La posizione è importante,perche' oltre ad evidenziare i fantastici dati delle differenze nelle selezioni,permette di rendere molto semplice l'Unique Concern Value,perche' l'unica Preoccupazione Possibile è quella dell'High Quality Information e Novelguide,permette di rendere molto semplice,quantificare il livello di Difficolta solo per Arrivarci:)




Occorre ricordare che la comparazione è nata attraverso la selezione di soli 2 anni e il volume generato deriva solo dal calcolo delle differenze e rispetto al volume delle intere selezioni,rappresenta in realta' una piccola frazione dei volumi di FGL JULY e AUG 2024 (circa 1/6:)
Fino a questo punto,sono state sistemate solo le selezioni dell'anno 2023 in maniera completa,mentre per l'anno 2022,manca proprio la selezione festeggiata in questa pubblicazione,ed è FGL SEP 2024:)
Diversi regali li ha portati Direttamente (FGL SEP 2024:) e una è la Sitemap degli Skipped e un altro fantastico regalo è quello sopra,ed è l'Average stesso di FGL SEP 2024 e la posizione è davvero straordinaria,perche' tutte le comparazioni sistemate,unite a July e AUG 2024,derivano dal fatto di avere un Average separato da soli 32 termini,rispetto a 1 volume,sistemato in 1 sola posizione,molto vicino a 1,2 Milion Words:)
Diversi regali li ha portati Direttamente (FGL SEP 2024:) e una è la Sitemap degli Skipped e un altro fantastico regalo è quello sopra,ed è l'Average stesso di FGL SEP 2024 e la posizione è davvero straordinaria,perche' tutte le comparazioni sistemate,unite a July e AUG 2024,derivano dal fatto di avere un Average separato da soli 32 termini,rispetto a 1 volume,sistemato in 1 sola posizione,molto vicino a 1,2 Milion Words:)
L'Average di FGL SEP 2024 ha invece 2 soli termini in differenza (DUE:),oltre a 3 pubblicazioni,pero' la comparazione la possiede nei confronti dell'attuale Origin RF ONE di FGL FEB 2024:)
https://dinpoststory.blogspot.com/2024/02/overall-joy-dce-quality-score-fgl-feb.html
https://dinpoststory.blogspot.com/2024/02/overall-joy-dce-quality-score-fgl-feb.html
Questa è la pubblicazione e oltre ai suoi contenuti,possiede una piccola curiosita' ed è nel collgamento sotto:)


Nello score generale delle dimensioni del dominio,non è presente la 3° posizione,ed è quella di MAY 2023.

Qui sono sistemate le pubblicazioni selezionat dall'anno 2022 per FGL SEP 2024

Qui sono sistemate le pubblicazioni in Match per l'anno 2021 a FGL July 2024

Sono state presenti 45 pubblicazioni e tutte le comparazioni sistemate sopra,grazie all'anno 2020,diventano la migliore evidenza rispetto al Recommended Unique Concern Value e cioe' l'Unica Preoccupazione reale è quella dell'High Quality Information.


Ogni autore puo sistemare quello che vuole,nel proprio dominio,pero' deve essere unita anche la LOGICA e inizia dal fatto che la Preoccupazione del Copyright e la presenza dello Shop,deve essere unita al Possesso dei Contenuti,rispetto al dominio specifico e naturalmente non sempre avviene,grazie alla presenza dei Match all'interno di qualsiasi dominio e i Content rimasti immuni hanno poi i Conflitti globali e solo al termine si ha il possesso effettivo dell'High Quality Information e solo in questo contesto è Possibile avere la Preoccupazionde per le eventuali violazioni dei Copyright:)


Esiste una posizione davvero divertente,nella pagina dedicata alla Preoccupazione di violare il Copyright,perche' dopo lo SHOP, esiste anche la pretesa "di avere una DONAZIONE" e insieme ad essa è sistemato il codice BlockQuote,ed ha una posizione davvero particolare perche' è all'interno di una pubblicazione Non Eliggibile,a causa di una Struttura Data nemmeno Valida,ad iniziare dal fatto che non esiste proprio:)
Quindi sistemare il BlockQuote non ha nessun senso,perche' le pubblicazioni vengono eliminate,solo per l'assenza di Struttura Data Valida e nel Caso specifico del dominio,la Non Eleggibilita' esisterebbe lo stesso,perche' i contenuti non sono stati creati dai gestori dello spazio,ma appartengono ad altri autori,presenti anche in altre migliaia di domini:)



La posizione del massiccio Link Building,facilissima da verificare anche in maniera Random (esistono 195 pubblicazioni solo nella selezione di SEP 2024 per il dominio dei Poeti Tradotti),perche' esistono al massimo 2 soli collegamenti,almeno per quasi il 50% di tutte le pubblicazioni del dominio,rende demenziale la posizione del codice del BlockQuote,semplicemente perche' i Limiti,sono Ignorati,grazie al fatto che i collegamenti esistono e per paradosso la posizione è anche Teorica,perche' le Strutture Data non esistono proprio e nel report è l'unica indicazione effettiva unita alle Strutture stesse:) Cioe' non è descritto l'eventuale Mismatch presente,semplicemente perche' lo strumento non conosce i contenuti originali e ancora meno conosce le Proposte Complessive dell'intero dominio e quindi viene sistemata solo la posizione fisica delle Strutture Data stesse e l'unico report è unito al fatto vero della Loro Esistenza o Meno:)


Tra i tanti "autori tradizionali tradotti" ,esiste anche il Somma Poeta Dante Alighieri e la posizione della mappa è davvero curiosa,perche' è sistemata "nella periferia sud estrema" della mappa stessa e significano oltre 1200 pubblicazioni e per arrivare a Dante Alighieri,è sufficente 1 solo Click e non è sistemato nel dominio,attraverso delle Sidebar ,ma è proprio strutturale allo spazio e con 2 solo Clicks per oltre 1200 pubblicazioni,la posizione diventa molto divertente,perche' la presenza massiccia di Unnatural Links è sicura al 100% e la stessa percentuale è unita ai contenuti stessi e cioe' al 100% appartengono ad altri autori,rispetto ai gestori del dominio dei Poeti Tradotti:)


In questo Caso il collegamento è diretto e sono presenti anche in questa pagina i codici delle BlockQuote insieme alla Preoccupazione del Copyright e tutto il contesto non possiede nemmeno una Struttura Data Valida e non significa che l'autore ha fatto del Mismatch,ma non è presente proprio fisicamente nessuna Struttura Data Valida:)


Questo è uno dei Public Records piu' curiosi unito al vero Copyright del TFD Giacomo Leopardi.
Questa è un altra curiosita,ed è il piu' antico certificato unito ai diritti del copyright per il TFD Giacomo Leopardi e il documento è dell'anno 1939.

In questa posizione è impossibile sistemare le tante demenze unite "al solito ruolo monopolista" dell'Holy Grail TFD Google e quindi mi limito all'essenziale,da unire ai contenuti collegati sopra e il primo riferimento è il dominio The Verge stesso,perche' la sua operativita' effettiva è molto vicina al metodo del dominio "dei Poeti Tradotti" e sopratutto sono False le posizioni "dedicate agli Engines Dominati" e cioe' alle "povere vittime" del monopolio dell'Holy Grail TFD Google:)
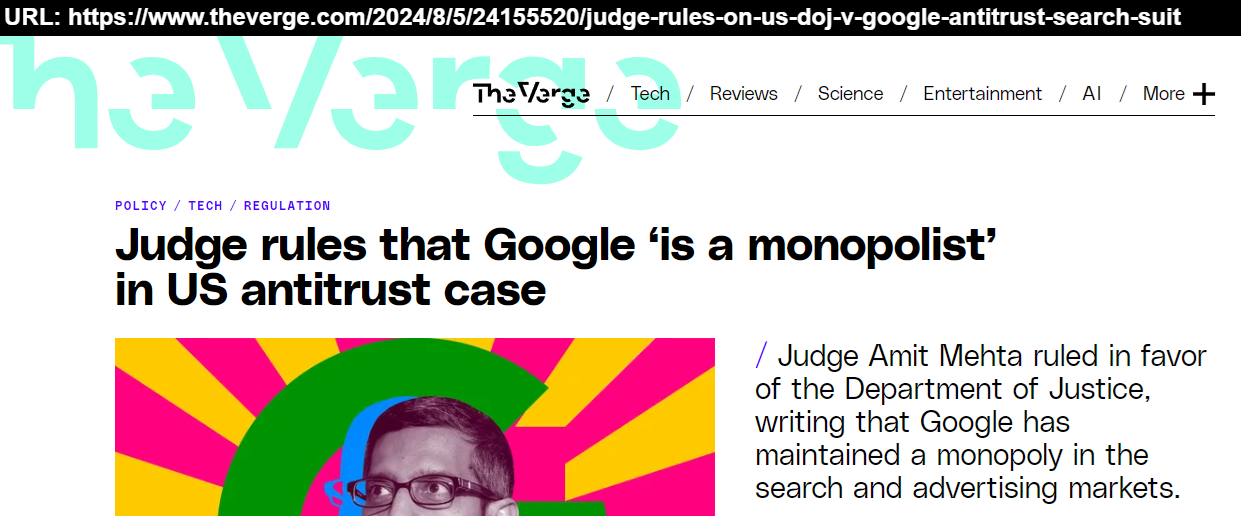
Tra gli elementi presunte "vittime del monopolio",dichiarate da The Verge (è abusivo anche il nome scelto:),esiste il Falso Engine DuckDuckGo,ed è sufficente solo vedere i loro Content ufficiali e si ha la demenza delle ricerca DuckDuckgo non puo essere fisicamente dominato,semplicemente perche' non è un Engine:)

Tra gli elementi presunti dominati,addirittura esiste anche Open AI,autoclassificata come Engine e anch'essa rientra "nel monopolio di Google" secondo il "Trust Tradizionale":)
In questa posizione,la collocazione di Open AI e di tutte le altre Artificial Intelligence,sono direttamente unite all'Holy Grail TFD Copyright.GOV,decisamente in opposizione al Dipartimento Giustizia USA,per una ragione molto semplice,unita all'operativita stessa delle AI ,perche' è difficilissimo che arrivino al copyright:) La vera operativita delle AI chiamata inpropriatamente addestramento,in realta' è formata da Scraping prima e Paraphrasing dopo e per conoscere queste posizioni,è indispensabile possedere delle Strutture Data Valide.


La posizione è quella di The Verge e il contesto del Super Bingo,esprime un Fatto Vero e Oggettivo e cioe' i Fact Check sono un Business anche loro,ovviamente a prescindere dai Fatti Veri,altrimenti The Verge non potrebbe proprio partecipare:)
La Casualita' ha voluto che esistesse proprio l'Holy Grail TFD Comcast,ed è anche l'Entity Data Juice e a differenza di The Verge,posso assicurare che è tutto vero e cioe' Comcast è arrivato grazie alla presenza dei codici Canonical,uniti a una curiosita' e cioe' l'elevatissimo numero presente dei codici Canonical stessi:)
La Casualita' ha voluto che esistesse proprio l'Holy Grail TFD Comcast,ed è anche l'Entity Data Juice e a differenza di The Verge,posso assicurare che è tutto vero e cioe' Comcast è arrivato grazie alla presenza dei codici Canonical,uniti a una curiosita' e cioe' l'elevatissimo numero presente dei codici Canonical stessi:)
Sono oltre 10K le pubblicazioni del dominio The Verge e il dato è anche parziale e mai prima avevo visto una presenza di codici Canonical cosi elevata (nemmeno Wikimedia ha mai osato tanto:) e la prima idea è stata quella di unirla a un altro elemento festeggiato nel Time Glory Data dell'anno meraviglioso 2019 e sono i Click Depth arrivati a OCT 24 2019,nelle stesse pubblicazioni dell'Inflate Data e dell'Holy Grail TFD Google patent:)
La ragione è stata anche molto semplice,perche' vedere tanti codici Canonical,uniti a Unnatural Links completi, in 1 solo dominio,è equivanente a "un cazzotto in un occhio":)
Appena ho visto questa posizione,è iniziato subito il Divertimento e l'Holy Grail TFD Comcast,Entity Data Juice,all'interno del dominio di The Verge,rappresenta una garanzia per il Divertimento e il motivo è nell'immagine sotto:)



Questa è IAB e cioe' il Vendors delle Ads di The Verge e la sua collocazione è nella Broken Experience e quindi esiste la reciprocita completa della pertinenza rispetto al Falso:)




Quello sistemato sopra è solo un esempio,rispetto ai contenuti effettivi del dominio "Poeti Tradotti" e spesso le Strutture Data non sono nemmeno Valide e quindi non esiste nemmeno la sicurezza che sia presente "Lo Scraping Totale Originale":)
Naturalmente è una posizione unita all'Assurdo dei Dati Falsi,perche' "L'originalita' dello Scraping" non Esiste,pero' l'operativita' effettiva del dominio è proprio quella descritta,perche' lo Scraping è sicuro al 100%,pero' non essendo presenti Strutture Data Valide,non esiste nemmeno la sicurezza che gli Scraping siano completi,alla prima operazione effettuata e quindi diventa normale anche l'Assurdita' rispetto alla presenza "dello Scraping Totale Originale":)
Quindi la terapia d'urto,rispetto alla consapevolezza dei Dati Falsi,è molto elevata,perche' peggiore sistemazione "dello Scraping Totale Originale" non esiste oggettivamente e per rendere la Terapia anche Divertente (rispetto a The Verge e ai suoi Dati Falsi Totali:) lo Scraping Totale Originale dei Poeti Tradotti,ha sistemato nel dominio anche lo SHOP e per rendere ridicoli i Dati Falsi completi di The Verge,ha unito il Plus del Divertimento e cioe' "lo Scraping Totale Originale",senza nemmeno avere Strutture data Valide,è unito alla Preoccupazione di violare il Copyright:)
Quella del dominio "dei Poeti Tradotti" è una terapia d'urto potentissima,rispetto alla consapevolezza dei Dati Falsi,ed è molto probabile che il Dipartimento di Giustizia USA,se Rinsavisse solo UN PO',andrebbe in "pellegrinaggio a piedi" a Mountan View California,nella sede dell'Holy Grail TFD Google e chiederebbe Scusa,solo per il Disturbo:)


La posizione è quella di AUG 2024 per le selezioni dell'anno 2020 e nel Link sopra è sistemata la pagina completa,ed è formata da 37 pubblicazioni coinvolte nei Match e i conflitti generali solo per l'anno 2020 sono arrivati a 155 pubblicazioni e il dato enorme,sopratutto se unito a 1 solo anno,pero' non è nemmeno completo,perche' tutte le pubblicazioni in Match hanno lo stesso Average e nel Caso specifico è formato da 5300 termini effettivi e cioe' piu' del doppio,rispetto alla potentissima terapia d'urto,creata dal dominio "dei Poeti Tradotti" per arrivare alla consapevolezza dei Dati Falsi e grazie a The Verge e al suo Falso Totale,è facile comprendere il valore dei dati appena sistemati e non sono nemmeno gli unici,perche' la Festa Vera è nei Dati sotto e sono uniti solo all'Engine Vero,proprio in senso operativo,ad iniziare dalla Logica delle Applicazioni:)

Sono state 39 le pubblicazioni selezionate dall'anno 2020
Sono state 177 le pubblicazioni in conflitto e l'Average di FGL SEP 2024 ha soli 2 termini (DUE:) in meno rispetto all'attuale Origin RF ONE di FGL FEB 2024 e a sua volta,sempre dall'anno 2020 ha avuto 209 pubblicazioni in Match,ed esistono solo 3 pubblicazioni in differenza e questi report dimostrano la pertinenza dei dati Veri,rispetto ai Veri Engines,semplicemente perche' senza conoscere tutto il Resto delle violazioni,sono sufficenti i Duplicati,per rendere NULLI tutti gli altri dati e quindi figurarsi che valore possono avere i Dati Falsi Tout Coure,simili a quelli di The Verge ,oppure quelli dei "Poeti Tradotti" o di NovelGuide e di Wiki Cebuana,perche' oltre alle impostazioni completamente senza senso ,esistono anche Content particolarmente scarsi e lo sono anche gli Average a cui sono applicati e avendo questo contesto,diventa inutile impegnarsi,per aggiungere altre violazioni,semplicemente perche' non esistono proprio i Content a cui unirle:) Solo per ricordare Search GPT,non esiste nessun reports in cui abbia raggiunto la violazione dei generative content ,semplicemente perche' i contenuti sono stati eliminati prima:)

Sono state coinvolte 27 pubblicazioni su 33 selezionate e i Match complessivi per l'anno 2019 a FGL JULY 2024 è formato da 116 Match e naturalmente l'Average è sempre lo stesso,ed è quasi il doppio rispetto "ai Poeti Tradotti" e circa 5 volte l'Average delle NovelGuide e di Wiki Cebuana,ed è possibile anche aggiungere "l'Extra Average" del dominio di The Verge,perche tra i tanti codici Canonical,lo strumento delle verifiche è riuscito a trovare delle pubblicazioni che non lo hanno e il suo Average è formato da 1259 termini effettivi e naturalmente non esiste nessun Main Content,perche' i presunti fact Check di The Verge sono applicati a qualsiasi categoria,senza conoscere assolutamente dove sono sistemati i contenuti originali e tantomeno conoscono le Proposte Complessive e con queste Credenziali,hanno la Preoccupazione di occuparsi dei Fact Check:)
Restando solo all'Average di The Verge,arrivato al 59% in unicita,ipotizzando che i contenuti siano anche quelli originali,perche' spesso sono assenti anche le Strutture Data Valide,l'Average delle differenze per 2 sole selezioni,è quasi 5 volte maggiore e sopratutto lo è il volume a cui sono applicati i dati e in questa posizione è possibile unire anche il Calculator degli Average stessi:

Restando al Calcolo degli Average le tante differenze delle selezioni,hanno prodotto anche il dato sopra e cioe' il volume a cui sono applicate le differenze,è 16,7 maggiore,rispetto al volume di The Verge e i dati esprimono solo il Calculator degli Average,per 1 sola selezione:)
Qui sono sistemate le selezioni di FGL AUG 2024 per l'anno 2019
Qui sono sistemate le selezioni di FGL AUG 2024 per l'anno 2019
Sono state 42 le pubblicazioni presenti.

Sono presenti 50 pubblicazioni esatte.


Questa è una posizione molto importante per evidenziare l'anno 2016,perche' le pubblicazioni presenti,sono assai maggiori rispetto a quelle selezionate e nelle verifiche è possibile che siano sistemate,anche i Post eliminati e questa posizione serve a ricordare che le selezioni sono assolutamente libere e possono facilmente cambiare i contenuti stessi e quindi le loro combinazioni,semplicemente perche' le pubblicazioni presenti sono assai maggiori,rispetto a quelle selezionate,pero' i reports restano sempre importanti,perche' attraverso i volumi sistemati,se i dati fossero negativi,non esisterebbe proprio nessun reports e non si avrebbe nessuna Demo Data:)



Questa è la posizione precedente dell'anno 2015,ed era APR 30 2024,ed è sistemata nella pubblicazione collegata sopra e questa posizione è importante perche' certifica che esistono tantissime possibilita di "avere combinazioni variabili" ad ogni selezione e quindi,non solo possono variare il numero delle pubblicazioni in Match,ma anche quelli dei contenuti,ed è facilissima la verifica dei reports rispetto ai Veri Engines,perche' avere pubblicazioni valide dall'anno 2015,all'interno di dimensioni colossali,certifica che il Content Creator è Validissimo,ed è il vero motivo per cui esistono reports fantastici:)


 Assente SEP 2024 Status Code 403
Assente SEP 2024 Status Code 403 IAB SEP 2024 145 PUB 51% UN 1770 AV 64 ILA FULL SIZE 174 KB Average(494 ms Average Loading)
IAB SEP 2024 145 PUB 51% UN 1770 AV 64 ILA FULL SIZE 174 KB Average(494 ms Average Loading) 171 PUB 28% UN 1353 AV 48 ILA FULL SIZE 212 KB Average(518 ms sono i millesimi di secondo per i Loading sempre in Average)
171 PUB 28% UN 1353 AV 48 ILA FULL SIZE 212 KB Average(518 ms sono i millesimi di secondo per i Loading sempre in Average)
 206 PUB 46% UN 629 AV 60 ILA FULL SIZE 87 KB (1177 ms Average Loading)
206 PUB 46% UN 629 AV 60 ILA FULL SIZE 87 KB (1177 ms Average Loading) Bertelsman SEP 2024 249 PUB 55% UN 828 AV 100 ILA FULL SIZE 53 KB (50 ms Average Loading)
Bertelsman SEP 2024 249 PUB 55% UN 828 AV 100 ILA FULL SIZE 53 KB (50 ms Average Loading) Computer World 249 PUB 63% UN 2544 AV 72 ILA 210 KB Average Full Size (304 AV Loading)
Computer World 249 PUB 63% UN 2544 AV 72 ILA 210 KB Average Full Size (304 AV Loading)


Wiktionary SEP 2024 244 PUB 65% UN 2170 AV 591 ILA 4175 Skipped e 4169 sono stati i Disallow.
Full SIZE 165 KB Average (618 ms Average Loading)
![]()

 Poeti Tradotti SEP 2024 190 PUB 77% UN 2507 AV 49 ILA Full SIZE 66 KB Average (163 ms AV Loading)
Poeti Tradotti SEP 2024 190 PUB 77% UN 2507 AV 49 ILA Full SIZE 66 KB Average (163 ms AV Loading)

 218 PUB 87% UN 569 AV 43 ILA FULL SIZE 16 KB AV (169 ms)
218 PUB 87% UN 569 AV 43 ILA FULL SIZE 16 KB AV (169 ms)



 250 PUB 26% UN 1846 AV 336 ILA Full Size 76 KB Average (789 ms AV Loading)
250 PUB 26% UN 1846 AV 336 ILA Full Size 76 KB Average (789 ms AV Loading)
 146 PUB 73% UN 1404 AV 78 ILA Full SIZE 36 KB (165 ms AV Loading)
146 PUB 73% UN 1404 AV 78 ILA Full SIZE 36 KB (165 ms AV Loading) SEP 2024 167 PUB 93% UN 5147 AV 47 Internal Link Average (ILA) Full SIZE 108 KB AV (331 ms AV Loading)
SEP 2024 167 PUB 93% UN 5147 AV 47 Internal Link Average (ILA) Full SIZE 108 KB AV (331 ms AV Loading)



 IONOS SEP 2024 237 PUB 49% UN 1792 AV 116 ILA 278 KB è l'Average del Peso in Full SIZE Loading AV 1054 ms
IONOS SEP 2024 237 PUB 49% UN 1792 AV 116 ILA 278 KB è l'Average del Peso in Full SIZE Loading AV 1054 ms

SEP 2024 232 PUB 45% UN 1576 AV 224 Internal Links Average (ILA) Full SIZE 387 KB in Average (649 ms AV Loading)
1787 Skipped e 1767 sono i suoi Disallow
 Advance Web Ranking 248 PUB 78% UN 1714 AV 30 ILA FULL SIZE 663 KB AV (434 ms AV Loading)
Advance Web Ranking 248 PUB 78% UN 1714 AV 30 ILA FULL SIZE 663 KB AV (434 ms AV Loading) Web FX 243 PUB 67% UN 4117 AV 176 ILA Full SIZE 1017 KB AV (260 ms AV Loading)
Web FX 243 PUB 67% UN 4117 AV 176 ILA Full SIZE 1017 KB AV (260 ms AV Loading)
 227 PUB 66% UN 3637 AV 80 Internal Link Average (ILA) Full SIZE 342 KB (288 ms AV Loading)
227 PUB 66% UN 3637 AV 80 Internal Link Average (ILA) Full SIZE 342 KB (288 ms AV Loading) Investopedia 244 PUB 66% UN 2713 AV 168 ILA FULL SIZE 424 KB AV (318 ms AV Loading)
Investopedia 244 PUB 66% UN 2713 AV 168 ILA FULL SIZE 424 KB AV (318 ms AV Loading) 179 PUB 71% UN 2106 AV 69 ILA Full SIZE 83 KB AV (3148 ms è l'Average del Loading)
179 PUB 71% UN 2106 AV 69 ILA Full SIZE 83 KB AV (3148 ms è l'Average del Loading) SEP 2024 246 PUB 40% UN 9251 AV 266 ILA FULL SIZE 830 KB (2037 ms AV Loading)
SEP 2024 246 PUB 40% UN 9251 AV 266 ILA FULL SIZE 830 KB (2037 ms AV Loading)

 79 PUB 78% UN 704 AV 35 ILA FULL SIZE 135 KB AV (148 ms AV Loading)
79 PUB 78% UN 704 AV 35 ILA FULL SIZE 135 KB AV (148 ms AV Loading) 





















 SEP 2024 249 PUB 65% UN 1963 AV 132 ILA Full SIZE 318 KB (494 ms AVL)
SEP 2024 249 PUB 65% UN 1963 AV 132 ILA Full SIZE 318 KB (494 ms AVL)



SEP 2024 211 PUB 96% UN 5697 AV 27 ILA Full SIZE 109 KB AV (389 ms AVL)
 230 PUB 84% UN 2317 AV 11 ILA Full SIZE 111 KB AV (682 ms AVL)
230 PUB 84% UN 2317 AV 11 ILA Full SIZE 111 KB AV (682 ms AVL)
 240 PUB 73% UN 854 AV 37 ILA Full SIZE 110 KB AV (97 ms AVL)
240 PUB 73% UN 854 AV 37 ILA Full SIZE 110 KB AV (97 ms AVL)

 238 PUB 53% UN 795 AV 56 ILA Full Size 121 KB (488 ms AVL)
238 PUB 53% UN 795 AV 56 ILA Full Size 121 KB (488 ms AVL) SEP 2024 238 PUB 65% UN 1337 AV 46 ILA (Internal Links Average) Full SIZE 130 KB AV (182 ms AVL)
SEP 2024 238 PUB 65% UN 1337 AV 46 ILA (Internal Links Average) Full SIZE 130 KB AV (182 ms AVL)



 Time Magazine 172 PUB 67% UN 1837 AV 84 ILA Full SIZE 270 KB AV (412 ms AVL)
Time Magazine 172 PUB 67% UN 1837 AV 84 ILA Full SIZE 270 KB AV (412 ms AVL)


 SEC GOV 208 PUB 88% UN 5274 AV 68 ILA Full SIZE 144 KB AV (252 ms AVL)
SEC GOV 208 PUB 88% UN 5274 AV 68 ILA Full SIZE 144 KB AV (252 ms AVL) SEP 2024 217 PUB 93% UN 8347 AV 93 ILA Full SIZE 135 KB Average (510 ms AVL)
SEP 2024 217 PUB 93% UN 8347 AV 93 ILA Full SIZE 135 KB Average (510 ms AVL)
SEP 2024 243 PUB 99% UN 14143 AV 66 ILA 115 KB Full Size Average (992 ms AVL)