




I dati diretti saranno presenti tra un po',perche' è indispensabile sistemare tante altre unioni per arrivare al report sopra e in questa posizione ho scelto di evidenziare solo 2 "Dettagli Curiosi":)


Gli Accettabili Fail Rate hanno l'unione diretta con l'immagine delle Data Priority e da sola è capace di rendere pertinente l'Egregious Violation Super Partes,ed è quella della LOGICA e per renderla oggettiva è sufficente citare la 2° Curiosita,unita agli "Accettabili Fail Rate" rispetto agli Errori dei "Robots txt;DNS;Server",ed è la posizione stessa in cui sono sistemati,ed è quella del FETCH:)

Esistono tante unioni possibili,per rendere semplice la posizione degli elementi delle Data Priority e l'unica difficolta' oggettiva è quella di sistemare tutte le unioni,perche' ne sono realmente tante:)

Inizio dall'unione diretta dei SIZE,attraverso il Logical Clicks Demonstrate Spam Brain e la posizione sara' utilissima tra un po',perche' esisteranno proprio i SIZE uniti "all'Accettabile Fail Rate",all'interno del contesto dei FETCH e la posizione sara' molto Divertente,perche' grazie alla presenza dei Size, diventera' palese il fatto che l'elemento piu' importante non è la Risposta dei Servers unita a "loro eventuali errori" (è l'Accettabile Fail Rate:) ma è l'Esistenza stessa della Domanda,rispetto a contenuti da sistemare negli Index:)
I Size rendono molto semplice comprendere le Differenze,ed è sufficente l'immagine del Configure HTML Javascript per comprenderlo,insieme alle descrizioni del Logical Clicks Demonstrate Spam Brain collegato sopra.
La sezione piu' importante,rispetto ai Size,è quella evidenziata,perche' è la posizione che contiene i Content Effettivi e sono loro a formare i Size reali,mentre tutte le altre posizioni sono escluse e sono formate solo da codici.


Nella posizione del Logical Clicks Demonstrate Spam Brain,esistono vari esempi uniti ai codici e tutti appartengono al Configure dell'HTML Javascript e cioe' non fanno parte dei SIZE sistemati sopra e formano le Page Size e l'importanza è unita solo al Loading,in senso molto relativo,perche' è indispensabile prima Arrivarci alla sua Verifica e unendo tutta l'Esperienza,non ricordo nessun Match,in cui il Loading sia stato Decisivo:)
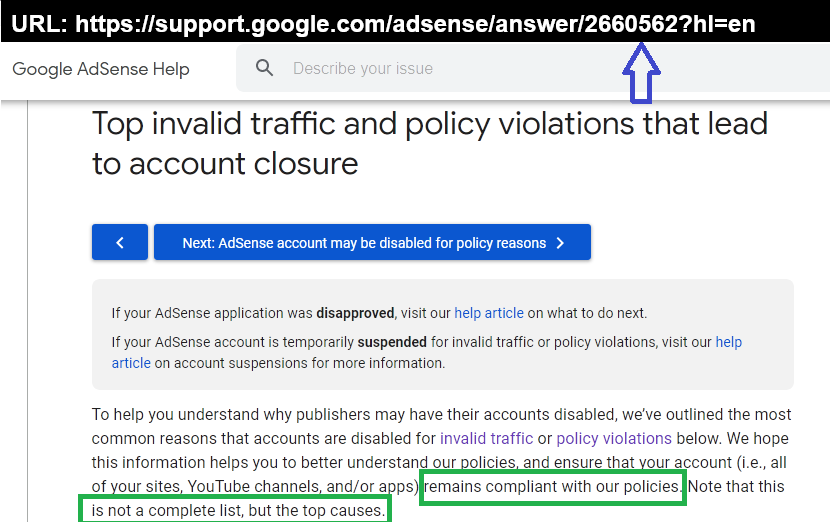
A OCT 2023 e cioe' 1 anno fa' esatto,queste erano le descrizioni sull'Invalid Traffic e non sono cambiate,pero' sono aumentate le Penalita' e quindi è ancora piu' semplice arrivare agli Invalid Traffic e se non dovessero esistere violazioni,restano sempre i SIZE a rendere possibile l'arrivo all'Invalid Traffic,grazie alla maggiore probabilita' di avere Duplicati:)



Le posizioni descritte rappresentano solo alcune delle unioni,rispetto agli elementi delle Data Priority e anche il Contesto Teorico,unito alle Top Cause dell'Invalid Traffic, è presente nei collegamenti sistemati sopra,grazie alle posizioni generali del Don'T DECEIVE:)

A unire il contesto effettivo delle operazioni alternative ai Dati Veri,esiste il Report At a Glance,ed è facile comprendere quanto sia Affidabile,semplicemente perche' non esiste nessun dubbio,rispetto all'operativita' effettiva degli Alternativi alla Priorita' dei Dati (sono esclusivamente quelli Veri:),ed è quello di Decidere gli Users e sopratutto il Business e quindi diventa pertinente anche il nome scelto per questa Data Priority,perche' è implicita l'Egregious Violation Super Partes,ed è quella della Logica e cioe' gli autori e operatori alternativi,non sono Credibili,nemmeno nel ruolo d'Idioti:)
E' sufficente solo immaginare l'unione dei contenuti di 1 anno fa' (OCT 2023 collegato sopra) delle Top Cause dell'Invalid Traffic e sempre attraverso la Fantasia,unire anche il Report at a Glance,insieme alla sua particolare posizione,semplicemente perche' è anche la prima del Webmaster Topic e quindi svanisce anche la Credibility rispetto all'Idiozia degli operatori e resta solo il fatto che sono Altamente Inaffidabili e quindi è sufficente solo la loro presenza per attivare il Report at a Glance e da questa pubblicazione,è possibile unire anche le Egregious Violation Super Partes della Logica,perche' è assente anche la Credibility,anche rispetto all'Idiozia degli operatori:)


La posizione del Discover Content è importante anche in questo contesto,perche' tra un po' sara' la protagonista diretta,rispetto agli "Accettabili Fail Rate",semplicemente perche' all'interno dei SIZE,saranno presenti anche i Discover.
Grazie al Site Reputation Abuse,è possibile anche attualizzare le Top Cause dell'Invalid Traffic di 1 anno fa',perche' rende molto semplice distinguere i Valori Reali,rispetto alle posizioni Teoriche,ed è sufficente solo immaginare il percorso per arrivare al Third Party e si ha immediatamente l'attualizzazione delle Top Cause dell'Invalid Traffic,semplicemente perche' arrivano prima i Duplicati e la loro presenza "per paradosso non è Irrilevante" (circa il 50% rispetto ai contenuti di tutto il Web) e dopo di loro esistono le Spam Policies e se dovessero essere "superati gli ostacoli" è possibile anche arrivare al Site Reputation Abuse e cioe' al Third Party e la collocazione specifica è solo il Discover e significa semplicemente che i Match possono iniziare e poi occorre anche Vincerli e solo al termine è possibile avere l'Original;Unique e Content Value e cioe' i Valori Reali e lo stesso percorso "dovrebbero farlo le posizioni Teoriche" e sono i Generative Traffic;il Manipulated Ads,solo per citare le presenze sistemate in questa pubblicazione (altre sono a OCT 2023 collegato sopra) e poi è possibile aggiungere anche "le Grandi Preoccupazioni" degli operatori alternativi,uniti ai Clicks o alle Impression e di recente,hanno anche "la Grande Preoccupazione" dell'Esperienza degli Utenti:)
Sarebbero tutte posizioni legittime e l'unico problema è la Loro Applicazione,perche' è indispensabile prima Arrivare a possedere "le Grandi Preoccupazioni",ed è sufficente solo unire le Top Cause dell'Invalid Traffic di 1 anno fa',al Site Reputation Abuse attuale e la prima Preoccupazione Vera,diventa quella di superare il Discover e per gli operatori alternativi ai Dati Veri,insieme "ai poveri utenti che li pagano",diventa una Good News,solo il Fatto di Arrivare al Third Party,perche' solo immaginare l'Applicazione degli elementi Teorici sistemati sopra (Generative Traffic;Manipulated;le Grandi Preoccupazioni ETC),significa che lo Spam nel loro Brain è arrivato al Top e non esiste nemmeno 1 Neurone Valido,da poter eventualmente unire alla Fantasia dei Dati:) Non è una battuta perche' esiste realmente,ed è il Self Serving Data,ed è unito "alla Fantasia delle Revisioni" e cioe' deve esistere un autore con Brain completamente in Spam,capace di fare tutto il percorso,iniziando dai Discover;vincere tutti i Match e alla fine,grazie al Self Serving Data (deve possedere Unique;Original e Content Value LUI stesso:) scrive le Revisioni per dare vantaggi ad altri domini e possono appartenere solo alla stessa categoria "dell'Astuto Revisore" e l'unica cosa sensata del contesto,è unita solo all'Egregious Violation Super Partes della Logica,perche' non è Credibile nemmeno l'Idiozia operativa degli autori stessi e quindi diventa una Good News,anche l'arrivo al Site Reputation Abuse del Third Party,sistemato nei Discover e cioe' al Vero Motivo,unito alle contestazioni per le posizioni dominanti di Google:)
Sono sempre esistite le contestazioni unite al Trust contro Google,pero' da MAY 2024 sono "aumentate in maniera vertiginosa" e non è Casuale il fatto,che "Esista la Coincidenza",rispetto all'arrivo del Site Reputation Abuse e cioe' la "Vera Operativita" degli Alternate Service,insieme ai loro utenti:)
Immaginano che la Violazione del Trust tradizionale "sia il tallone d'Achille" dell'Holy Grail TFD Google e tra i Fantasiosi Operatori Alternativi ai Dati Veri,è possibile sistemare tutti gli elementi presenti nelle Data Priority,perche' fanno esattamente le stesse operazioni:)

L'Egregious Violation Super Partes della Logica,rispetto agli elementi delle Data Priority,possiede anche 1 Plus particolarmente Divertente,perche' è difficilissima la ricerca "di Idioti in Proprio",in quanto,quasi sempre,sono presenti Idioti anche "per conto terzi" e cioe' gli elementi delle Data Priority,attivano il Divertimento Top,ed è quello del Third Party Idiots:)


Questo è solo un esempio,rispetto all'unione tra gli elementi delle Data Priority e i Social Media e la posizione è molto diffusa,non per un importanza oggettiva,ma per la semplice ragione che i Social Media,attivano il Third Party Idiots e quindi gli elementi delle Data Priority,si "sentono a loro agio",perche' non esiste nessuna necessita' di avere il DEMONSTRATE Opposto,ed è quello della Natural Intelligence:)


Questo è il riferimento del dominio "Open Online" del simpatico Enrico Mentana,decisamente AVULSO dal contesto online e probabilmente non è nemmeno consapevole,della posizione in cui si trova,grazie al fatto che ha operato sempre nel contesto tradizionale della comunicazione e quindi i Social Media sono gli elementi piu' Affini,rispetto all'Esperienza professionale,unita solo al Falso:)
E' Divertente anche la posizione oggettiva dei Social Media,perche' tra i tanti termini possibili da scegliere e da unire ai loro Fact Check,hanno scelto proprio i termini del Third Party e il riferimento è Poynter e quindi l'unica cosa Vera è il Falso, perche' anche Poynter è completamente Avulso dal contesto online,grazie al Percorso stesso per Arrivare ai Fact Check e inizia dai Discover e al loro interno esiste il Third Party e occorre ricordare che è una Spam Policies essa stessa,insieme a tantissime altre presenze e prima di LORO Arrivano i Duplicati e se l'esito fosse positivo,occorre attraversare tutto il Webmaster Topic e solo al termine esistono i Fact Check nel contesto online:)
Quindi la simpatica Open Online,creata dal simpatico Enrico Mentana,per operare nel contesto online,debbono prima avere Consapevolezza della posizione in cui operano,ed è infinitamente molto piu' difficile,rispetto al contesto tradizionale a cui è abituato il simpatico Enrico Mentana e per avere qualche speranza di arrivare alla Consapevolezza minima,la migliore operazione è quella di eliminare i Social Media,sopratutto per un dominio che si occupa di Fact Check,perche' attraverso la loro presenza, il percorso descritto sopra,solo per arrivare ai Fact Check,diventa impossibile anche applicando la Fantasia al Percorso stesso,perche' le probabilita maggiori,sono quelle di fermarsi al Third Party e non è facile nemmeno raggiungerlo,sopratutto per i Social Media:) E' la Good News sistemata nella precedente pubblicazione e cioe' la buona notizia è quella dei Social Media,arrivati addirittura al Third Party,perche' i Duplicati arrivano prima,ipotizzando che la Struttura Data sia anche Valida e dopo di loro arrivano le Spam Policies (DUE Violation per l'intero dominio sono consentite) e tra di esse è presente anche il Third Party:)
Quindi il simpatico Enrico Mentana e il simpatico dominio di Open Online,debbono fare un lungo percorso anche rispetto alla Consapevolezza della posizione in cui si trovano,sopratutto per un dominio che immagina di occuparsi di Fact Check nel contesto online,perche' l'operazione è difficilissima e nello stesso tempo è Molto Precaria e puo cambiare ad ogni Match,semplicemente perche' esistono anche i Thin Content e grazie alla loro presenza,i dati terminano per sempre e non sara' mai piu' possibile arrivare ai Fact Check.


https://dinpoststory.blogspot.com/2021/10/natural-contest-true-data-priority.html
E' una Data Priority ad avere la Migliore Comprensione di Tutti i Tempi,ed è la stessa pubblicazione a contenere "l'Accademia dei Social media sistemata sopra",insieme ai PPC di Amazon (tutti in Dofollow solo per fare Schemes:),insieme a tanti altri Fact Check,compreso quello sotto:)
 E' la descrizione dell'Eleggibilita' unita ai Fact Check e non è possibile in nessun modo trovarli prima della data indicata sotto:)
E' la descrizione dell'Eleggibilita' unita ai Fact Check e non è possibile in nessun modo trovarli prima della data indicata sotto:)
E' una Data Priority ad avere la Migliore Comprensione di Tutti i Tempi,ed è la stessa pubblicazione a contenere "l'Accademia dei Social media sistemata sopra",insieme ai PPC di Amazon (tutti in Dofollow solo per fare Schemes:),insieme a tanti altri Fact Check,compreso quello sotto:)

Appena ho visto quest'unione,sono "esploso di felicita",perche' il contesto è capace da solo di verificare qualsiasi report,ed è sufficente solo unirlo a tutte le operazioni citate,iniziando dai Discover, fino ad Arrivare ai Fact Check stessi,ed è facile intuire quanto sia difficile il percorso,sopratutto quando sono presenti dei Multi fact Check e in questa posizione è sufficente solo ricordare la Descrizione sistemata sopra:
se dovesse esistere 1 solo Fatto Non Vero,la pubblicazione puo essere Eliggibile,pero' tutti gli altri eventuali Fact Check presenti debbono essere Veri,altrimenti diventa Ineleggibile anche il primo Fact Check trovato e quindi anche la pubblicazione che lo contiene e per arrivare alle Several Pages Claim Review,occorre "pochissimo impegno",perche' il primo Fact Check trovato NON VERO,non puo essere ripetuto in nessun altra pubblicazione dello stesso dominio.
Questa è solo la descrizione dei Fact Check oggettivi e poi occorre unire anche il percorso per ARRIVARCI,partendo dai Discover e iniziando subito dai Duplicati e poi si passa alle Spam Policies,Third Party compreso e prima di arrivare ai Fact Check,occorre attraversare tutti i Webmaster Topic e quindi il simpatico Enrico Mentana,insieme al simpatico dominio di "Open Online" dovranno fare un percorso lunghissimo,prima di arrivare alla consapevolezza del contesto in cui si trovano e per gli altri elementi delle Data Priority,il percorso è esattamente uguale:)
 https://dinpoststory.blogspot.com/2024/10/good-news-report-at-glance-fgl-oct-2024.html
https://dinpoststory.blogspot.com/2024/10/good-news-report-at-glance-fgl-oct-2024.html
La posizione descritta fino a questo punto,è assolutamente reale,rispetto agli elementi delle Data Priority (il simpatico dominio di Open Online è solo un esempio,rispetto alle altre presenze:) per conoscere il percorso per arrivare ai Dati Veri:)
La posizione descritta fino a questo punto,è assolutamente reale,rispetto agli elementi delle Data Priority (il simpatico dominio di Open Online è solo un esempio,rispetto alle altre presenze:) per conoscere il percorso per arrivare ai Dati Veri:)
Esiste poi la posizione sopra,appena sistemata nella precedente pubblicazione e a parte i suoi contenuti oggettivi,la sezione piu' importante è formata dai termini scritti sotto all'immagine:)



Questa è la data esatta della pubblicazione precedente,ed è OCT 8 2024 e la sua importanza è nell'immagine sotto:)


Per comprendere il livello di Spam nel Brain "degli innocenti autori" uniti al Third Party,non occorre utilizzare le Policies specifiche,perche' esiste il Report diretto At A Glance,ed è quello del Webmaster Topic:)


Questa è la sezione del Manual Action,all'interno del Webmaster Topic,ed è la posizione unita al Third Party,attraverso il Site Reputation Abuse,ed è sufficente solo "vedere la pessima compagnia" per avere immediatamente il Report at a Glance,perche' è gia' un impresa arrivare al Third Party,perche' le probabilita' maggiori sono quelle di essere eliminati prima e visti gli Average di tanti operatori alternativi,la Chance Maggiore è quella che arrivi prima il Thin Content,rispetto a qualsiasi altra violazione:)

Solo la Fantasia Infinita del Supreme Case Creator era capace di creare tutte queste unioni,perche' anche il Circumventing System Policies è presente nella pubblicazione precedente,unita "al cambio di marcia" rispetto alla facilita' di arrivare alle Egregious Violation e la posizione sopra è la prima Grave Violazione,naturalmente ipotizzando che i contenuti non sono eliminati prima:)





In Logical Clicks Demonstrate Spam Brain esistono degli esempi uniti al Configure HTML Javascript e aiutano molto a comprendere la Rilevanza del Quality Score e rendere semplice distinguere qualsiasi Dato:)
L'esempio dei codici è sistemato anche sopra e sara' molto utile tra un po' per avere un altra verifica del Quality Score e sara' quella dell'Accettabile Fail Rate:)
In questa posizione,i codici sono utili per evidenziare le differenze tra gli Average dei Content e quelli dei SIZE,ed è formata dalla posizione sotto:)

L'evidenza di colore blu contiene i SIZE dei Content Effettivi e tutte le altre posizioni HTML Javascript sono escluse dai Pesi,compreso il codice dell'Holy Grail TFD Statcounter.
Quindi se esistono problemi nell'evidenza di Colore Blu (I Content Effettivi),qualsiasi altra posizione sistemata nei codici HTML Javascript non hanno nessun Valore,mentre in Teoria,se dovessero esistere Content Validi nell'evidenza di colore Blu,vengono viste anche le posizioni HTML Javascript,perche' le "Idee Alternative",solo per arrivare ai Dati Falsi,sono al loro interno e il contesto è solo Teorico perche,da Sempre,rappresenta solo un Egregious Violation Super Partes della Logica,ad iniziare dal Brain oggettivo degli autori e dei loro ottimizzatori,perche' solo immaginare di applicare le "Idee Alternative" (sono una Frode in realta':) significa avere il proprio Brain completamente occupato da Spam e nell'immagine sopra è facilissimo evidenziarlo,perche' il percorso dall'evidenza di colore blu (sono i Size dei content effettivi) verso i codici HTML Javascript è possibile farlo,mentre il percorso opposto non ha nessuna possibilita' di essere realizzato e la posizione è importantissima,perche' nell'evidenza di colore blu esistono le Proposte Complessive e solo loro determinano il Page Quality Rating e cioe' i Dati Veri:)





Sarebbero tante le cose da sistemare solo per i domini presenti sopra e in questa posizione ricordo solo i contenuti di MAR 2024,uniti proprio a SNS e da soli sono capaci anche di comprendere quello che hanno fatto realmente gli operatori nel loro dominio specifico:) (l'esempio è SNS e ufficialmente sarebbe il primo High learning italiano,pero' il Top del contesto tradizionale,non possiede nessun DEMONSTRATE e grazie ai contenuti di MAR 2024 (cioe' quello che hanno scritto realmente gli autori di SNS:) è facile comprendere anche i dati attuali e il contesto è quello descritto per il simpatico dominio di Open Online e cioe' non hanno proprio consapevolezza del contesto in cui si trovano e viste le operazioni che fanno,è facile comprendere il contesto da cui derivano ed è quello tradizionale,operativo attraverso 1 solo Elemento,ed è L'IGNORE Totale,ed è sufficente vedere le operazioni compiute e gli Average effettivi dei contenuti che hanno e si ha la Logica dei dati:)

Altre posizioni saranno nelle prossime pubblicazioni,rispetto ai domini che hanno partecipato alla selezione delle Data Priority e in questo contesto sistemo una curiosita' fantastica,direttamente unita proprio agli elementi delle Data Priority,perche' il primo dato verificato è quello di un elevata inconsapevolezza e allo stesso livello "è presente un ossessione per le AI",altrettanto inconsapevole,perche' l'obiettivo reale è arrivare alle Primarie Purpose (è nell'evidenza di colore blu sistemata sopra e cioe' i SIZE dei Content Effettivi:) altrimenti non avrebbe nessun senso investire risorse economiche:)

Sempre nel Gold Star Fantastico della 9D degli RF ,di MAR 2024,oltre alla Futura Third Party (sarebbe diventata operativa quasi 2 mesi dopo) è presente anche l'Holy Grail TFD Statcounter,ed è diventato tale proprio in quella pubblicazione,attraverso l'immagine sistemata sopra e anch'essa è arrivata nel Time Glory Data dell'anno 2019,ed è straordinaria da sistemare anche in questa posizione,perche' le OFF Pages,esprimono la sintesi effettiva anche del Site Reputation Abuse,semplicemente perche' fanno lo stesso inutile percorso e cioe' dai codici HTML Javascript (quelli sistemati sono proprio di Statcounter ed è presente anche il codice del project) immaginano di poter arrivare ai Size dei Content Effettivi:)


Rendono molto semplice comprendere quanto è facile essere negli Unrelated e nel contesto online,la posizione dei Main Content (sono formati dai periodi Related rispetto al proprio Focus) è la piu' importante in assoluto,semplicemente perche' i contenuti non possono essere scritti da "Tuttologi" e la differenza è notevolissima,semplicemente perche' avere il maggior numero di periodi Related,rende anche piu' elevata la possibilita' di avere Match e di eliminare i contenuti stessi.










Quindi per gli URL Match,l'unica cosa Vera è unita al Fatto che Esistono e anche loro hanno l'Esclude dai Dati,sempre per i rilevamenti di base.






Il Link potrebbe essere quello sopra,perche' l'immagine di grande dimensioni è sistemata in un altro dominio.











Nella posizione sono comprese anche le altre presenze dei Projects,perche' il Gold Star è presente anche su AV,pero' non esiste lo stesso nessun Links:)
Qui è sistemata la posizione opposta
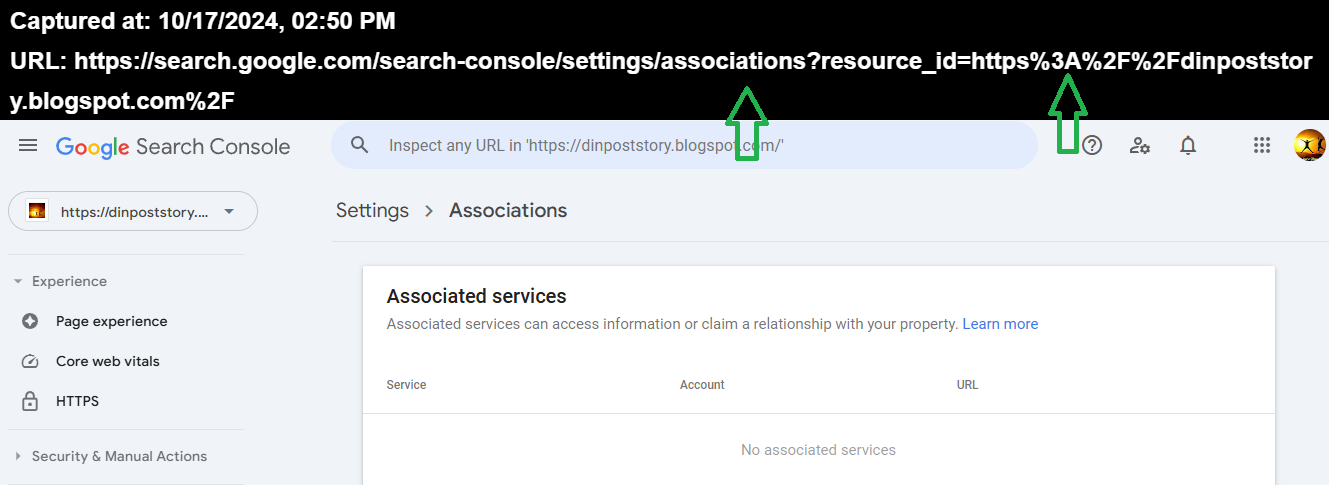
E' sempre il Gold Star e la posizione sopra contiene i Backlinks da Any Site e al suo interno,esistono anche le tante altre Sister Site non presenti nei Projects,mentre nel collegamento appena sistemato sono presenti i Links dei domini uniti ai Projects e non è presente nessuno:)












Adesso possono intervenire i contenuti del 78° RF descritti all'inizio di questa pubblicazione e il riferimento è il peso esatto del dominio a MAR 31 2018:)

Nel 87° RF esistono altre descrizioni e l'unione è quella sotto:





Questo è solo un esempio per essere in High Fail rispetto all'Accettabilita' nel tempo di risposta dei server e l'arco temporale di riferimento è solo 1 settimana e visto l'elemento protagonista,difficilmente il Server avra' la Domanda,se le pubblicazioni possono essere in Index:)






E' la Festa dei Content Effettivi e dal Webmaster Topic arriva anche la posizione del Manual Action e gli elementi presenti sono tutti importanti,pero' grazie ai SIZE sistemati sopra,la posizione piu' incredibile è quella dei Thin Content,perche' il riferimento dei SIZE diretto,nei recenti 90 giorni dalla data dell'URL sistemato sopra è formato da 11,4 MB ed è inserito all'interno di un dominio che possiede circa 55 MB nei suoi SIZE (il riferimento è sempre l'evidenza di colore blu sistemata sopra e cioe' quella dei Content Effettivi:) e avere il NO ISSUES DETECT per la Manual Action e quindi anche per il Webmaster Topic,attraverso gli elementi che contiene e il riferimento principale,in questo Caso è al Thin Content,forma un contesto da Heroic DC:)