



La descrizione dell'immagine è in OCT 2020 ,ed esistono altre sue sezioni ,per avere i content completi e in questa posizione,cito solo la data,dell'immagine stessa ,ed è Nov 23 2016:)
Ovviamente,se è presente il report sopra,significa che gia' esisteva anche la pubblicazione e a OCT 2020,ha fornito una fantastica testimonianza ,per gli archi temporali delle Sitemap,perche' gia' esistevano nel 2016 e di conseguenza,il valore dei dati di tutti gli RF e dei Just Time,sono "oltre le stelle":)
Lo sono realmente e la prima evidenza è il contesto stesso da cui derivano i dati,ed è il Frame Global Limit e solo per citare un suo elemento,è sufficente sistemare il Taken Din Colors Five e l'unione di 4 anni delle Sitemap,rende i dati degli RF e dei Just Time,ESPONENZIALI:)
In questo Caso la verifica è la piu' semplice,perche' è sufficente che le pubblicazioni esistano e con il Taken Din Colors Five (sono le dimensioni del dominio) unito alle Sitemap,le probabilita' che possa accadere,sono molto poche!:)
Nella pagina A sistemero' altri dati,mentre in questa posizione ci saranno i "contesti tecnici delle pubblicazioni" e per la prima volta negli RF,ne sono 2:
Il link per esteso,permette di confrontarlo con quello del 2016 e la presenza di 2 pubblicazioni,deriva dal fatto che i contenuti uniti al link,sono in realta' 1 Plus di un altra pubblicazione e naturalmente hanno "lo stesso contesto" e la casualita',dopo 4 anni, hanno reso i contenuti delle 2 pubblicazioni,Meravigliosi!:)


La meraviglia è nel primo collegamento ,ed è la pagina originale del Plus e letti gli altri termini,si comprende facilmente a cosa sono dedicati i contenuti:)
Sono tornate dopo 4 anni le pubblicazioni,in maniera del tutto casuale e i motivi sono descritti a OCT 2020 e in questa posizione ,posso solo citare il fatto che non mi ricordavo nemmeno che esistesse un account dello strumento in cui erano conservate "solo 15 pubblicazioni" e dai pochi termini esposti,non mi ricordavo assolutamente cosa contenessero:)


Prima di sistemare i contenuti diretti,ho inserito il "Contesto del NoSense":)
Sono "delle posizioni ufficiali di Alexa" per "determinare i valori del contesto online" e sarebbe davvero divertentissimo,se Alexa diventasse un Engine:) (con le posizioni sopra e le precedenti,l'unica curiosita' è il tempo necessario per arrivare al fallimento:)

Posso assicurare che solo "la Casualita'" è la vera Autrice di queste unioni:)
E' proprio la Quality di Bing,ad essere unita alle 2 pubblicazioni del 2016 e al loro interno esiste anche il collegamento per le sue Guidelines:)
E' fantastica anche l'evidenza della Sitemap,perche' è proprio nella prima posizione per Bing e la collocazione è nata,grazie ai contenuti descritti in OCT 2020 e sono arrivati,da Nov 2016,proprio per le Sitemap:)
Sono proprio specifiche,per evidenziare la demenza dei rapporti tra i links DoFollow e NoFollow di Alexa e poi esistono le pubblicazioni originali del 2016 e i suoi contenuti,sono attualissimi,ed è sufficente compararli con l'immagine di Alexa,compresa la precedente sistemata nel primo Just Time K2:).
Per Bing esiste poi una novita' molto importante,ed è la recente unione del logo della sua Casa Madre.
Il Powered della Microsoft è sempre esistito e i suoi dati sono in tantissimi altri Engines e l'importanza deriva dal fatto,che esistono dati complessivi e quindi diventa molto facile comprendere quanto sia elevata l'importanza delle Guidelines di Google,semplicemente perche' sono identiche al Powered della Microsoft (Bing e tutti gli altri Engines uniti) ,ed "esiste solo la differenza del 90% " nel Market Share:)
L'aspetto fantastico delle Guidelines Microsoft ,deriva dal fatto che i suoi contenuti sono diretti,senza "nessun giro di parole" e molto probabilmente,se descrivesse i contenuti di Alexa,utilizzerebbe gli stessi termini appena sistemati:) (Alexa è puro Non Sense,insieme ai suoi "amichetti seo":)


E' possibile selezionare solo un espansione e naturalmente ho scelto "Content Exploration di Alexa" ,ed è molto facile creare le unioni con le Guidelines di Microsoft Bing:) (non esiste nessuna forma di prevenzione ,perche' la realta' dei social è solo links scheme,ammesso poi che esistano dei contenuti e che siano "anche naturali":)


La loro attualizzazione è nei "Deprecated Intent" ,ed è nata proprio da Microsoft Bing eilriferimento sono i Like Farms o social schemes (DEPRECATED definiti da Bing,mentre per Alexa rappresentano i Content Exploration:)))
Tutte le posizioni dei Brain Stone sono unite al "Pricing dei servizi" e questo metodo,rende semplice l'evidenza dell'idiozia ,da parte dei fruitori del servizio stesso:)
Sono posizioni unite anche alla semplice logica,perche' se fosse cosi' semplice avere valore nei dati,non solo esisterebbero solo i Top Friend Din (i principali schemi derivano dal Nuyng o Selling dei links e cioe' vengono proprio acquistati e nelle categorie online ,la prima indiziata a seguire questo metodo" è la categoria Travel:)
Per quanto riguarda Alexa,esiste un esempio anche migliore per i valori dei dati,ed è fornito dalla sua Casa Madre:)
(se avesse possibilita' economiche nelle riceche,lascerebbe volentieri i pacchi da spedire e se esistesse qualche idiota disposto ad acquistare Alexa,è probabile che Amazon sarebbe felice:)
Sono proprio i "Deprecated Intent" nei Brain Stone e posizioni simili ad Alexa ne esistono tantissime e queste collocazioni sono molto utili per comprendere dacosa derivano i valori reali dei dati:)
(non occorrono nemmeno dati tecnici,perche' è sufficente il Buon Senso:)
Anche questa pubblicazione appartiene ai Brain Stone,ed è possibile unirla al termine "Pricing" ,attraverso le "Difficulty Keywords" .
Il senso è molto semplice ,ed è descritto anche nella pubblicazione collegata,ed è sufficente aggiungere solo i termini piu' noti,rispetto "alle difficolta' dei termini",ed è Keywords Stuffing e sono i conflitti all'interno della stessa pubblicazione,tra i termini che la compongono,ed è un aspetto importante,pero' occorre considerare anche le altre pubblicazioni presenti,in ogni dominio e spesso ne sono centinaia:)
Fanno parte del "pricing di Alexa" (anche di Semrush e di tantissimi altri:) e le "difficolta' dei termini",sono in realta' secondarie,rispetto alla presenza stessa dei Main Content e sono le proposte complessive,di qualsiasi dominio e il particolare piu' importante,deriva dal fatto che i content debbono essere unici ,in tutti i sensi:)
Deve essere unico l'argomento descritto nelle pubblicazioni e naturalmente anche i loro contenuti:)

La differenza è elevatissima,perche' esistono gli elementi sopra:)
Rappresentano l'opposto totale,rispetto all'operativita' di Alexa e il Long Standing Webmasters Guidelines,deve essere completo per qualsiasi contenuto e l'unione con il Taken Against Content Generally,rappresenta in realta' "la ragione sociale degli Engines" e il motivo dell'unione è semplicissima,perche' è la pertinenza dei dati il vero e unico valore economico e se fosse l'opposto (simile all'operativita' di Alexa) esisterebbe solo la sicurezza del fallimento:)
Naturalmente,non esiste "nessun accanimento individuale contro Alexa",ma deriva solo da un fatto oggettivo,ed è il suo "strombazzato rank",presente in qualsiasi ottimizzatore,come se "fosse la panacea" per risolvere "qualsiasi problema":)
Nella realta',a dispetto dei suoi strombazzati rank,è Alexa stessa ad avere tanti problemi,a cui si aggiunge anche l'Ignore Totale ,nelle linee guida stesse,dell'Engine di Riferimento:) (tra l'altro lo è anche per gli ottimizzatori:)

L'infinita fantasia del Caso Supremo,fornisce sempre le migliori evidenze:)
E' proprio "What is seo" la pubblicazione a maggior dimensioni del dominio di Alexa:)
Probabilmente non conosce nemmeno "l'estensione originale dell'acronimo" e quindi non ha nessun riferimento operativo dei seo stessi:)

E' all'interno della descrizione "What is seo" e hanno unito "Crawling and Indexing" come se esistesse "una conseguenza logica",mentre nella realta',è esattamente l'opposto:)
Il nesso con i dati è molto semplice,perche' questa posizione determina il reale Keywords Difficulty e nasce dalla differenza tra i termini effettivi e i loro unici (sono 1/8 e l'ideale è 1/3 o 1/4) ,perche' determinano le piu' alte probabilita' di avere Match e quindi di eliminare i termini stessi.
Il problema con i "Crawling ed Index" è molto semplice,perche' non esiste possibilita' di fare Edits (per questo motivo i Crawling Process iniziano dagli indirizzi precedenti e serve proprio per verificare "l'onesta dei webmasters":).
Quello descritto è solo il "primo problema" e poi occorre aggiungere l'originalita' complessiva di tutte le proposte,di ciscun dominio,ed è il Main Content.
Quindi occorre vedere prima se Esiste realmente e poi è indispensabile applicare il suo Copied e se dovessero esistere differenze cosi' elevate nei rapporti tra i termini effettivi e i suoi unici ,in 1 sola pubblicazione,è inevitabile che le proposte complessive,abbiano percentuali in Copied molto elevate e quindi non ci sara' nessun Index,semplicemente perche' i termini vengono eliminati:)
Occorre ricordare la cosa piu' banale,applicata a ciascun dominio del contesto online e cioe' gli Index possono averli solo i termini in 1 posizione,all'interno di 1 solo dominio e nel contesto globale avviene la stessa cosa:)
Il metodo è uguale per chiunque,Alexa compresa (https://blog.alexa.com/what-is-seo/) e per verificarlo,esiste il link appena aggiunto:)
Posso descrivere il suo Keywords Stuffing direttamente,perche' esistono dei termini "sistemati di proposito" e il contesto è quello descritto sopra:)
In teoria sarebbero termini rilevanti,pero' occorrono gli effettivi per creare valore e con i rapporti sistemati sopra,non è proprio possibile:)
Di sicuro la pubblicazione avra' avuto anche delle ottimizzazioni e hanno peggiorato anche la situazione,perche' esistono 36 Headers,per "solo 6 posizioni" e a queste condizioni il Crawling Process termina immediatamente e nelle "vistite successive",si ricorderanno di sicuro:) (in genere avvengono 1 volta ogni 2 o 3 mesi:)
Dei 36 Headers,12 di essi sono sistemati in H2 e le posizioni sono gerarchiche e quindi,ognuna ha una funzione specifica e H2,possiede solo la data delle pubblicazioni e H3 ha il suo nome e gli altri Headers possono avere solo 1 periodo,formato al massimo da 5 termini o 60 caratteri:)
E' What is seo" di Alexa,ed è la prima pubblicazione in dimensioni e per forza di cose,il suo Match inizia dagli altri contenuti del dominio specifico e quindi diventa ragionevole anche la posizione delle Guidelines di Google,perche' i rank strombazzati di Alexa,sono realizzati dagli stessi "cervelli" e quindi è naturale che esista l'Ignore Totale per i "dati di Alexa":)



L'unione straordinaria delle date,citata per McAfee ,deriva dall'unione con l'operativita' delle Sitemap stesse e "quindi per i poveri 1860 termini effettivi" della pubblicazione protagonista, esistono i conflitti con i contenuti complessivi del dominio,praticamente da sempre (l'esempio delle Sitemap è nato proprio con la pubblicazione protagonista di questo 72° RF) e quindi ad ogni Crawling Process,la pubblicazione "si è salvata solo per propri meriti",perche' non sono operativi gli Internal Links OUT; non esistono Disallow ; non sono presenti NOFollow Links IN e le Sitemap,hanno permesso di raggiungere qualsiasi pubblicazione:)





Questo è un esempio localizzato sempre in 1 Ora e le varie tonalita' dei colori,indicano attacchi maggiori o minori.
In realta' non è facile nemmeno comprenderli e l'esempio è nell'immagine sotto:)





In quest'immagine esiste "il contesto completo del percorso" per la protagonista di questo 72° RF e sono "le avvertenze sui rischi" da parte del Trasparency Report di Google. (sono i domini diretti e non sono compresi i links dei DoFollow)

Questi sono "i tempi di risposta,dopo le avvertenze,per il Clean dei domini


Dopo il contesto della security esiste quello dei Content e iniziano dai Copyright e sono sufficenti 2 sue violazioni per avere "il Delisting" ,ed è esattamente l'opposto dell'Index:) (solo Alexa pensa che siano operazioni semplici e forse per questo motivo ha unito il Crawling all'Index in maniera diretta:)

Questa posizione è direttamente unita ai copyright e ho scelto solo 1 termine,rispetto al primo Just Time Google Patents K2 e ovviamente "è il piu' pertinente da unire ai copyrights stessi e cioe' UNIQUE:)

Le descrizioni delle varie posizioni del copyright sono all'interno della pubblicazione collegata e l'unione con il "Delisting" è molto semplice,perche' sono formate dalle percentuali "di contestazioni accolte" dai vari "Recipient" e naturalmente il piu' importante è Google,ed è Sua Explore Data per UNIQUE.
Posso anticipare che i copyright,per 1 solo termine,sono incredibili e ho scelto solo 1dominio da "sistemare come esempio" e nella pubblicazione di "Topic Copyright process Archive" ne esistono altri.
Queste posizioni renderanno anche molto facile comprendere "da cosa derivano" i dati ufficiali di Google stessa,sul numero di pubblicazioni eliminate in 1 giorno (i dati del dominio ufficiale dicono 25 Billions ),ed è altrettanto facile comprendere l'equivalenza con l'opera piu' nota di Leo Tolstoy (20 Milions dei suoi volumi,corrispondono le dimensioni delle pubblicazioni eliminate in 1 giorno,solo da Google:),perche' tutti i dati che sistemero' sono uniti al termine unico UNIQUE,solo per gli URL:) (quindi possono essere coinvolti i nomi delle pubblicazioni ; gli Anchor Text o entrambi)
Ai dati che sistemero',per 1 solo Termine,esclusivamente negli URL,sara' sufficente aggiungere anche i Match normali dei Text e l'elininazione dei termini e diventera' "ragionevole" anche l'incredibile volume dei contenuti eliminati in 1 solo giorno:)
Ai dati che sistemero',per 1 solo Termine,esclusivamente negli URL,sara' sufficente aggiungere anche i Match normali dei Text e l'elininazione dei termini e diventera' "ragionevole" anche l'incredibile volume dei contenuti eliminati in 1 solo giorno:)
Per la protagonista del 72° RF e di tutti i precedenti,diventera' un contesto straordinario,perche' i suoi contenuti hanno avuto anche i Match interni al dominio e per avere l'Index,per forza di cose,i conflitti li ha avuti con le dimensioni attuali:)

E' solo il primo dominio ad essere unito al termine unico "UNIQUE" ,nei delisting dei copyrights.

In teoria esistono i "No Action Taken" ,pero' non sono rilevabili,perche' il numero è "molto esisguo":) (ne sono solo 6 le contestazioni dei copyright con esisto negativo ,per i contestatori stessi:)
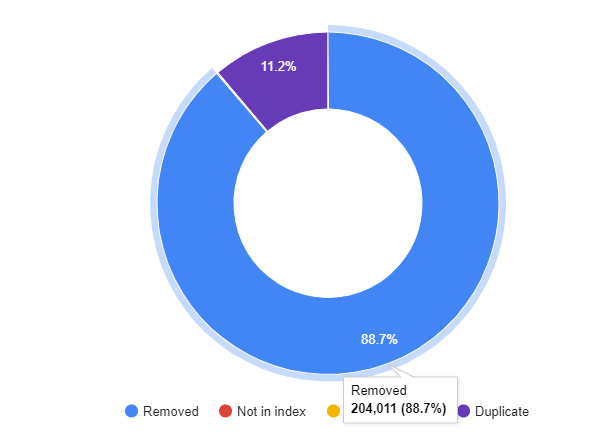
In questa evidenza esistono invece i Removed, ed occorre ricordare che il riferimento è solo il termine unico "UNIQUE",sistemato negli URL e quindi non sono compresi i Match dei contenuti effettivi.


Il fatto che esiste 1 sola posizione da Nov 2016,non è affatto banale,perche' non esiste "solo l?eventuale problema del Cloaking",ma sono aggiunti anche i Match interni del dominio e l'impatto del Taken Din Colors Five "è terrificante":)
Il piu' recente la pubblicazione protagonista del 72° RF, l'ha avuto a OCT 8 2020 e ovviamente i Match sono stati tutti naturali e a confermarli è il Crawling Process, unito a 2 Sitemap:)
Quindi per forza di cose,esiste solo il Natural Language ,ed è straordinaria la sua verifica, perche' nemmeno i migliori Automated Content sono capaci di unire i contenuti "in maniera pertinente" e senza creare conflitti tra di loro:)
 I domini Wikipedia sono sempre i migliori esempi e quello specifico italiano ,ha un utilizzo "limitato degli strumenti automatici" (i dati ufficiali di Wikimedia,dicono 13%:) e nel dato non sono compresi gli EDITS:)
I domini Wikipedia sono sempre i migliori esempi e quello specifico italiano ,ha un utilizzo "limitato degli strumenti automatici" (i dati ufficiali di Wikimedia,dicono 13%:) e nel dato non sono compresi gli EDITS:)
Quindi per forza di cose,esiste solo il Natural Language ,ed è straordinaria la sua verifica, perche' nemmeno i migliori Automated Content sono capaci di unire i contenuti "in maniera pertinente" e senza creare conflitti tra di loro:)
In realta' sono molto simili agli strumenti automatici e nel Caso specifico ,sono operativi direttamente e solo per la pubblicazione "Italia" ,tra autori naturali e "artificiali", gli Edits totali sono 10205,ed è stata la prima pubblicazione in dimensioni del dominio italiano di Wiki a OCT 2020.
 Nonostante tutte le operazioni di EDITS ,i content "di Italia",non appartengono al dominio italiano :)
Nonostante tutte le operazioni di EDITS ,i content "di Italia",non appartengono al dominio italiano :)
La prima è l'enciclopedia De Agostini (sapere.it) e poi esistono i domini elencati sopra,a cui se ne uniscono altri 150 "nelle prime posizioni":)
Questo dimostra quanto è difficile il Natural Languege,perche' nemmeno gli strumenti automatici sono capaci "di creare unioni pertinenti" e i dati sopra,possiedono anche un altro importante aiuto:

Non possiede la Sitemap e quindi i 2987 Internal Links OUT sono "operativi" e applicati alla prima pubblicazione in dimensioni ,produce una differenza notevole nei dati:)
Grazie Wiki:)
 Copied Content Quality Archive
Copied Content Quality Archive
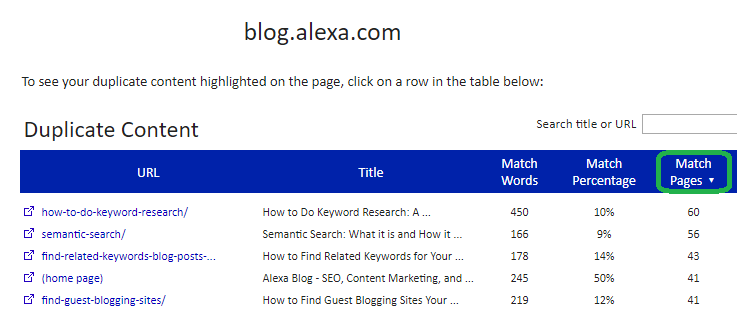 La "Semantic Search" di Alexa è proprio l'ideale per unire il passaggio dedicato alla "leggibilita' dei content":)
La "Semantic Search" di Alexa è proprio l'ideale per unire il passaggio dedicato alla "leggibilita' dei content":)
Nel Contest Level Absolute esistono le descrizioni dirette per la Semantic:)


Nel Contest Level Absolute esistono le descrizioni dirette per la Semantic:)
La vera "semantica" è negli Automated Index e il senso è nella pagina di "Copied Content Quality Archive" collegata sopra.
Anche i suoi contenuti sono originali (SEP 2017:) ed è possibile fare una modifica "al livello confidenziale dei gradi della leggibilita'" e cioe' non sono inseriti nelle Guidelines e non rappresentano nessun fattore,perche' il valore dei gradi, sono solo uniti ai content oggettivi:)
Occorre prima la "triplice originalita'" (quella dei periodi effettivi; l'originalita' interna dei domini e poi quella globale) ; i contenuti debbono essere Naturali ; deve essere presente ilMain Content ; è indispensabile non violare nessun copyright e solo al termine è possibile sistemare anche i gradi e lo stesso percorso deve farlo "La Semantic di Alexa o di chiunque altro":)
Sono gradi fantastici e per comprenderli meglio, esistono i rapporti descritti in Copied Content Quality Archive:)
Sono nelle Academic Papers e i loro gradi ,sono uniti anche ai valori dei Content,perche' effettivamente appartengono al dominio:)

A OCT 14 2020 è avvenuto l'Update delle Guidelines (ne esistono 1 o 2 in 1 anno) e per festeggiarli ,ho scelto la cosa piu semplice,ed è nell'immagine sopra:)
Esiste 1 solo fattore per distinguere la High Quality MC e naturalmente è indispensabile che esistano prima i Main Content e che "non siano modificati" e siano disponibili:)
Ho aggiunto "Dati No Language AR" e l'acronimo è in realta' il TLD della lingua araba,ed è quella piu' utilizzato da tanti seo (Alexa compresa) e naturalmente non comprendono il linguaggio reale ,ma conoscono solo i caratteri dei numeri e per questo motivo inseriscono "centinaia di fattori" ,senza nessuna unione tra di loro e sopratutto senza nemmeno conoscere il contesto a cui sono applicati i numeri:)

Sono le Close Variants nella lingua di questi contenuti e le Ads,dipendono dai loro valori:)
Quindi hanno 1 solo fattore anche loro per gli High Quality:

