

Nella sua Crown Colors ,l'ho definito "molto particolare" e i motivi originali sono gia' nell'immagine sopra,ed è un grafico molto semplice,pero'i suoi contenuti sono fantastici:)
Inizio dalla posizione oggettiva,ed è diversa rispetto a quella descritta nella Crown Colors,perche' OCT 2020,non è alla 5°,ma alla 6° posizione generale e la differenza non è banale,perche' la posizione successiva (7°) è occupata dal primo Oigin RF ONE (Nov 2019) e ha resistito al vertice per 7 mesi consecutivi:)
Gli onori dei dati per OCT 2020,non finiscono qui,perche'insieme alle sue "posizioni particolari" ,è intervenuto anche questa volta il Caso Supremo e ha reso memorabile anche la 6° posizione generale di OCT 2020:)
L'unica difficolta' è nella sistemazione delle tantissime unioni e per rendere l'esposizione semplice,inizio dalla prima collocazione originale per OCT 2020:)

Dopo Wiki in lingua cebuana e diversi altri domini Wikimedia,esiste anche il TFD Plato a non possedere una Sitemap. Non è una "posizione obbligatoria possederla",pero' i valori dei dati cambiano tantissimo,perche' anche Plato possiede gli Internal Links OUT e sono numerosi:) Quindi i dati di OCT 2020 sono fantastici in generale,perche' provengono dalle impostazioni del Frame Global Limit e tra i suoi elementi è possibile sistemare anche la presenza della Sitemap e l'unione con gli altri elementi,rende meravigliosi i valori dei dati:) E' sufficente unirla al Taken Din Colors Five e la meraviglia diventa subito evidente e poi è possibile unire l'Original Text ;i pesi degli elementi ;la monotematicita' dei contenuti ;il contesto tecnico online;l'assenza di ottimizzazione ; il Detect Language italiano e applicare a Loro gli Internal Links OUT e la presenza o meno della Sitemap,forma un valore elevatissimo nelle differenze:)
Questa posizione mi ha fornito un suggerimento logico,ed è l'ingresso della Sitemap nel Frame Global Limit,perche' nessun dato puo essere assoluto,ma occorre creare delle unioni per comprendere i valori reali e per OCT 2020,il primo Onore dei Dati è fornito dal Taken Din Colors Five:)
Da questa pubblicazione si festeggeranno anche i 50000 termini effettivi e i 3,3 Milions sono arrivati ad AUG 2020 e i 50000 successivi arriveranno tra' un po':)
Per formare questo "piccolo spazio in differenza" (sono necessari 160 termini da adesso:) ,sistemo i dati esatti,rispetto alla Crown Colors e in quell'occasione ,ho "solo citato la mia memoria" e cioe' non mi ricordavo nessuna verifica,che avesse avuto un dato minore a 200 pubblicazioni:)
In questa posizione posso confermare l'ottima memoria,perche' effettivamente,nessuna verifica ha avuto mai 198 pubblicazioni,ed è possibile iniziare da Nov 2019,alla 7° posizione,ed ha avuto 224 pubblicazioni e il suo volume complessivo è minore di 2000 termini,rispetto ad OCT 2020,ed è stato Origin RF ONE per tanti mesi:)
Tutti i dati sono all'interno di Contest LevelAbsolute e sono sistemati solo in Ordine temporale (a parte gli Origin RF ONE) ,mentre adesso ne sistemo alcuni,a scalare nei valori e questa posizione servira' per gli Onori dei Dati a OCT 2020 (i nomi progressivi delle verifiche dei content interni ai domini,derivano solo dalle impostazioni delle date:).
Alla 8° posizione generale,esiste DEC 2019 e quindi hanno quasi 1 anno i suoi dati e ha raggiunto 618602 con oltre 220 pubblicazioni.
Alla 9° posizione e' presente Jan 2020 e la 10° è occupata da FEB 2020,ed entrambe hanno un numero assai piu' elevato di pubblicazioni e naturalmente,sono minori i volumi,rispetto a OCT 2020.
Alla 11° e 12° posizione,esistono Mar e Apr 2020,mentre alla 13° posizione,esiste "il mese omologo" di 1 anno fa',ed è OCT 2019.
Alla 14° posizione è sistemato SEP 2019,ed è stata la prima verifica a superare mezzo milione di termini effettivi in 1 sola posizione:)
Quindi è facile anche la divisione per gli Onori dei Dati,per OCT 2020 ,perche' le prime 4 posizioni sono tutte superiori a 700000 termini effettivi e poi ne esistono 7,superiori a 600000 termini effettivi e in realta' ne sono quasi 8,perche' esiste Apr 2020 a oltre 596000 e OCT 2019 ha raggiunto 573000 termini effettivi.
Questi dati sono importantissimi,perche' rappresentano la migliore unione con i contenuti che seguiranno,ad iniziare dalla migliore evidenza di cosa significa in realta' la Sitemap,in contrapposizione agli Internal Links OUT e si potrebbero anche aggiungere le presenze dei NoFollow Links IN ,ed è possibile unire anche i Disallow direttamente,perche' anche loro hanno una notevole presenza in tantissimi domini:)

Occupa la 15° posizione,ed è l'11° TPJ Content Level e sono evidenziate anche le sue posizioni precedenti,rispetto ai volumi piu' elevati:)
Non esiste nessuna verifica interna,che sia arrivata al suo livello,fino a Jun 2019 e significa quasi la meta',rispetto al numero complessivo delle verifiche stesse:) (questa è la 28°:)
L'aspetto curioso deriva dal fatto,che la 15° posizione generale,è l'unica ad avere quasi lo stesso numero di pubblicazioni di OCT 2020 e ne esistono solo 3 in differenza,pero' i volumi complessivi,sono separati da quasi 200000 termini effettivi :)
I numeri sono importanti,pero' la loro conoscenza effettiva ,richiede altre unioni e sono quelli del Contesto Online e il senso reale dei dati,è completamente differente rispetto al contesto tradizionale:)


Naturalmente,il nome scelto deriva dal Contest Level Absolute e l'unione con i suoi dati nasce dagli average in differenza (sono in pratica 10 pubblicazioni per 50000 termini) e rispetto al contesto tradizionale di qualsiasi contenuto,nemmeno il livello del Contest Absolute,puo contenere i dati,perche' esiste l'unione dei contenuti complessivi e trasformano completamente i rapporti:)
Applicare 50000 termini al Taken Din Colors Five (sono appena passati 3,35 Milions di termini effettivi:) ,servirebbero quasi 3 volte l'intero Contest Level Absolute per avere le stesse condizioni e nel suo Caso,esistono anche i migliori rapporti,perche' i suoi contenuti sono realizzati tramite 1 sola posizione:)
Nelle Opere Top,solo il TFD Marcel Proust ha contenuti realizzati in 1 sola posizione,pero' in maniera parziale (solo il 50% dei suoi contenuti,hanno la posizione unica ) ,mentre è l'opposto per tutti gli altri autori:).
La descrizione di questo contesto è fondamentale,perche' i valori dei dati derivano dall'unicita' delle posizioni,insieme a quella dei contenuti:)
E' la pubblicazione precedente,ed è anche un anticipo dell'attuale e avra' diversi ruoli nei contenuti che seguiranno e iniziano dai passaggi dedicati alla parte bella della rete italiana e l'unione è molto semplice,perche' anche i suoi INDEX,hanno l'unicita' delle posizioni,descritte sopra,altrimenti non esisterebbe nessun dato:)
E' sufficente ricordare quanto sono elevati gli INDEX della rete italiana ,ed è uguale a 15,3 volte,tutti gli scritti della storia umana,ed è vero che esistono un numero di autori maggiore dell'intera popolazione italiana (oltre 10 Milions), pero' occorre anche aggiungere l'elevata frammentazione degli autori italiani effettivi e quindi,i dati degli INDEX esisterebbero lo stesso,anche considerando solo "gli autori autoctoni dei content italiani":)

Lo strumento non puo conoscere se esistono EDITS o se i contenuti sono naturali e la prima unione deriva dai Fundamental Search,attraverso i fantastici primi periodi:)
All'apparenza la descrizione è semplice,mentre le loro applicazioni sono le piu' sofisticate che l'umanita' abbia mai avuto:)
L'inizio è il Crawling Process e l'applicazione inizia dagli indirizzi precedenti ,per ovvie ragioni e poi è inserita anche la presenza della Sitemap ,per rendere facile "la conoscenza degli sviluppi " di qualsiasi dominio.
I problemi iniziano a questo punto ,perche' spesso i contenuti non sono originali e la Sitemap non è affatto presente:)
In diversi casi,si aggiungono altri problemi rilevati dal Crawling Process e saranno protagonisti tra un po' e riguardano "le Mancate Attenzioni ai collegamenti esterni" e per forza di cose sono molto elevati,perche' l'average dei DoFollow è superiore al 90%,rispetto a qualsiasi dominio.
La novita' che sistemero' "è davvero curiosa" e riguardera' Wiki in lingua cebuana ,per delle modifiche fatte ai suoi collegamenti nei Links in NoFollow ,trasformati in DoFollow:)
Avere dei collegamenti verso Wiki cebuana,rende sicuro l'effetto boomerang e quando le segnalazioni tornano indietro,esiste solo l'aspetto negativo da sostenere e l'informazione passa ai Crawling Process e "intuiscono facilmente" che l'autore è un idiota,perche' l'attenzione ai collegamenti,deve essere fatta con intelligenza reale e cioe' occorre valutare gli spazi,ma sopratutto chi li gestisce:)

I contenuti originali sono garantiti,ed è una posizione davvero vitale,per gli Engines stessi,per ovvie ragioni,perche' se non si conoscono le posizioni originali ,non è possibile determinare nessuna unicita' e tantomeno sara' possibile selezionare valori con pertinenza:)
Quindi,qualsiasi dato del contesto online deriva dalle posizioni appena sistemate, ed occorre aggiungere "un aspetto poco noto" e cioe' i "Crawling Process hanno una notevole memoria",in tutti i sensi e "l'aspetto poco noto" ,inizia dalle impostazioni stesse e quindi i NoIndex e i NoFollow interni ai domini,non si possono "modificare secondo le proprie convenienze" ,perche' vengono considerate delle Over Ottimizzazioni.
Per comprendere la posizione,è sufficente aggiungere "l'elemento omologo" ai NoIndex e ai NoFollow e sono i Disallow e il loro abuso,deriva dalla ragione piu' semplice e sono le rilevanze dei Content:)
Solo per questo motivo vengono sistemati i NoIndex; NoFollow e i Disallow e di conseguenza diventa logica l'attenzione dei Crawling Process alle impostazioni scelte,oltre agli indirrizzi precedenti e quindi la loro modifica,rappresenta solo un informazione negativa.
Nell'immagine sopra,sono sistemati anche i codici ,per la posizione corretta dei NoFollow e NoIndex e ho lasciato di proposito la 3° opzione possibile,perche' è in realta' la piu' straordinaria:)
Esistono anche i codici per il NoArchive e la posizione non è affatto banale,perche' il loro senso pratico riguarda le proposte complessive e sono loro a formare il Main Content e quindi,se non è possibile accedere alle pubblicazioni precedenti (questo è il senso pratico dei codici di NoArchive),non esistera' mai nessun Main Content e quindi non avranno nemmeno valore le eventuali altre pubblicazioni presenti.
Anche per il NoArchive,sono valide le regole degli altri elementi presenti e quindi,chi dovesse scegliere queste impostazioni,puo dimenticarsi del tutto di fare "modifiche successive" ,semplicemente perche' i Content non avrebbero nessuna credibilita':)
Quindi esiste 1 sola posizione possibile e cioe' i contenuti possono nascere solo in maniera naturale e il loro percorso deve essere altrettanto naturale e queste idee,non "sono affatto elitarie" e il miglior esempio sono gli altri milioni di autori dei contenuti in lingua italiana:)
Naturalmente esistono anche quelli del contesto globale e il numero dei loro INDEX si formano solo dal Natural Contest e ovviamente non possono essere presenti i codici del NO INDEX interni ai domini:)

E' direttamente unito anche agli elementi del Crowling Process,perche' l'operativita' degli Internal Links OUT è assai simile ai NO Index ;ai NoFollow e ai Disallow interni ai domini ,perche' limitano le operazioni dei Crawling Process stessi.
Negli Internal Links OUT esistono solo dei parziali collegamenti e in genere "terminano presto" e l'esempio sistemato nell'immagine è realistico e cioe' al 3° Click Depth non esiste nessun collegamento e quindi ,le eventuali pubblicazioni presenti,vengono escluse e naturalmente,i valori dei dati cambiano tantissimo,per ovvie ragioni:)

TD OverAll Sky è presente anch'essa nel Just Time di AUG 12 collegato sopra,ed è fantastica la sua unione con i Crawling process del Fundamental Search:)
TD Overall Sky è nata da tanto tempo e l'unione con il Frame Global Limit è avvenuta grazie al Core Web Vitals e tra i suoi primi elementi esiste il Loading e di conseguenza sono fondamentali anche i pesi degli elementi statici per essere negli INDEX:)
L'unione con il Crawling Process è molto semplice,perche' se dovessero esistere parita' di rilevanza tra contenuti di diversi domini,ricevera' l'INDEX,i contenuti che hanno il miglior Core Web Vitals e cioe' Loading piu' veloci:)
E' un tappeto di fiori per gli RF e i Just Time,perche' nei Loading sono compresi anche i pesi degli elementi in cui sono sistemate fisicamente le pubblicazioni e tra quelle individuali,nessuna di ESSE, "ha un contesto leggero":)
Quindi solo i Content hanno potuto risolvere i Match per i domini individuali ,semplicemente perche' non esiste nessuna alternativa e in essa sono compresi anche gli elementi del Crawling Process:) .

Nei Crowling Process esistono anche queste posizioni per gli INDEX e i contenuti applicati,hanno estensioni enciclopedice e quindi inserisco le parti essenziali:)
Nella realta',le Structured Data sono molto semplice,perche' rappresentano le posizioni Standard dei Content,in qualsiasi dominio e per rendere facile la posizione,ho scelto "i ruoli complessi":)

E' sufficente solo l'unione del primo e gli altri elementi presenti,rappresentano solo delle descrizioni,poco verificali,proprio per il ruolo Standard delle Strutture Data stesse:)
La meno verificabile,è nella prima posizione e sono gli Invalid Document di JSON,ed è solo uno dei Format Maggiori delle strutture data.
E' davvero "un ipotesi molto remota" che esistano degli Invalid Document,non solo perche' il software è tra i piu' sofisticati,ma sopratutto perche' fornisce delle "strutture standard"e quindi le probabilita' che esistano "degli errori di sintassi" di JSON,sono nulle!:)

Non esistono errori di sintassi nelle strutture data (ovviamente se sono presenti) ,ma sono sempre i Webmastres,a procurare i danni ,ed è il senso di Misleadings Markup (in maniera eufemistica si definiscono "FUORVIANTI":)

Sono i falsi piu' semplici da scoprire,perche' se sono idioti con le strutture data (sono realizzate tutte in maniera Standard) e imbecilli con il Markup (le percentuali sono quelle sopra ) ,non possono fornire nessun valore reale,a parte l'idiozia di chi sceglie queste operazioni:)

L'unione di queste posizioni con la verifica dei contenuti interni dei domini,di OCT 2020, è molto semplice,perche' le "Strutture Data e il Markup" permettono la migliore comprensione dei contenuti ,in funzione della NATURALITA' dei Medesimi:)
Nei dati delle verifiche è impossibile conoscrla per tutti i domini,tranne in quello individuale,perche' esistono 71 RF ed è gia' iniziato il K2 del Just Time e per essere presenti i loro dati,significa che i Crawling Process sono gia' avvenuti :)

Ho scelto di sistemarla perche' in alcuni reports esiste la sua presenza,mentre nell'immagine collegata sopra,è indicata l'attuale operativita' per le strutture data di Google.
Occorre aggiungere la cosa piu' banale,pero'è molto importante lo stesso, e cioe' le strutture data servono "per comprendere meglio i contenuti" e quindi è indispensabile che esista e naturalmente è presente anche il suo opposto e cioe' "la migliore comprensione" ,rende anche molto piu' elevata la possibilita' di avere dei Match e quindi di essere eliminati:)
Il fine ultimo di queste posizioni sono formati dagli "END of CODE" e sono i codici finali di qualsiasi contenuto del contesto online (periodo by periodo:) e sono essi a formare le Grid to Record e dai loro valori,nascono anche ui Crawling Process successivi.


Le descrizioni sono nel Natural Contest precedente,dedicato agli High learning italiani:)





Sarebbe stato meglio fare l'opposto,perche' rendere vicini nei Click Depths,contenuti cosi scarsi,non è proprio conveniente:)



Questa è la Sitemap di Google the Keyword ,ed è il dominio ufficiale di Big G e solo la sua posizione ,permette l'equivalenza con l'idiozia totale delle "Mappe dei Siti" ,realizzati da Ecampus e anche da Treccani e ho citato solo i domini diretti sistemati e poi ne esistono tanti altri:)
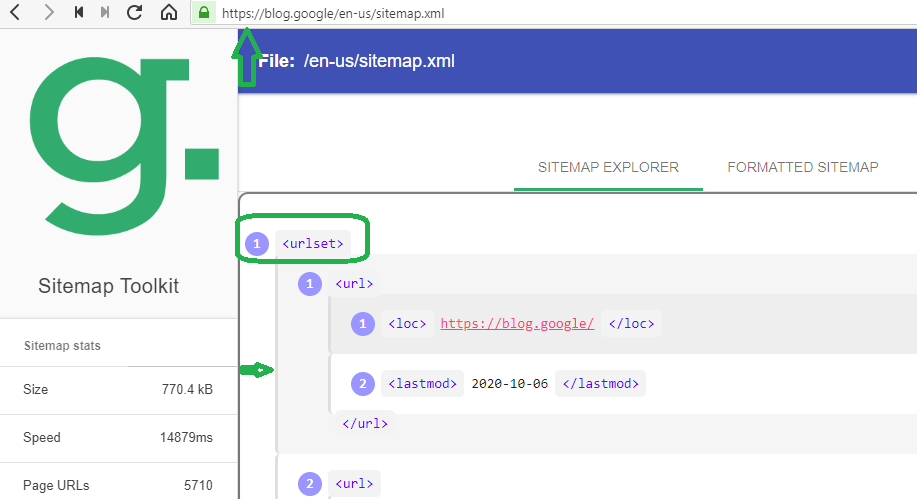
La posizione è semplice e sono sufficenti le 2 evidenze:esiste l'apertura dei codici <urlset> e poi sono sistemati tutti gli url del dominio (in teoria,per una normale sitemap,potrebbero arrivare a 50000 e poi è possibile sistemarne anche altre e coprire tutti i contenuti di qualasiasi dominio).
L'altra evidenza importante è la freccia di colore verde e rappresenta "la catena continua della Sitemap" e la differenza con gli Internal Links OUT (o con i NoIndex; NoFollow;Disallow) è "la catena spezzata":).
La scissione arriva quasi subito (in genere al 3° Click Depth avviene gia' "la divisione della catena",mentre le posizioni della Sitemap iniziano sempre dall'ultima pubblicazione fatta e termina con l'opposto dei codici descritti sopra (<urlset> è l'apertura e </urlset> è la chiusura)

I consigli per le ottimizzazioni sono molto rari,su qualsiasi dominio di Google e quindi solo la presenza,rappresenta gia' un evento:)
L'aspetto straordinario,LORO MALGRADO,lo avranno i domini del "Content Management System" (CMS) e saranno divertentissimi i loro reports:)
L'unica difficolta' sara' comprendere chi è piu' imbecille ,tra coloro che pagano i CMS e gli operatori stessi:)
 La soluzione per comprendere chi è piu' imbecille,è arrivata sempre grazie al Webmasters di Google:è sufficente partire dai costi dei CMS (tra l'altro hanno ampli limiti gia' in proprio) e unire i contenuti sopra e poi vedere i reports:)
La soluzione per comprendere chi è piu' imbecille,è arrivata sempre grazie al Webmasters di Google:è sufficente partire dai costi dei CMS (tra l'altro hanno ampli limiti gia' in proprio) e unire i contenuti sopra e poi vedere i reports:)
La parte finale evidenziata è meravigliosa e cioe' "non esiste la garanzia che tutte le "submitting sitemaps" possano arrivare agli iNDEX,ed è una posizione normale,perche' con le Sitemap è inevitabile che siano anche piu' elevati i Match dei termini:).
Da questa posizione,diventa facile stabilire chi è piu' imbecille,tra coloro che pagano il servizio CSM e gli operatori stessi,perche' se non esiste la "garanzia degli INDEX" con la Sitemap,figurarsi che garanzia possono fornire coloro che non la possiedono e ovviamente i Match dei Content,si possono perdere anche con le Sitemap ,pero' almeno esiste "il confronto dei Match",a titolo gratuito:)
Nei CMS senza Sitemap,i Match non iniziano nemmeno ,ed esistono degli imbecilli che hanno anche pagato,per ottimizzare i loro Content:) Dai costi dei calcolatori,solo il CMS,arriva sui 25000 dollari ed esistono dei limiti nelle pubblicazioni e nel numero dei termini presenti e non è prevista "nessuna possibile fluttuazione" e sopratutto i Content debbono crearli gli utenti stessi e poi pagare i CMS:)
E' il Webmasters di Google stessa che indica "le migliori ottimizzazioni" ,ed è la Naturale Fonte piu' attendibile,perche' quasi la Totalita' del Market Share dipende sempre da ESSA:)
Quindi è palese che occorre essere proprio imbecilli e grazie alle posizioni di Treccani ed Ecampus,è possibile stabilire anche il livello massimo dell'imbecillita' assoluta:).
Per avere questa posizione,sono indispensabili i passaggi sopra (il CMS;i pagatori del servizio e l'assenza di Sitemap) e se fosse presente "la Mappa del Sito" ,sistemata in 1 pagina,all'interno dello stesso dominio,si arriva all'imbecillta' totale:) (tra l'altro Ecampus e Treccani,forniscono anche un Must all'idiozia pura,perche' le pagine sono in totale conflitto con gli altri contenuti ed hanno migliaia di links collegati,ed essendo una mappa del Sito,sono tutte in violazione di Anchor Text pure!:)

Per trovarle,non occorre il Search Console,ma sono disponibili nel contesto online in maniera gratuita e derivano dalla cosa piu' semplice e sono i match dei termini:)

La scelta di AWR,deriva solo dal fatto che il dominio sara' presente tra un po' e la pubblicazione specifica è tra quelle a dimensioni massime della verifica di OCT 2020:)
I Contenuti "Sponsored",sono in realta' uniti ai NoFollow e la posizione è obbligatoria da Mar 2020 e quindi,non partecipera' mai alla Natural Search e solo da essa nascono le vere rilevanze:)
Le SERP Futures sono in realta' degli Snippet e sono sistemati ,all'inizio di qualsiasi ricerca,ovviamente se esistono le condizioni per farlo e sono le stesse dell'Organic:) (cioe' per le Serp Features non esiste nessun Paid e quindi occorre meritare le posizioni in maniera naturale:)

I contenuti di AWR,rendono semplice anche i Costi della Natural Search,ed è sufficente vedere l'importo del Content Marketing (sono le ottimizzazioni) e unirlo ai costi della Paid Search (arrivano al massimo al 6%) e sara' facile avere anche gli "eventuali costi della Natural Search:) (non è possibile nessun Paid per averla,pero' i termini che contiene hanno dei valori e sono oltre 20 volte maggiori,rispetto alla Paid Search e quindi sono facili i calcoli:)

In teoria ne esistono migliaia di fattori da poter applicare a qualsiasi Organico (si potrebbero inserire tutti i termini delle guidelines e ognuno di loro rappresenta un fattore) ,nella realta',peri Regular Organic Result",esistono solo i "Super Fattori" e ne sono poche unita' e senza di essi è inutile vedere le altre centinaia o migliaia di "Middle Factors" ,perche' non saranno capaci di modificare assolutamente nulla:)
La prova è sistemata sempre in AWR ,attraverso i "Ranking Signals" ,semplicemente perche' nei fattori reali,non esiste nemmeno "il termine ranking stesso":) (quindi per AWR,sarebbe meglio cambiare il suo nome e sistemare il termine giusto presente nei Fattori Reali e si dovrebbe chiamare Advanced Web RATING :)
 Questa è la posizione di AWR per OCT 2020
Questa è la posizione di AWR per OCT 2020
I contenuti appena sistemati,appartengono proprio a "The Anatomy of Google Search" ,ed è la seconda pubblicazioni in dimensioni,ed è meravigliosa anche la prima e la terza,pero' solo dal punto di vista dei contenuti individuali:)
I Reports dei Seo ,avranno delle collocazioni specifiche nei Brain Stone,attraverso un altro termine magico,ed è "VISIBILITY":)
Per la prima pubblicazione in dimensioni di AWR (Powerful Link Building) ,è sufficente aggiungere la collocazione vera ed è link Buyng o Selling e da questa posizione è nato nel 2016,il Run by Idiots e proviene direttamente da Google,appena 4 mesi dopo aver creato i primi Run Forever:)
Sarebbero infiniti i contenuti da poter aggiungere e in questo contesto cito solo gli altri dati di AWR e nonostante i passaggi precedenti,sono molto buoni e solo per questo motivo è nei domini che partecipano alle verifiche:)
AWR ha avuto 229 pubblicazioni e il suo average è formato da 1887 termini effettivi e ha raggiunto il 79% in unicita'.

AWR ha avuto 229 pubblicazioni e il suo average è formato da 1887 termini effettivi e ha raggiunto il 79% in unicita'.
Il dominio possiede la Sitemap e quindi i suoi dati hanno un valore assai maggiore e solo la 2° pubblicazione in dimensioni ,ha 25 Internal Links OUT e con la presenza della Sitemap non sono operativi e quindi i Match sono per forza maggiori.
Queste posizioni,servono anche a ribadire i valori della parte bella della rete italiana,perche' se esistono i suoi INDEX ,significa che hanno le Sitemap oppure non esistono Internal Links OUT e tutto il resto,semplicemente perche' non avrebbero gli INDEX e grazie a queste posizioni,il volume della rete italiana è 15,3 volte maggiore,rispetto a tutti i contenuti scritti dall'intera storia umana e i valori riguardano solo gli INDEX e quindi esistono anche i "Loro Opposti" e sono i contenuti eliminati e anche loro possono essere calcolati e il numero piu' vicino alla realta' è formato da 1/100° ,rispetto a 25 Billions di pubblicazioni eliminate in 1 solo giorno:) (nei Post Base,esiste il senso pieno,applicato ai valori della rete italiana)






Le pubblicazioni di Encyclopedia per OCT 2020 sono state 222 e ha raggiunto il 94% in unicita' e l'average è spettacolare anche questa volta,ed è formato da 10155 termini effettivi.

Se esistessero 400 termini in differenza negli average per Encyclopedia,i contenuti del contesto tradizionale,dovrebbero avere i dati sopra,per avere le stesse condizioni:)
Sono equivalenti a 4 volte tutti gli scritti di Leo Tolstoy,realizzati in quasi 50 anni e sono quasi il doppio rispetto ai contenuti originali del TFD Marcel Proust e sopra di Lui non esiste nulla:)
Nei dati sopra manca poi un aspetto importante e non è possibile da calcolare,perche' la differenza dei 400 termini in average è applicata a 1 sola posizione e non esiste nulla di uguale nel contesto tradizionale:)
Il senso di questo passaggio è unito ai dati appena sistemati e agli average stessi di Encyclopedia,perche' hanno amplie variazioni,spesso superiori ai 400 termini descritti e naturalmente le stesse posizioni le hanno anche gli altri domini,pero' in Encyclopedia sono piu' evidenti:)
Ha il record assoluto degli average a oltre 13500 termini effettivi (Mar 2020) e poi è passata a 5000 ,ed è tornata a 10000 in 1 solo mese e queste posizioni dipendono da una cosa semplice,ed è la presenza della Sitemap,capace di capovolgere tutto,ad ogni verifica:)

Quindi l'esempio delle differenze degli average descritto sopra,è quasi minimalista,perche' i dati reali,solo per le differenze degli average va moltiplicato per 2,5 volte e naturalmente,dopo tutte le equivalenze,occorre avere anche la stessa unicita' del TFD Enciclopedia:)
L'unica differenza con Encyclopedia,sono gli Internal Links OUT e nella prima pubblicazione di Plato ne sono 45 e non essendo presente la Sitemap,sono operativi:)




Inizio dall'aspetto "negativo dei Broken Links" e ho virgolettato i termini,anche per la semplice ragione degli altri dati e se fossero realmente presenti tutti i Broken Links sistemati,non esisterebbero proprio:)

Se fossero presenti,nel lato destro sono indicati e naturalmente,qualcuno puo esistere,pero' nella realta' sono poche unita':)
Questa posizione restera' per 1 mese e quindi è facile da verificare:)

Moz ha "una tradizione leggendaria nei Broken Links" e cambiano solo gli Status Code e tranne il 200 o il 301 dei redirect,tutti gli altri Status Code hanno "dei problemi" e quelli di Moz sono il 409 (troppe richieste:) ,almeno in questa pubblicazione e sono tutti descritti minuziosamente e la barra di scorrimento è anche lunga e quindi è facile la comparazione"con la pagina individuale immacolata":)
questa è un altra pubblicazione individuale e non esiste nessun broken
E' possibile continuare e sono identiche anche le altre pubblicazioni e la "page not found" ,in realta' esiste e sono assenti solo i Broken:) (i pochi presenti sono segnalati:)
E' possibile continuare e sono identiche anche le altre pubblicazioni e la "page not found" ,in realta' esiste e sono assenti solo i Broken:) (i pochi presenti sono segnalati:)
La realta' dei broken Links è unita agli Status Code (il piu' frequente è il 404 ,quando le pagine non esistono realmente) e poi esistono anche dei Broken maggiori e sono i collegamenti con dei contenuti duplicati e tante presenze sono nei DoFollow,ed è facile anche calcolarli,perche' i duplicati del web arrivano al 40% e quindi,quasi 1 collegamento su 2,puo essere in Broken,anche se avesse gli status Code validi:)


In July 2020 esistono amplie descrizioni sugli strumenti non abilitati e sono anche attuali:)
Naturalmente la selezione dello strumento è legittima,pero' non esistono le abilitazioni e la loro importanza,deriva proprio dal numero degli skipped ,perche' quelli "dei presunti errori" ne sono 37 e poi esistono una decina di disallow,anch'essi non abilitati,semplicemente perche' non lo è il robots txt (è presente anch'esso nei contenuti di July 2020).
Naturalmente la selezione dello strumento è legittima,pero' non esistono le abilitazioni e la loro importanza,deriva proprio dal numero degli skipped ,perche' quelli "dei presunti errori" ne sono 37 e poi esistono una decina di disallow,anch'essi non abilitati,semplicemente perche' non lo è il robots txt (è presente anch'esso nei contenuti di July 2020).

Queste descrizioni sono importanti,perche' gli skipped effettivi sono circa 11 e sono solo dei redirect per altri domini individuali.


La sua data originale è Dec 2015,mentre il 4° RF della 6D è di Apr 2019 e grazie alle Sitemap ,non è stato necessario dividere gli anni ,perche' il Match è arrivato subito e gli Internal Links OUT,non hanno diviso nulla:)
In pratica 72 RF;28 verifiche interne ai domini e tutti i dati dei Just Time sono avvenuti con i Match completi,ed esistono almeno da Nov 2016:)

Anche TD Search Story 2 è presente e a sua volta a 19 Internal Links OUT e si potrebbe proseguire per tutte le pubblicazioni:)

Sono 10 pubblicazioni contro UNA e hanno prodotto solo 137 termini in match:)
Dopo 30 pubblicazioni,i match terminano a 4 pubblicazioni contro UNA e le oscillazioni proseguono fino alla 160° posizione e i volumi sono elevatissimi (OCT 2020 è alla 6° posizione su 28 verifiche e i suoi volumi hanno superato 630000 termini effettivi:).



Esistono tante altre selezioni,pero' la pubblicazione ha gia' dimensioni notevoli e le utilizzero' in altre occasioni:)
Ho sistemato l'immagine sopra perche' è davvero curiosa e riguarda i dati dei backlinks per Wiki in lingua cebuana e i Lost Links sono delle modifiche per varie ragioni e ho selezionato solo il removed:)
Il passaggio è da NoFollow (pochissimi su Wiki cebuana) a DoFollow (la maggioranza assoluta:) e nell'espansione dell'immagine esistono i dati esatti,compreso l'arco temporale dei Removed (esiste l'arco dell'espansione e quello generale è 1 anno).
Quindi resta valida "L'attenzione ai collegamenti",pero' gli spazi collegati occorre controllarli in maniera periodica,perche' occorre prestare attenzione "sopratutto alle teste dei gestori dei domini":) (cambiare un Nofollow in Dofollow verso Wiki cebuana occorre essere dei kamikaze:)
Gli altri domini presenti a OCT 2020 li cito:
Wiki in lingua cebuana ha avuto 179 pubblicazioni e 1127 è stato il suo average e ha raggiunto il 63%.Il TFD Moz ha avuto 195 pubblicazioni e 3943 è stato il suo average e ha raggiunto l'81% in unicita'.
Content Marketing Institute ha avuto 228 pubblicazioni e 2044 sono i termini effettivi in average e ha raggiunto il 60%.
Impact BND (si occupa di impatti proprio nei Brands:) ha avuto 233 pubblicazioni e 2388 è il suo average e ha raggiunto il 65%.
Il dominio tedesco di Godaddy ha avuto 236 pubblicazioni e 1386 sono stati i suoi termini in average e ha raggiunto il 64%.
Our World in Data (è un dominio del TFD Oxford) ha avuto 187 pubblicazioni e 3632 è statoil suo average e ha raggiunto l'80%.
Forbes ha avuto 224 pubblicazioni e 1870 è il suo average e ha raggiunto il 62% in unicita'.
IONOS ha avuto 205 pubblicazioni e 1522 è il suo average ed ha raggiunto il 68%.
Investopedia ha 193 pubblicazioni; 1505 in average e 62% in unicita'.
BigCommerce ha 195 pubblicazioni ; 1850 in average e 82% in unicita'.
Marketing Charts ha 244 pubblicazioni ; 1058 in average e 62% in unicita'.
Educause ha 214 pubblicazioni ; 1625 in average e 51% in unicita'.
Text Broker ha avuto 162 pubblicazioni ; 2063 in average e 69% in unicita'.
Search Engine Land ha 244 pubbliazioni ; 1253 in average e 54% in unicita.
Screaming Frog ha 249 pubblicazioni ; 2024 in average e 68% in unicita'.
Trust Radius ha 236 pubblicazioni ; 4047 in average e 77% in unicita'.
Icann Wiki ha 176 pubblicazioni ; 1309 in average ; 83% in unicita'.
Wiki italiana ha 189 pubblicazioni ; 2758 in average e 89% in unicita'.
Wiki Francia ha 246 pubblicazioni ; 2606 in average e 78% in unicita.
Wiki Spagna 216 pubblicazioni ; 3711 in unicita' e 88% in unicita'.
Wiki Tedesca ha 216 pubblicazioni ; 4044 in average ; 93% in unicita.
Wiki globale ha 236 pubblicazioni ; 5258 in average e ha raggiunto l'87%:)
La prossima pubblicazione sara' l'inizio dei Just Time in K2 e formeranno le reali verifiche e poi ci sara' il 72° RF e la pubblicazione è quella indicata dalle 2 Sitemap e la scelta deriva solo dallo straordinario suggerimento del Caso Supremo:) (da parte mia non mi ricordavo nemmeno che esistesse un account e sono presenti "solo 15 pubblicazioni" e iniziano proprio in coincidenza del primo RF e sono tornati,senza saperlo nemmeno, a OCT 2020:)
