


Le pagine A+ degli RF hanno le posizioni tecniche dei contenuti e li avra' anche questo 73° Run Forever:)
Comunque alcuni contesti è necessario descriverli anche in questa posizione ,perche' renderanno molto piu' semplice comprendere i dati che seguiranno!:)
La prima unione incredibile è nei contenuti della pagina collegata e in questa posizione evito "le unioni oggettive" (saranno nella pagina A di questo 73° RF) e sistemo solo il contesto della scelta , ed è molto semplice,perche' la pagina specifica collegata sopra ,ha per il momento pochi elementi al suo interno e per cercare di aumentarli ,ho pensato di utilizzare le posizioni del Gold Star:)


Il link ha il collegamento con la pagina "Don't Deceive Your Users" (sono i contenuti gemelli del Business:) e l'unione con il Long Standing Webmasters Guidelines è molto semplice,perche' le categorie non si possono scegliere,ma occorrono i contenuti per farlo:)
Quindi nemmeno le pubblicazioni protagoniste del Gold Star possono farlo,perche' nel corso del tempo,possono "variare tante cose" e non occorre sistemare il contesto globale,perche' dopo OCT 2016,esistono tantissimi contenuti e sono sufficenti LORO,per eliminare i precedenti:)
L'aspetto Incredibile deriva dal fatto che non è avvenuto e il 3° RF della prima Decade,ha mantenuto fede a dei suoi contenuti e il riferimento è al Milestone di OCT 2016:)
Nei contenuti originali esistono delle posizioni specifiche e dopo oltre 4 anni,il Milestone "avra' una nuova vita" ,perche',per la prima volta, esiste il MileContest:)
E' un "neologismo nei termini" ,ed è molto pertinente rispetto alla pubblicazione protagonista di OCT 2016,perche' nessun altra ha mai avuto le sue condizioni: non solo è presente dopo 4 anni,ma è unita anche la sua pagina A+ e sara' la protagonista del 74° RF:)
Le unioni incredibili,sono arrivate al MileContest,attraverso una semplice curiosita' ,ed è stata la verifica della pubblicazione protagonista di allora,ed è presente anche attualmente:) La sua data originale è APR 2015 e dopo di ESSA,esistono un numero colossale di contenuti e anche se fosse presente il Long Standing Webmasters Guidelines ,non sarebbe stato sufficente, perche' esiste anche il Taken Against Content Generally e inizia dai contenuti interni dei domini e senza di essi,non esiste nessuna possibilita' di arrivare al contesto globale:)



In questa prima posizione del MileContest sistemo "le basi del metodo" e il TFD Trustradius è un ottimo aiuto,perche' i suoi Rating sono uniti solo "all'esperienza degli utenti".
Da esse derivano anche le divisioni delle categorie e non hanno nulla in comune con i Rating reali e sono unite solo alla semplice logica e la prima è quella sistemata nell'immagine.
E' una della tante alternative a SpyFu e la sua collocazione naturale è nel Search Engine Marketing e sono assai simili ai Seo normali e per unire la specifica operativita' èpossibile aggiungere i costi del pay per click (CPC o pay per click).
Il Search Engine Marketing si occupa proprio di questo e l'aspetto fantastico è "vedere con che cosa ci arrivano":)
Gli "Strumenti spioni" ,utilizzano in realta' le stesse tattiche dei seo,in senso letterale:)

E' il sito ufficiale di Spyfu ,ed è indicato cosa si deve fare per aumentare il proprio Rankings:)
Inizia dalla cosa piu' semplice e sono i termini stessi e il "Ranking" nei fattori reali non esiste proprio e quindi,sono idioti anche come spioni:)
Esistono sempre i "tradizionali 200 factors" e la prima evidenza è una conferma dell'idiozia:)
"Sono finiti i giorni brutti del Keywords Stuffing" e l'hanno scritto realmente nel dominio ufficiale che si occupa "di spiare gli altri" e dopo questa farneticate affermazione ,hanno aggiunto i 200 Fattori:)
I Keywords Stuffing sono i Match dei termini e se vengono eliminati ,non esistera' nessun fattore successivo e la posizione specifica riguarda 1 sola pubblicazione e se esistesse ilKeywords Stuffing,non è possibile nemmeno compararla con le altre presenze di qualsiasi dominio e di conseguenza non esisteranno le proposte complessive e sono quest'ultime ad avere il vero Keywords Stuffing e sono i Copied dei Main Content:)

Il passaggio precedente "non è uno scherzo degli spioni" ,ma sono realmente convinti delle cazzate che hanno scritto e i contenuti non hanno la data di OCT 2016 ma è quella di July 2020 e quindi "hanno riflettuto pure parecchio" prima di scrivere tante cazzate in 1 sola pubblicazione:)
Nell'immagine ho sistemato solo degli esempi e sono fantastici da unire agli AVOID :l'unica posizione leggitima è "l'Avoid dei pensieri" prima di commettere degli abusi e violazioni,ed è sufficente la semplice ragione per comprenderlo:)
Se fosse possibile rimuovere i Low Quality,lo farebbero tutti ,oppure i Robots txt e i Meta Tags per risolvere i problemi:) (sarebbe sufficente togliere i primi e bloccare i secondi e l'unico problema deriva dal fatto che non esisterebbe nessun valore reale,perche' potrebbero farlo tutti:)
Alla 7° posizione esiste "il consiglio di trovare gli errori delle strutture data" e ovviamente è sottointeso di "eliminarli dopo averli trovati":)
A parte il fatto che gli errori delle struttura data "esistono solo in maniera teorica " ,semplicemente perche' sono Standard e quindi è molto piu' probabile che siano stati i gestori dei domini a causare degli errori ,ed è difficle che siano "anche in buonafede":)
Fatta questa premessa ,gli errori delle Strutture Data,se dovessero esistere ,non possono essere collocati in nessuna posizione (tantomeno alla 7°:) ma hanno una collocazione Super Partes,per la semplice ragione che senza di ESSA i Match non Iniziano Proprio :) (per gli spioni di Spyfu e per chi utilizza i loro servizi,se dovessero avere errori nelle strutture data,rimpiangeranno anche "gli Ugly Days" ,legati al Keywords Stuffing e tantomeno arriveranno ai "tradizionali 200 Fattori":)

E' la sintesi estrema e reale dei valori effettivi :)


Deriva dal TFD Statcounter e la posizione è la stessa indicata all'interno del 4° Stats Base ,denominato da questa pubblicazione MileContest in onore della protagonista di questo 73° RF:)
Esistono tantissime domande e ho scelto la piu' curiosa:hanno chiesto alla Queen degli Stats se utilizza dati di CIA Internet nel Global Stats:)
La risposta è nell'evidenza (i dati CIA sono vaghi ed inconsistenti:) ,ed è gia' una posizione "difficile da sostenere" ,pero' i TFD sono tutti TOO SMART e quindi se affermano dei Contenuti ,hanno dei fatti concreti a supportarli:) (gli idioti possono affermare solo cazzate:)

Se fossero anonimi,vengono immediatamente eliminati e sopratutto,per i Click fraudolenti ,occorre attivare anche i dati delle Ads,per evitare di eliminare altri dati:)
 Sempre da Unnatural Developer, a differenza delle apparenze,questa è la posizione piu' semplice da identificare:)
Sempre da Unnatural Developer, a differenza delle apparenze,questa è la posizione piu' semplice da identificare:)
Si seguono gli ISP (nel Milestone sopra sono sistemati anche gli User Agent dei browsers utilizzati,uniti ai rispettivi indirizzi pubblici) e per vedere se è un Bot o un Crawlers ,è sufficente vedere se hanno i codici Javascript abilitati e non occorre "un grande impegno per farlo" ,perche' i codici Javascript,nelle varie posizioni dei Content,coproono il 100% e quindi lo sforzo è minimo ,perche' i Bot e i Crawlers non possono abilitare nessun codice Java,semplicemente perche' non li possiedono:)
Si seguono gli ISP (nel Milestone sopra sono sistemati anche gli User Agent dei browsers utilizzati,uniti ai rispettivi indirizzi pubblici) e per vedere se è un Bot o un Crawlers ,è sufficente vedere se hanno i codici Javascript abilitati e non occorre "un grande impegno per farlo" ,perche' i codici Javascript,nelle varie posizioni dei Content,coproono il 100% e quindi lo sforzo è minimo ,perche' i Bot e i Crawlers non possono abilitare nessun codice Java,semplicemente perche' non li possiedono:)
Tutto questo è solo una piccola posizione di Unnatural Developer Dati Now,perche'il suo vero inizio è il Natural Contest eai Dati reali e ai valori effettivi,occorre prima arrivarci e togliendo anche "Analysis e Analytics",restano solo i contenuti di Unnatural Developer Dati Now a fornire le vere indicazioni:)

Dopo la presentazione,iniziano i MileContest:)
Uniti agli "Ugly Days del Keywords Stuffing" per i "presunti spioni di Spyfu",l'inizio poteva essere solo il Keyword Difficulty:)

Sono "pensieri profondissimi" ,ed è legittima una domanda:)
Come si fa' a trovare le parole giuste,Spyfu?:)
Semplicemente occorre il Keywords Stuffing e i "veri Ugly Days" ,sempre di Spyfu ,non sono affatto terminati,perche' occorre applicare gli "Stuffing delle proposte complessive" e solo ESSI,permettono di trovare le Right Keywords:) (sono i Copied dei Main Content e solo loro determinano le "Parole Giuste" e la loro assenza,è capace di trasformare gli "Ugly Days in Years" all'Infinito:)

Sempre tratto dal "Keywords Difficulty" ,esistono "anche i pensieri profondi sopra":)
Ovviamente si dovrebbero inserire tutti i contesti,pero' il metodo del MileContest ha una posizione ragionevole, ed è lastessa della pubblicazione protagonista di questo 73° RF e il suo Milestone è nato "per comprendere le teste operative dei gestori dei domini" e questo permette di rendere semplice prevedere "quali siano gli sviluppi operativi":)
E' sufficente lo snippet sopra per comprendere "il valore delle teste operative di Spyfu",unite alle Long Tail Keywords:)
Sono capaci,secondo Spyfu e tantissimi altri ottimizzatori ,di trasformare "Le Low Quality in High" e hanno dimenticato la cosa piu' importante e sono i termini effettivi che li contengono e non vengono menzionati nemmeno nella pubblicazione completa:)

E' sufficente sistemare 1 solo elemento del Natural Contest ,ed è la Quantita' eilriferimento sono le proposte complessive e l'applicazione del Keywords Stuffing è del tutto irrisoria,perche' i Match riguardano tutte le pubblicazioni presenti in ciascun dominio e gli eventuali conflitti presenti,non eliminano soloi termini di 1 pubblicazione ,ma tutte le presenze dei conflitti e solo al termine dei match si "calcolano gli Amount":)
Cioe' potrebbero esistere contenuti con "Quantita' Soddisfacenti"(l'average è intorno ai 2000 termini effettivi) ,pero' se esistono decine di conflitti ,i termini vengono eliminati e solo quello che resta forma l'Amount e il valore non riguarda 1 sola pubblicazione,ma tutte quelle in conflitto e quindi è possibile eliminare le Long Tail Keywords,senza nemmeno inserirle,semplicemente perche' sono eliminati i termini effettivi che li contengono e la cosa puo avvenire anche tramite pubblicazioni completamente diverse rispetto ai contenuti specifici:)
 Autocmplete Partial Content Brain Stone
Autocmplete Partial Content Brain Stone
Molto probabilmente quest'altra posizione "sara' inflazionata per quante presenze esistono":)
E' il modo per ricercare le Long Tail Keywords stesse ,ed è una "bufala colossale",semplicemente perche' non esiste nella realta':)

A questo occorre aggiungere anche la semplice logica,perche' se fosse cosi' facile avere le Long Tail Keywords,nessuno pagherebbe i servizi degli ottimizzatori,compreso i costi di Spyfu:)
 I passaggi precedenti forniscono un ottima indicazione "sul livello del servizio" e ovviamente non è nemmeno gratuito:)
I passaggi precedenti forniscono un ottima indicazione "sul livello del servizio" e ovviamente non è nemmeno gratuito:)
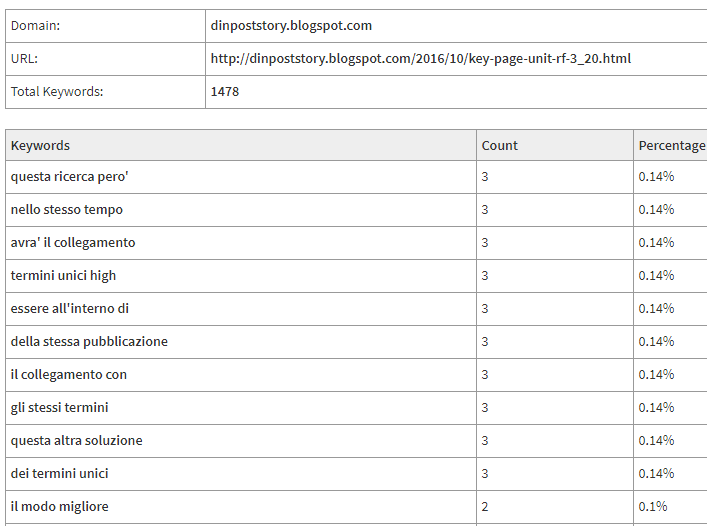
How Much Cost Idiots Service 1 AR
E' un altra pagina dei Brain Stone e la protagonista è proprio Semrush e fornisce un ottima prospettiva su quali siano i costi reali,rispetto a quelli pubblicizzati:)
Questa è la 2° pagina per i costi dei servizi:)E' un altra pagina dei Brain Stone e la protagonista è proprio Semrush e fornisce un ottima prospettiva su quali siano i costi reali,rispetto a quelli pubblicizzati:)

Sempre attraverso il Brain Stone è possibile proseguire nella linea del MailContest:)
Altre posizioni da MileContest sono all'interno di "Opinion vs Data":)Qui sono sistemate le strutture degli Snippet stessi
E'il modo piu' giusto per festeggiare la 73° pubblicazione dei Run Forever e grazie al suo Milestone del 2016 ,è arrivato il MailContest nel 2020:)
le posizioni saranno anche nei Just Time e nei Natural Contest e grazie al nuovo TFD Trastradius ci sara' anche una fantastica novita,unita al Business stesso e quindi alle categorie a cui appartengono.
Prendendo come esempio Spyfu e ISpionage,le loro collocazioni effettive sono all'interno dello Small Business e poi esiste il Middle e i contenuti piu' interessanti li avranno le aziende in Enterprise:)
Per il momento ne ho viste solo alcune e il motivo dell'interesse è semplice, perche' agli Enterprise è molto difficile "raccontare cazzate" e quindi,i loro contenuti , formeranno l'unione ideale con quelli dei MileContest:)

Ovviamente è solo un acronimo e l'interesse nasce dal livello bassissimo dei suoi contenuti e sopratutto da coloro che utilizzano i suoi servizi:)
Per la nuova MailContest rappresenta "la manna dal cielo" ,nel vero senso delle parole, perche' la posizione (insieme agli altri eventuali seo Enterprise presenti) è la migliore possibile ,per evidenziare i valori reali del Contesto Online:)
Natural Contest Finance Airline 3
Il motivo è nei contenuti collegati sopra e le categorie sistemate,forniscono la migliore evidenza per i MailContest:)
Il senso è molto semplice,perche' è la posizione piu' difficile per raccontare cazzate nel Contesto Enterprise e inizia con i costi dei servizi e in genere,non vengono pubblicizzati,ma derivano da accordi privati,tra le aziende i vari ottimizzatori.
Il motivo è nei contenuti collegati sopra e le categorie sistemate,forniscono la migliore evidenza per i MailContest:)
Il senso è molto semplice,perche' è la posizione piu' difficile per raccontare cazzate nel Contesto Enterprise e inizia con i costi dei servizi e in genere,non vengono pubblicizzati,ma derivano da accordi privati,tra le aziende i vari ottimizzatori.
L'unica cosa certa deriva dal fatto che i costi dei servizi sono molto elevati e per le categorie Finance e Airline ,esistono anche dei limiti elevatissimi nelle differenze dei Rating (i primi 3 Top hanno il massimo assoluto e tutto il resto si divide il rimanente 7%:) e quindi l'unione dei contenuti con i MileContest,sara' proprio fantastica,perche' non esiste evidenza migliore per comprendere quali sono i valori dei dati reali:)

Per il momento non esiste proprio e ovviamente è presente il termine "Milestone" e quindi la pubblicazione festeggiata del 73° RF potra' avere anche il primato di essere stata la prima ad aver avuto il nuovo termine:)




Questa è la posizione del Trasparency Reports e per il contesto descritto,è gia' una collocazione straordinaria:)
Cioe' è arrivata attraverso gli archivi dopo 4 anni e i Tags e gli archivi stessi (insieme a tante altre cose) non sono abilitati:)
Questo si aggiunge al contesto del Taken Din Colors Five e sono le colossali dimensioni, per 1 solo autore in 1 solo spazio e se non esistono i Tags abilitati negli archivi,significa che sono state le Sitemap a permettere tutti i Match e quindi nessun Internal Links OUT,puo essere stato di aiuto e di conseguenza i Match sono stati complessivi:)
Le posizioni le sistemero' nella pagina A di questo 73° RF e aggiungero' anche altri dati particolari,uniti alle Strutture Data e posso anticipare che saranno assai differenti rispetto alle posizioni di Spyfu:)


L'arco temporale è sempre quello della pubblicazione protagonista di questo 73° RF e solo queste posizioni permettono di fare un altro anticipo rispetto ai dati che avra' la pagina A e riguardano le Strutture Data unite anche ai Check Fact e la posizione è una novita' fantastica,perche' è capace di rendere i dati che sto' inserendo ,"assai relativi", nonostante la loro posizione del tutto negativa, per la semplice ragione che le Strutture Data,unite anche ai Check Fact ,rendono del tutto inutile conoscere "gli eventuali attacchi",semplicemente perche' non ci saranno "contenuti d'attaccare":)
Applicata questa nuova posizione al MileContest,rende tutto meraviglioso e il miglior esempio,è gia' sistemato nei passaggi precedenti:)
il riferimento è all'incompatibilita' tra i Fact Check e le cazzate di Spyfu e di conseguenza diventa pertinente anche il Brain Stone,perche' i sassi nel cervello sono reali:)
 Tornando agli avvisi per i "siti compromessi" questa è la percentuale di reinfettati
Tornando agli avvisi per i "siti compromessi" questa è la percentuale di reinfettati
I dati hanno come riferimento solo i domini che "hanno pulito gli spazi" e poi sono stati reinfettati e anche in questo Caso sono esclusi gli eventuali spazi collegati in Dofollow. Sempre con lo stesso arco temporale,dal Trasparency Report di Google ,queste sono le violazioni dei Copyright ,solo per 1 termine e ne ho scelto uno del recente Just Time.
Sempre con lo stesso arco temporale,dal Trasparency Report di Google ,queste sono le violazioni dei Copyright ,solo per 1 termine e ne ho scelto uno del recente Just Time.
I dati hanno come riferimento solo i domini che "hanno pulito gli spazi" e poi sono stati reinfettati e anche in questo Caso sono esclusi gli eventuali spazi collegati in Dofollow.
L'arco temporale di riferimento è quello della pubblicazione protagonsta di questo 73° RF.
Occorre fare attenzione ai termini uniti ai dati,perche' quelli sopra "derivano solo dalle Information Submitted" e cioe' sono coloro che pensano di "avere diritto al copyright" (Owners) e attraverso degli operatori ,inviano le richieste di violazione a Google (sono in pratica i contestatori presenti nei Just Time e Google è il principale Recipient:)
E' sufficente che i termini siano "un po' rilevanti" per trovare "tantissimi contestatori" e questa posizione è importante,perche' esistono i Delisting di Google stessa e le violazioni di Copyright arrivano,senza la necessita' di avere alcun contestatore:)
Ho inserito questa posizione,per evidenziare meglio i dati uniti a "Security" e il senso è molto semplice,perche' i Delisting di Google sono assai piu' elevati,rispetto a quelli gia' notevoli dei contestatori:) Solo nel numero dei domini,formano 77 pagine e sono presenti 10 indirizzi ciascuna e ognuno ha vari URL in violazione,uniti solo a 1 termine ,ed essendo un URL puo essere sistemato solo nel nome delle pubblicazioni o degli Anchor Text e quindi figurarsi cosa sono le violazioni nei contenuti oggettivi:)



Se esiste l'INDEX dopo 4 anni alle condizioni della pubblicazione protagonista di questo 73° RF ,solo i suoi content oggettivi hanno potuto risolvere i Match,perche' la velocita' del Loading è proprio da escludere:)



Gli Engines e lo strumento delle verifiche sono capaci di leggerli i Text e i Links in Hiden e questo procura l'eliminazione delle pubblicazioni,senza passare nei duplicati.

debbono possederlo anche gli spazi collegati e tra di essi,nella pubblicazione di OCT 2016,esiste anche il dominio del Real Madrid:)

Esiste solo una modifica da fare,ed è unita al "livello confidenziale" ,rispetto al fatto che la leggibilita' "è un fattore importante":)
Nella realta' non è presente nelle linee guida e il motivo è semplice,perche' l'importanza dei gradi sopra,diventa reale sei contenuti appartengono al dominio specifico:)
la semantica unita ai dati ha lo stesso percorso e ilsuo elemento diretto ènell'Automated Index ein realta' non ha nulla di automatico ,perche' i suoi ottimi gradi vanno uniti agli altri e la qualifica migliore ,si ha nel rapporto con il Gunning Fog Score:)
