https://dinpoststory.blogspot.com/2024/11/search-egregious-violation-2-rf-10d.html
Demonstrate Juice Archive Data è il nome scelto per questo FGL DEC 2024 e saranno anche i termini delle altre pubblicazioni che arriveranno al 10° anno di questo dominio,naturalmente unendo numeri progressivi fino al traguardo di FEB 2025:)Esistevano tanti termini da poter scegliere per festeggiare l'incredibile evento,pero' grazie alla pubblicazione precedente,è arrivato "Direttamente il Suggerimento" dalla Fantasia Infinita del Supreme Case Creator e l'aspetto straordinario deriva dal fatto che il "Contesto Sovrannatural" è anche Vero,ed è indirettamente descritto proprio nella pubblicazione precedente:)E' sufficente vedere la pubblicazione protagonista del 2° RF 10D collegata sopra,ed è facile trovare tanti Multi fact Check,ad iniziare dalla prima immagine,dedicata agli strumenti dei rilevamenti di base e la data originale degli scritti,della pubblicazione protagonista del 2° RF 10D è JAN 2019,ed è facile l'unione con tutti gli sviluppi che sarebbero arrivati dopo (esattamente 11 mesi dopo grazie agli Holy Grail del Fantastico Statcounter:) e ho citato solo una posizione dei Multi Fact Check e il motivo è quello sotto:)La sezione è solo un esempio,per comprendere come è nata questa pubblicazione e cioe' dopo aver scelto il nome di Demonstrate Juice Archive Data per FGL DEC 2024,è arrivata l'idea di unirla direttamente ai domini presenti in questo DEC 2024 e il motivo dell'unione è molto semplice,perche' il Demonstrate Juice Archive sono i Dati Veri e gli spazi presenti a DEC 2024 sono tra i migliori possibili per evidenziare l'unione e contemporaneamente esiste anche l'evidenza dell'opposto:)https://dinpoststory.blogspot.com/2024/11/search-egregious-violation-2-rf-10d.html
Questa è l'Evidenza dell'Opposto e naturalmente la "Posizione è Variabile",perche' i rilevamenti di base hanno valore solo grazie alla presenza del Demonstrate Juice Archive Data e i domini presenti a DEC 2024,renderanno molto semplice comprendere queste posizioni,perche' non esiste nessuna possibilita' che accada l'opposto e cioe' che siano "i rilevamenti di base " a determinare i valori del Juice Archive Data e per evidenziare il contesto ho scelto come esempio il dominio ACC sistemato sopra,ed è quello del Network delle Litigation,ed è facile l'unione dei Dati Veri,perche' solo il Demonstrate Juice Archive Data è capace di rendere Immuni gli Autori dei Contenuti:)
Il dominio ACC possiede l'esempio appena citato unito ai Dati Veri e poi esiste anche l'esempio operativo per creare i contenuti di questa pubblicazione e cioe' i domini che hanno partecipato a FGL DEC 2024,oltre ai dati specifici,possiedono dei contenuti loro stessi e naturalmente non sono presenti in tutti i domini che hanno partecipato a FGL DEC 2024,pero' ne sono tanti ad avere i Content diretti e il motivo per cui esiste questa descrizione è nei dati sotto:)
Sono gli incredibili dati di Immunity Egregious Violation Unique Concern formata da 14923 termini effettivi.
Entrambe le posizioni e qualsiasi altra pubblicazione del dominio sono nate dal Write Naturally e nella pubblicazione precedente esiste proprio l'unione da cui derivano i termini che festeggeranno i 10 anni di questo dominio ed è Demonstrate Juice Archive Data:)
Tutte le pubblicazioni nascono dal Write Naturally e solo la Casualita' ha permesso che esistessero i dati sopra,perche' durante la scrittura effettiva sono in pratica Ignoti e l'unico riferimento sono "le dimensioni fisiche" dei Content:)
La descrizione dei dati è unita a un motivo oggettivo,perche' le dimensioni del 2° RF 10D permettono di arrivare molto vicini a 4,5 Milion Words in 1 sola posizione (mancavano 4559 termini:) e il traguardo è ampliamente superato,perche' mentre sto' scrivendo questo passaggio,esistono gia' i contenuti dedicati ai vari domini che hanno partecipato a questo FGL DEC 2024 e sono uniti proprio proprio a DEMONSTRATE JUICE ARCHIVE DATA e grazie alle sue dimensioni i 4,5 Milion Words sono ampliamente superati,prima di scrivere questi passaggi:)
Tra un po' ci sara' la proclamazione ufficiale e indirettamente i festeggiamenti saranno nei dati dei domini che hanno partecipato a FGL DEC 2024 e si comprendera' facilmente il valore dei dati,grazie sopratutto alla notevole presenza dei SIZE ,spesso in opposizione al peso dei contenuti effettivi presenti:)
I festeggiamenti dei 4,5 Milion Words in 1 solo dominio per 1 solo autore effettivo (naturalmente senza considerare la categoria specifica dei Content) hanno poi un contesto speciale,ed è nei dati sopra:)Era MAR 2018,ed esistevano 17,1 MB in File XML (18 MB su disco) in questo dominio e l'importanza è molto semplice,perche' i dati attuali sono iniziati proprio da File XML,pero' 1 anno dopo e cioe' a MAR 2019:)
https://dinpoststory.blogspot.com/2024/07/status-limiting-illogical-sense-main.html
Questa è la posizione piu' bella per comprendere il valore dei Dati,grazie all'opera completa del TFD Marcel Proust,ed ha dimensioni anche maggiori rispetto all'originale,perche' esiste anche un introduzione specifica dedicata all'autore della traduzione in lingua inglese,rispetto a tutta l'opera del TFD Marcel Proust e le impostazioni di Web Server 19 sono esattamente uguali a questo dominio,grazie al fatto che non esiste nessuna abilitazione e sono presenti solo i codici indispensabili:)Nei primi 3 anni di questo dominio,i contenuti scritti hanno dimensioni incredibili e gia a MAR 2018 sono maggiori,rispetto a tutta l'opera del TFD Marcel Proust,mentre i Calculator ufficiali sono arrivati esattamente 1 anno dopo,a MAR 2019,sempre attraverso file XML e l'inizio dei calcoli aveva una dimensione assai minore rispetto a quella del TFD Marcel Proust:) (sono iniziati da circa 1,6 Milion Words:) https://dinpoststory.blogspot.com/2024/11/search-egregious-violation-2-rf-10d.html
L'importanza dei dati sistemati deriva dalla posizione sopra e il riferimento è alla sezione evidenziata,perche' i SIZE effettivi sono al suo interno e le altre posizioni sono escluse e ne sono 40,per ogni pubblicazione e sono loro a formare gli elementi statici dei Loading e sono facilissimi da individuare,perche' è possibile che esista il Full SIZE o il suo opposto Page Size e in quest'ultimo Caso gli elementi strutturali sono evidenti,mentre nel Full Size sono assenti e al massimo sono presenti dei termini effettivi,uniti alle varie pubblicazioni e formano solo dei Duplicati (sono i Common Content).Sara' facile comprendere il valore di queste posizioni nelle descrizioni che avranno i domini che hanno partecipato a FGL DEC 2024,compresi i dati di questo spazio:)Questo è il volume di FGL DEC 2024 e la sua pertinenza rispetto al Demonstrate Juice Archive Data,inizia e termina con i SIZE,semplicemente perche' sono i primi e gli unici ad attivare il Report at a Glance e cioe' se non esistono Content Validi,gli operatori alternativi ai Dati Veri (i simpatici SEV e cioe' i Ricercatori delle Gravi Violazioni) cercano "le scorciatoie per arrivarci",ed è possibile verificarle a "Colpo d'Occhio" (il Report at a Glance è effettivo e non è casuale che sia anche nella prima posizione del Webmaster Topic:) grazie agli "Strampalati Size" Presenti:)Calcolando tutti i pesi extra,rispetto ai Content Effettivi, le selezioni di FGL DEC 2024 sono arrivate a 59,245 MB e li ho definiti SIZE Loading,perche effettivamente esiste l'impatto con il Loading e il contesto è molto Divertente,perche' è VERO che la posizione è importante,sopratutto negli AMP (sono gli acceleratori dei Mobili e formano anche i Primi Device rispetto a qualsiasi traffico) ,pero' debbono esistere anche dei Content Validi,altrimenti gli AMP non servono assolutamente a NULLA:)Quindi il Divertimento nasce dai 59,245 MB,perche' hanno 40 sezioni solo degli HTML Javascript e quindi i dati appena sistemati saranno utilissimi per comprendere gli altri Reports,perche' difficilmente possiedono il peso indicato;è ancora piu' difficile trovare il volume dei contenuti effettivi e per quanto riguarda gli HTML Javascript,tranne 2 domini,compreso il presente in Page Size,tutti gli altri sono in Full Size e cioe' non esistono gli elementi statici e quindi possono essere solo i codici ad avere la larga maggioranza dei Pesi,ed è facile intuire che sono in ABUSO,rispetto all'operativita' normale,perche' i codici sono dedicati tutti alle "strategie alternative" rispetto ai Dati Veri:) Per avere i Dati Veri dei SIZE ho scelto la pubblicazione piu' vicina all'Average dei Pesi per FGL DEC 2024 di questo dominio.Qui è sistemata la pagina completaL'Average dei SIZE è la prima pubblicazione della pagina e il suo arco temporale è DEC 2019.https://dinpoststory.blogspot.com/2019/12/just-time-detect-supreme-case.html
Questo è il file HTML che determina il Page SIZE e cioe' i contenuti della pubblicazione specifica,insieme a tutti gli elementi statici dello spazio fisico in cui è sistemata la pubblicazione.Questo è l'inizio dei codici e sopratutto dei contenuti effettivi della pubblicazione piu' vicina all'Average di FGL DEC 2024 per questo dominio.
https://docs.google.com/document/d/1KfAUdoi_cSNfxiNmd6mBIP3Cxf9a1qNVihjDqsl54_Q/edit?tab=t.0
Grazie a Google Docs esistono i codici completi,insieme ai contenuti effettivi ed è facile notare che sono quest'ultimi a prevalere nei SIZE e la scelta operativa è anche LOGICA,perche' non esiste nessuna strategia alternativa,per arrivare ai Dati Veri:) Se un autore dovesse scegliere strategie alternative,è indispensabile prima avere Content Validi e se dovessero esistere significa che l'autore non è Idiota (è sufficente solo vedere il percorso per arrivarci e non esiste nessuna possibilita' di farlo attraverso Brain Idioti:) e quindi non scegliera MAI le strategie alternative,semplicemente perche' l'autore "ha una limitata presenza di Spam" e cioe' non è Idiota:)
Questo è il peso effettivo della pubblicazione piu' vicina all'Average dei SIZE di FGL DEC 2024 per questo dominio e rispetto alle 205 pubblicazioni presenti nella selezione si arriva a 8,815 MB,ed è il peso effettivo che partecipa al Size generale e un indicazione è quella di MAR 2018 e i suoi Pesi sono formati proprio dal dato appena sistemato e l'unica differenza è formata dal FileType:gli 8,815 MB sono in HTML,mentre quelli di MAR 2018 sono in file XML e cioe' compressi:)
Questo è un esempio rispetto ai contenuti che seguiranno e il protagonista è il Fantastico dominio IONOS,strettamente in Full Size e la domanda sorge legittima e cioe' "Cosa ci faranno gli operatori con la montagna di codici?":)La risposta la fornisce l'Holy Grail TFD Google Merchant e forma in pratica un Report at a Glance e cioe' "a cosa puo servire la montagna di codici",sistemati in dei contenuti scarsi gia' in proprio:)Serve a Decidere gli utenti (sono i rilevamenti di base realizzati attraverso gli Invalid Traffic:) e sopratutto gli operatori alternativi ai Dati Veri,immaginano di Decidere il Business:)Questo è il FRAME Effettivo che determina la presenza di SIZE dedicati ai codici e quindi tutte le strategie alternative hanno un unico scopo reale,ed è quello del Circumventing System e cioe' il "Search Egregious Violation per antonomasia" e occorre ricordare agli operatori specifici che anche alle Gravi Violazioni,è indispensabile prima Arrivarci e utilizzando solo il Report at a Glance,è sufficente "Un Colpo d'Occhio" rispetto ai SIZE dei codici,ed è possibile dire Addio anche alle Gravi Violazioni,perche' sono molto ,piu' elevate le probabilita' di essere eliminati prima:) 
Esattamente 1 anno fa' è arrivata anche "un altra risposta",rispetto alla "montagna di codici" e del suo utilizzo effettivo ed è l'AVOID piu' Indigesto per tutti gli operatori alternativi e cioe' non debbono esistere Unnatural Links (Creating Complex Web of Navigation:) e cioe' Link Building,ed è presente anche l'indicazione esatta per non essere in penalita' e sono 20 Clicks dalla HomePage ,ed è decisamente difficile trovarli negli operatori alternativi e la presenza di IONOS (è un SEV anch'esso,forse a sua insaputa:) serve proprio per festeggiare 1 anno,rispetto al Fantastico e Divertente AVOID e la posizione specifica ci sara' tra un po',proprio nel passaggio dedicato a IONOS all'interno dei domini che hanno partecipato a questo FGL DEC 2024 e occorre solo ricordare che la posizione di IONOS è unita alle sue OFF Pages ,attraverso il "Link Building sostenibile" e per essere tale è indispensabile avere 20 Clicks e rispetto agli operatori alternativi ai Dati Veri,è un dato da Science Fiction,perche' arrivare a 20 Clicks,per gli operatori SEV è gia' un impresa (dovrebbero fare una coalizione tramite una decina di domini sommati insieme:) e sopratutto perche' ad essere festeggiata è anche la posizione sotto:)

Questa è un altra posizione da festeggiare per gli Autori Onesti e a differenza delle apparenze ne sono tanti:)
Provide Appropriate Amount e l'AVOID è dedicato agli Insufficent Content e naturalmente la posizione è sempre esistita,ha avuto anche tanti Developers,pero' MAI Prima avevo visto mil contesto specifico festeggiato,ed è sufficente solo elencarlo per comprenderlo:)
La posizione è Google Search Central;la sezione è DOCUMENTI e la posizione piu' importante,non è quella dei SEO (attualmente SEV:) ma quella precedente,ed è Google Search Works e significa semplicemente Fundamental Search e cioe' la base operativa del piu' importante Engine che esista e la descrizione è altrettanto semplice e arriva attraverso gli Step delle Ricerche e in pratica ne esiste UNO SOLO,ed è quello di vedere i Duplicati in tutto il Web e se i dati sono positivi,è possibile continuare nella verifica delle ricerche:)
Da questo contesto nasce l'AVOID per gli Insufficent Content e il riferimento degli Amount,sono i contenuti rimasti immuni dai Match e i conflitti sono generali e cioe' prima vengono verificati quelli interni ai domini e poi quelli globali e i dati che restano formano i Sufficent o gli Insufficent dei Content Effettivi.
La posizione è la piu' importante in assoluto e da sola è capace di festeggiare qualsiasi AVOID,compreso anche quello di avere almeno 20 Clicks dalla Homepage,perche' occorre ricordare agli operatori alternativi ai Dati Veri "che i loro AMATI Link Building" e qualsiasi altro collegamento,è formato esclusivamente dai termini effettivamente scritti,tranne naturalmente quelli in Duplicato e quindi,per paradosso,è indispensabile anche un notevole impegno solo per Arrivare alla Gravissima Violazione degli Unnatural Links,semplicemente perche' esiste l'Abuso anche rispetto ai termini utilizzati per creare i Links:) Quindi l'unico ruolo effettivo dei SEV è quello del Divertimento,grazie sopratutto ai simpatici utenti che li pagano pure!:)
Grazie al ruolo effettivo dei SEV è cioe' il Divertimento (è sufficente solo immaginare il costo economico sostenuto dagli utenti per alimentare il Divertimento stesso:) è possibile festeggiare anche le Top Cause dell'Invalid Traffic,perche' è arrivato anche il Third Party al suo interno:)Naturalmente non è il Third Party il vero Divertimento,ma il contesto originale da cui deriva e cioe' il Site Reputation Abuse (è un Self Serving Data della Reputation stessa:) e naturalmente è solo una Millanteria,perche' solo immaginare di fornire vantaggi ad altri domini,restando Immuni,nel contesto online,è indispensabile avere un Idiozia elevatissima e quindi solo per Logica,non puo esistere proprio nessuna Reputation,grazie al principale elemento delle Top Cause dell'Invalid Traffic,ed è l'Original;Unique e Content Value e per arrivare ai loro dati,occorre l'AVOID completo rispetto all'Idiozia e solo per Logica,non lo possono fare gli operatori che alimentano il Site Reputation Abuse,perche' togliendo l'Idiozia,non resta NULLA nel Loro Brain:)A Certificare il contesto,è la posizione oggettiva stessa del Third Party,perche' è sistemata nei Discover e cioe' è l'inizio del percorso per arrivare ai Dati Veri,ed è sufficente solo questa posizione per essere nelle Top Cause degli Invalid Traffic e quindi figurarsi cosa sono i livelli degli Step,uniti al percorso successivo ai Discover e se i risultati fossero positivi,significa solo poter iniziare i Match e forma il primo STEP della Fundamental Search,ed è quello di vedere se esistono Duplicati in tutto il Web e l'operazione è valida solo per una verifica,rispetto a ogni singolo dominio e se dovessero esistere anche le successive,verra prima verificata "l'originalita' dei contenuti" (significa che non debbono esistere modifiche rispetto alle posizione note precedenti:) e se i dati fossero positivi,si potra avere anche i nuovi Match rispetto alle eventuali nuove pubblicazioni. Le posizioni citate hanno un valore generale,rispetto all'operativita delle ricerche,nei confronti di qualsiasi categoria in cui siano sistemati i contenuti e poi esiste la posizione piu' importante per attivare le operazioni di ricerca stesse,ed è quella del Demonstrate Juice Data Archive e cioe' le Proposte Complessive e sono esclusivamente LORO a determinare i Dati Veri e sono facili anche da individuare,grazie all'aiuto dei SIZE e quest'ultimi rendono anche semplice individuare le posizioni degli Invalid Traffic e il Third Party è solo un esempio,perche' tutte le altre operazioni alternative,difficilmente arrivano al Discover,ed è sufficente solo questa posizione per essere negli Invalid Traffic e quindi figurarsi cosa significa fare tutto il percorso completo,per arrivare ai Dati Veri:) https://dinpoststory.blogspot.com/2024/10/egregious-violation-super-partes-logic.html
Le posizioni sistemate sono unite al Demonstrate Juice Archive Data effettivo,ed è quello dell'Holy Grail TFD Google Search Console:)Nella pubblicazione collegata sopra esistono delle descrizioni,insieme al Last Update dei reports stessi,ed è 14/10/2024,mentre il prelievo è arrivato alcuni giorni dopo.Nella stessa pubblicazione e naturalmente con gli stessi Update,esistono anche i SIZE insieme ad altre descrizioni e la piu' importante è la formazione dei SIZE stessi,perche' non sono calcolati nei Pesi i Refresh e cioe' le pubblicazioni note precedenti,semplicemente perche' i SIZE sono stati gia' prelevati e quindi restano solo i Discover e sono davvero fantastici da unire agli Invalid Traffic,perche' spesso il Peso maggiore appartiene ai codici:)
Le posizioni sistemate servono per arrivare al piu' recente Update ed è indicato nella data dell'immagine e poi esiste anche la data del prelievo e sono tantissime le selezioni,ed è impossibile sistemarle in questa pubblicazione,tranne per 1 fantastica posizione,ed è quella sotto:)
E' presente il Reccomended Unique Concern e cioe' FGL SEP 2024,insieme alla pubblicazione di AUG 2024 e il contesto è straordinario,perche' la posizione è quella del Refresh e cioe' le pubblicazioni sono gia' NOTE,ed essendo relativamente recenti,significa che per essere nel Last Update dell'Holy Grail TFD Google Search Console,debbono esistere almeno 2 Verifiche e normalmente avvengono ogni 2 o 3 mesi,pero' l'arco temporale è generico,perche' le Verifiche avvengono a totale discrezione degli Engines e quindi ne possono esistere anche un numero piu' elevato,rispetto a quello generale indicato sopra.
E' sicuro che questo è stato il percorso di FGL SEP 2024 e non è una pubblicazione qualsiasi,perche' è la prima in dimensioni di questo dominio e se ha il Refresh,in pratica a 3 mesi dalla sua pubblicazione,significa che gli altri contenuti sono stati validissimi e cioe' sono degni del Demonstrate Juice Archive Data,perche' non esiste nessun altra possibilita' di sostenere l'impatto di una pubblicazione da quasi 20K termini effettivi,all'interno di un dominio che ne ha oltre 1400 e solo il Demonstrate Juice Archive Data è capace di permetterlo:)
Per questo motivo,ho scelto la posizione di FGL SEP 2024 per festeggiare l'arrivo dei 4,5 Milion Words in 1 sola posizione e spero che questa pubblicazione abbia lo stesso percorso:)
E' il Din Fantasy Calculator,unito alle equivalenze degli archi temporali a rendere semplicissimo il senso operativo di Demonstrate Juice Archive Data,ed è l'unica posizione ad essere unita ai Dati Veri:)
https://dinpoststory.blogspot.com/2024/05/size-solemn-quality-intelligence-score.html
A MAY 2024 esistono le descrizioni per arrivare al calcolo dell' equivalenza temporale dei dati (al suo interno esiste anche il collegamento per MAR 2024 con altre descrizioni) e l'aspetto straordinario,nonostante i dati delle equivalenze temporali siano elevatissime,è unito al fatto che non è presente nessun elemento del Din Fantasy Calculator,ad iniziare dall'Average dei Contenuti stessi:)Ad arrivare al traguardo effettivo dei 4,5 Milion Words,sono stati i contenuti sotto,dedicati ai domini che hanno partecipato a FGL DEC 2024 e al primo Demonstrate Juice Data Archive:)
 Stanford AI Assente FGL DEC 2024
Stanford AI Assente FGL DEC 2024
 Assente DEC 2024 Status Code 4036PUB2
Assente DEC 2024 Status Code 4036PUB2
 IAB DEC 2024 142 PUB 61% UN 1888 AV 62 ILA FULL SIZE 165 KB Average(351 ms Average Loading)
IAB DEC 2024 142 PUB 61% UN 1888 AV 62 ILA FULL SIZE 165 KB Average(351 ms Average Loading)
268096 VOL. VS 23,340 MB Full Size (- 1 MB NOV 2024)
 184 PUB 28% UN 1382 AV 48 ILA FULL SIZE 212 KB Average(387 ms sono i millesimi di secondo per i Loading sempre in Average)
184 PUB 28% UN 1382 AV 48 ILA FULL SIZE 212 KB Average(387 ms sono i millesimi di secondo per i Loading sempre in Average)
254288 VOL. VS 39,008 MB Full Size (- 240 KB vs NOV 2024)
 224 PUB 35% UN 1040 AV 52 ILA 229 KB Full SIZE (635 ms Average Loading)
224 PUB 35% UN 1040 AV 52 ILA 229 KB Full SIZE (635 ms Average Loading)
232960 VOL. DEC 2024 (165804 Vol. NOV 2024)67156 termini è la differenza 51,296 MB DEC 2024 Vs 36,244 MB NOV 2024 e il dominio è in Full SIZE e la differenza dei Pesi è formata da 15,052 MB,per avere 67156 termini nelle differenze dei volumi:)E' un grande esempio a favore dell'operativita del Report At A Glance:) 195 PUB 43% UN 599 AV 57 ILA FULL SIZE 83 KB (1271 ms Average Loading)
195 PUB 43% UN 599 AV 57 ILA FULL SIZE 83 KB (1271 ms Average Loading)
116805 Vs 16,185 MB
 MAY 2024 245 PUB 91% UN 4937 AV 159 ILA FULL SIZE 51 KB Average DEC 2024 248 PUB 89% UN 4936 AV 152 ILA FULL SIZE 51 KB AV SIZE 321 ms è l'Average dei Loading
MAY 2024 245 PUB 91% UN 4937 AV 159 ILA FULL SIZE 51 KB Average DEC 2024 248 PUB 89% UN 4936 AV 152 ILA FULL SIZE 51 KB AV SIZE 321 ms è l'Average dei Loading
1224128 VOL. DEC 2024 (962844 Vol. NOV 2024) e la differenza in 1 sola selezione è formata da 261284 termini effettivi e in tanti casi è maggiore all'intero volume,rispetto ad alcuni domini presenti a FGL DEC 2024:)12,648 MB è stato il Peso a DEC 2024 per la selezione dell'enciclopedia astronautica Vs 9,594 MB di NOV 2024 e la struttura del dominio è in Full SIZE.EX ACloudGuru.ComDEC 2024 162 PUB 49% UN 1352 AV 69 ILA Full Size 189 KB Average (944 ms AV Loading)
DEC 2024 219024 VOL. (295400 Vol. NOV 2024) ,quindi la differenza è formata da 76376 termini in meno rispetto alla selezione precedente,ed è un dato elevatissimo,rispetto agli Average del contesto online,senza la necessita di unire gli elementi del Din Fantasy Calculator,perche' solo grazie alla differenza dei volumi,applicando l'Average che ha avuto il dominio specifico,se i dati fossero nel contesto tradizionale dei contenuti,si avrebbe il dato sotto.Solo la differenza dei volumi,rispetto a 2 selezioni,rispetto al contesto tradizionale dei contenuti,utilizzando solo l'Average,produce il dato sopra,ed è molto importante,perche' rende molto facile comprendere quanto sia difficile arrivare ai Dati Veri e poi esistono tutti gli altri elementi del Din Fantasy Calculator non presenti nei dati sistemati e rende ancora piu' facile comprendere il valore dei reports,per la semplice ragione che gli elementi del Din Fantasy Calculator sono realmente e pienamente operativi nel contesto online e il nome deriva solo dalla simpatia nei confronti degli autori dei contenuti tradizionali,perche' effettivamente gli elementi del Din Fantasy Calculator,per gli autori tradizionali,"sono applicazioni unite alla Fantasia",ed è facile comprenderli,solo attraverso l'Average dei Content stessi:)Tranne il TFD Marcel Proust,non esiste nessun altro autore tradizionale che abbia scritto un volume di contenuti,paragonabile alla differenza sistemata sopra,presente in 1 solo dominio e naturalmente,non è possibile unire al Din Fantasy Calculator "gli amati EDITS" degli autori tradizionali e tantomeno,applicare UNA struttura data ai loro contenuti (il dato della differenza solo per gli average,diventerebbe "elevato a potenza":)
Sono citati solo alcuni elementi del Din Fantasy Calculator e poi,rispetto ai simpatici autori dei contenuti tradizionali,è possibile unire "l'elemento piu' difficile da rendere compatibile" con i loro Contenuti,ed è il Plagiarism,perche' gli autori tradizionali,nonostante la categoria dei loro contenuti (al 90% sono formati da Novelle o Science Fiction e cioe' il Super Easy dei Content,sopratutto grazie al fatto che non hanno Multi Fact Check:),spesso hanno problemi proprio con il Plagio:)Occorre ricordare che gli elementi citati del Din Fantasy Calculator sono tutti operativi e non esiste nulla che sia unito all'IGNORE,compresi i Whitespace e cioe' anche gli spazi bianchi tra i termini,sono NOTI e possono far parte dei Bugs anche loro e non è una posizione simpatica d'avere nei reports:)Quindi la differenza unita al calcolo degli Average,solo per una selezione,rispetto ai contenuti tradizionali,forma il Contesto piu' Ottimista dei reports,perche' se fossero applicati gli altri elementi del Din Fantasy Calculator,il volume sarebbe notevolmente piu' elevato e la posizione è importantissima,perche' fornisce la migliore evidenza rispetto al livello che possiedono i Dati Veri ,ed è facile comprendere anche il suo Opposto,sempre grazie agli elementi del Din Fantasy Calculator:) (è sufficente solo unirlo a qualsiasi operazione alternativa ai Dati Veri e si ha anche il livello esatto dell'Idiozia:)Nonostante i dati sopra il peso a DEC 2024 è maggiore ed è formato da 30,618 MB per tutta la selezione del dominio specifico VS 27,475 MB Full Size ed era il peso di NOV 2024 e cioe' esistono oltre 3 MB in differenza:)
 Computer World 248 PUB 61% UN 2484 AV 72 ILA 205 KB Average Full Size (151 ms AV Loading)
Computer World 248 PUB 61% UN 2484 AV 72 ILA 205 KB Average Full Size (151 ms AV Loading)
616032 VOL. per DEC 2024 VS 661248 Vol. avuto a NOV 2024 e quindi esistono oltre 45K termini in differenza. 50,840 MB è stato il peso a DEC 2024 VS 52,152 MB avuti a NOV 2024 e le posizioni sono tutte in Full Size.Per avere un idea,rispetto alla differenza dei pesi,nei confronti del dominio specifico e qualsiasi altro,un aiuto arriva dal peso sopra,ed ha esattamente le stesse condizioni di quasi tutti gli altri domini (il riferimento è quello in Full SIZE) e sono presenti anche i codici nel peso e per tutta Master Contest WP Page Solemn JUN 2021 360K,il Size arriva a 2,55 MB (2,56 su disco) ed ha tutti i codici operativi che servono realmente e quindi non è abilitato nessun Tags e naturalmente non esistono operazioni alternative,rispetto ai Contenuti Effettivi.https://dinamic1hc.blogspot.com/2023/05/leo-master-contest-wp-page-solemn-jun_5.html
Questa è la pagina e aiutera' tantissimo a comprendere i dati dei volumi e dei Size,perche' esistono le stesse condizioni dei domini in Full Size,pero' sono presenti solo i codici che servono realmente e tutti gli altri,nella migliore delle ipotesi sono Optional:)
Questo è il volume effettivo della pagina Master Contest da 360K e cioe' è assai maggiore anche allo Step massimo di Page Solemn ,ed è questo volume ad arrivare a 2,55 MB e rende facile comprendere cosa significano gli altri dati:)
Ad esempio il dominio appena sistemato (Computer World),ha quasi 2 MB in differenza,rispetto a 2 selezioni e lo Step di Page Solemn è molto utile per ricordare il valore dei Pesi stessi,perche' possiede anche lui dei codici e sono esclusivamente quelli che servono realmente:)Con un peso da 2,55 MB è possibile arrivare quasi a 450K termini effettivi e questo è il dato da ricordare,per qualsiasi reports,perche' se non dovessero esistere i Pesi dei Content,per forza nei Size sono presenti i codici,ed è molto "difficile immaginare" solo immaginare che il loro utilizzo "Sia Appropriato" nei confronti dell'Immunity alle Egregious Violation:) Wikitech Wikimedia DEC 2024 231 PUB 76% UN 1668 AV 61 ILA 3412 Skipped e 3393 sono stati i Disallow da robots txt.Full SIZE 76 KB AV (313 ms AV Loading)
Wikitech Wikimedia DEC 2024 231 PUB 76% UN 1668 AV 61 ILA 3412 Skipped e 3393 sono stati i Disallow da robots txt.Full SIZE 76 KB AV (313 ms AV Loading)389928 Keywords Vol. VS 17,556 MB Full Size
I numeri di Wikiteck hanno piccole differenze rispetto alla precedente selezione,pero' esistono sempre i numeri sopra da unire al Master Contest appena sistemato,per la semplice ragione che entrambi i domini sono dei Full Size e l'unica differenza è unita al fatto che Web Server 19,non possiede 3393 Disallow (Tutti effettivi e reali,ad iniziare dall'abilitazione dei robots txt:) ,presenti in 1 sola selezione,insieme a tutte le altre operazioni alternative,ed è sicuro al 100% che sono loro a permettere l'esistenza di un SIZE da 17,556 MB per soli 389K Keywords:)


Wiktionary DEC 2024 192 PUB 91% UN 5992 AV 423 ILA 2454 Skipped e 2396 sono stati i Disallow e 51 i codici Canonical,sempre tra le pubblicazioni in Skipped.
Full SIZE 306 KB Average (628 ms Average Loading)
Questa è la sezione Skipped unita ai codici Canonical e occorre ricordare che non ha nessuna unione con i Dati Veri del contesto online effettivo,tranne la presenza dei codici Canonical stessi. Nelle selezioni dei contenuti interni ai domini,la presenza dei codici specifici,significa che l'autore conferma da solo l'originalita' dei contenuti (assomiglia al Self Serving Data:) e il contesto è normale,perche' effettivamente lo strumento non conosce la Struttura Data del dominio specifico e quindi,quando esiste la presenza di codici Canonical,le pubblicazioni vengono sistemate direttamente in Skipped e se il codice fosse nella prima pagina di qualsiasi dominio,sara' presente il SITE Skipped e cioe' tutte le pubblicazioni vengono bypassate e lo stesso contesto è valido per i Limit Rate e cioe' se nella prima pagina,sono sistemati gli Status Code 4xx (attualmente il piu' diffuso è lo Status Code 403,almeno nelle selezioni di DEC 2024:) tutte le pubblicazioni vengono sistemate in Skipped,pero' con una differenza importante,rispetto ai codici Canonical,perche' gli Status Code 403,uniti al Limit Rate,esistono realmente:)
Le descrizioni sistemate sono importanti,perche' la prima pubblicazione in Skipped,unita ai codici Canonical è davvero molto curiosa:)
La prima curiosita è questa e occorre ricordare che è sempre nel codice Canonical,pero' sistemato in Skipped e sono le Policies Guidelines del dominio e sono valide per tutti gli spazi di Wikimedia:lo Style Guide sistemato su Wiki (oltre a Wiktionary è presente in tutti gli altri spazi) è "un Inno al Nonsense",perche' Wiki non ha nessuna referenza,rispetto a Dati Veri,ma è esattamente l'Opposto:) Esistono poi le Quotations di Wiktionary e sono le stesse per tutti gli spazi Wiki e anch'essa fa parte "dell'Inno al Nonsense",perche' quasi sempre i Match non iniziano nemmeno,grazie al fatto che non è originale nessun contenuto di Wikimedia e il paradosso è unito al fatto che sono loro stessi a confermarlo,attraverso i numeri degli EDITS:)
Esiste poi il 3° "Inno al Nonsense" consecutivo,grazie alla presenza delle Categorie,in 1 solo dominio e occorre ricordare a Wiktionary che è valido anche per Essa,il "Controllo a Livello di Pagina" e sono coinvolte tutte le enciclopedie e dizionari online e naturalmente anche qualsiasi altro dominio e in 1 spazio puo essere presente 1 sola Categoria e si chiama anche Main Content,ed è valido anche per i dizionari e cioe' dopo aver fatto UNA Definizione,rispetto a qualsiasi termine,non è possibile modificarla e se fosse proprio necessario,aggiungere altre definizioni,è possibile farlo,pero' all'interno di una nuova pubblicazione,ed è sufficente solo sistemare un collegamento con i contenuti precedenti.
Per sistemare un collegamento con i contenuti precedenti,è indispensabile non avere la posizione sopra e anch'essa fa' parte della prima pubblicazione in skipped unita ai codici Canonical e forma "un Super Inno al Nonsense" (nemmeno gli Squallor sono mai arrivati a queste Vette di Puro Nonsense:) ed è la Grande Preoccupazione di Wiki,rispetto alle violazioni del Copyright,sistemate nelle sue Guidelines:) Per Wiki è una Preoccupazione del tutto inutile,perche' è essa stessa ad essere "separata dal copyright effettivo" e solo i Social Media sono stati capaci di fare peggio,utilizzando degli URLs nelle contestazioni per le violazioni dei copyright,Scelti da Loro stessi:)
A queste condizioni è proprio impossibile contestare altri domini,per le violazioni del copyright e ancora meno è possibile descrivere le Quotes,perche' la Partita e cioe' i Match non iniziano proprio e quindi non potra esistere nessun Rating e di conseguenza non possono proprio Esistere le Quotes e ancora meno "le strombazzate classifiche di Wiki" e cioe' il Ranking:) La posizione di Wiki possiede un altra importanza,per prendere per il culo tutti i SEV (sono i Ricercatori per arrivare alle Egregious Violation e cioe' gli operatori alternativi ai Dati Veri:) ed è sistemata nell'evidenza,formata "dagli elementi non performanti" e cioe' "l'amato Loading dei SEV":)
E' facilissimo comprendere il motivo per cui "amano i Loading" i SEV,perche' la posizione sarebbe anche importante,pero rispetto ai Content Effettivi,il Loading non Vale Nulla e per questo motivo "è Amato dai SEV" perche' è la cazzata piu' semplice da poter raccontare "ai loro Utenti":)
L'evidenza di Wiktionary,unita alla sua prima pubblicazione negli skipped dei codici Canonical,rappresenta la migliore evidenza,rispetto alle posizioni descritte,perche' esistono solo 23 elementi statici nella pubblicazione e solo UNO non è performante,ed è possibile,almeno a memoria,dichiarare Record questa posizione,perche' non ricordo nessun report precedente che abbia mai avuto questi dati e sarebbero i migliori da unire "all'amato Loading",pero' contemporaneamente non esistono Content validi,ad iniziare dal fatto che non sono nemmeno Originali:)
Questo è il codice Canonical effettivo della prima pubblicazione degli Skipped e cioe' esiste realmente,ed ha anche i suoi codici e l'unico problema è unito al fatto che Wiktionary lo ha sistemato "Motu Proprio",senza nessuna unione con i Dati Veri:) In teoria sarebbe possibile anche sistemare codici Canonical in proprio,pero' occorre unire una Main Entity,rispetto alla categoria a cui appartengono i contenuti e non è certo quella sistemata da Wiki (Creative Commons:) e poi non significa assolutamente Nulla,rispetto ai Dati Veri,perche' la presenza di codici Canonical,nel contesto online effettivo, rappresenta solo un indicazione e non esiste nessuna garanzia che venga seguita,sopratutto nei domini Wikimedia,perche' prima di avere la Grande Preoccupazione di sistemare codici Canonical,è indispensabile Preoccuparsi che esistano Content Originali,ad iniziare dalla Struttura Data Effettiva e solo dopo,sempre in Teoria,è possibile sistemare i codici Canonical:)
1137024 VOL. DEC 2024 VS 58,752 MB Full Size
Questi sono i dati della selezione e nei Pesi non sono presenti gli Skipped,compresi i codici Canonical appena sistemati.


 Assente DEC 2024
Assente DEC 2024
324870 Keywords Vol. VS 11,648 MB Full Size
Questo era il volume e il peso a NOV 2024 e restano importanti,nonostante l'assenza del dominio a DEC 2024 (è presente uno Status Code 500 è quindi il dominio è tutto in Skipped) perche' tutti i contenuti dello spazio,appartengono ad altri autori,presenti anche in altre migliaia di domini e quindi i dati sopra restano importanti,perche' sono capaci di fornire la migliore evidenza,rispetto agli operatori stessi,perche' esiste la sicurezza che i contenuti non sono stati creati da loro,mentre sono stati gli operatori a scegliere le impostazioni e sono descritte nel Volume e nel SIZE sopra,difficilissimi da rendere compatibili con la LOGICA,ad iniziare dal fatto che i contenuti effettivi appartengono,NOtoriamente,ad altri autori:) L'aspetto divertente è munito al fatto che nel dominio esiste anche la Grande Preoccupazione per la violazione del copyright:)
E' presente in questa posizione e per unire anche la LOGICA,è sufficente sistemare il riferimento piu' importante,ed è gia' descritto nel nome della pubblicazione:
E' la Raccomandazione dell'Holy Grail TFD Google Merchant e l'unica Grande Preoccupazione è quella di avere High Quality Value e la traduzione operativa si chiama Landing Pages e naturalmente non esiste nessuna possibilita' di unirla alla violazione dei copyright,sopratutto quando le posizioni sono anche note (gli operatori dei Poeti Tradotti lo sanno benissimo che i contenuti appartengono ad altri autori:) e naturalmente per avere le Landing Pages,è indispensabile partecipare anche ai Match e per poterlo fare,il primo Step è quello di avere meno Duplicati possibili all'interno di 1 dominio e poi occorre anche vincere i Match globali e solo al termine si ha la Raccomandazione dell'Holy Grail TFD Google Merchant,ed è quella di avere High Quality Content e cioe' le Landing Pages e l'unica sua Guidelines sono i Quality Score e cioe' esclusivamente le Keywords e non possono proprio esistere,se dovesse essere presente la violazione dei copyright,sopratutto quando sono gia' noti gli autori originali:) E' il Caso del dominio dei Poeti Tradotti e nonostante la conoscenza degli autori effettivi,gli operatori dello spazio hanno il volume e il SIZE sistemato sopra (11,6 MB per un volume poco maggiore a 300K termini:) e quindi non si possono proprio lamentare se dovessero arrivare anche le Egregious Violation e per comprenderle,è sufficente l'immagine dell'Holy Grail TFD Google Merchant e cioe' l'unica Raccomandazione (è inserito proprio il termine specifico Raccomandazione nel dominio di Google Merchant:) è quella di avere High Quality Content e cioe' sono le Landing Pages l'unico vero valore e indirettamente è descritto nell'immagine creata per l'Holy Grail TFD Google Merchant:
DON'T DECEIVE Users e sopratutto non esiste nessuna possibilita' di Decidere il Business,ed è facile comprendere la ragione,perche' senza Dati Veri non esisterebbe proprio il colossale Business Online,ed è facile comprendere anche l'opposto,perche' tutte le strategie alternative,rispetto ai Dati Veri,conducono direttamente all'Inflate Data e cioe' al fallimento di tutto il sistema e per questo motivo esiste la Raccomandazione dell'Holy Grail TFD Google Merchant e arriva alle Landing Pages,semplicemente perche' non esiste nessuna strategia alternativa ad esse e cioe' ai Content Effettivi e il dominio dei Poeti Tradotti,rappresenta la sua "migliore evidenza" perche' gli operatori dello spazio "di sicuro non hanno profuso impegno" nella creazione dei contenuti,pero' hanno sistemato lo stesso un volume demenziale di codici,del tutto incompatibili tra di loro,perche' con oltre 11 MB,si avrebbero volumi dei Content molto piu' elevati,ed essendo lo spazio un Full Size (non esistono pesi strutturali da poter unire) per forza di cose sono i codici a prevalere nettamente nei Pesi,ed è molto difficile solo immaginare che le Operazioni Prodotte siano Appropriate,perche' è sufficente solo "un colpo d'occhio" (è il Report at a Glance e cioe' il primo elemento effettivo del Webmaster Topic:) per avere la certezza che nei codici esistono tutte le strategie alternative,rispetto ai Dati Veri e quindi diventa normale anche il nuovo acronimo SEV,perche' ad iniziare dal dominio specifico dei Poeti Tradotti,l'unica Vera Ricerca,è quella di arrivare alle Egregious Violation e gli operatori dello spazio dei Poeti Tradotti,sono in netto vantaggio,rispetto a tutti gli altri Ricercatori per arrivare alle Egregious Violation,perche' è gia nota l'appartenenza dei contenuti e occorre ricordare che la violazione del copyright è essa stessa parte delle Spam Policies e al massimo è possibile avere DUE Violation,naturalmente senza aggiungerne anche altre e per gli operatori del dominio Poeti Tradotti,esistono elevate probabilita' di fare l'enplain rispetto solo alle violazioni dei copyright,perche' non ricordo 1 solo contenuto creato da loro:)
Gli unici elementi felici di avere il contesto appena descritto,sono i Contestatori in generale (sia per i copyright e anche per le Patenti),perche' sarebbero i domini piu' facili da Contestare e la Felicita' degli operatori delle Contestazioni è facile da comprendere,grazie ai costi delle operazioni stesse:)
Posso assicurare che esistono gia' dei dati,ed hanno anche "una stima per difetto" e cioe' è facile avere anche costi piu' elevati,per pagare i Contestatori stessi:)
L'Average "dei poveri utenti" ha una stima di circa 200K dollari,solo per una Contestazione ed è negli EVENTI dell'Holy Grail TFD Google Patent e i dati arrivano dall'associazione degli avvocati che partecipano agli EVENTI stessi e il dato piu' Divertente è l'Applicazione dei Costi e cioe' sono uniti anche alle Contestazioni delle Appliance,rispetto a domini che non hanno nemmeno la Patente Assegnata:)
Questa descrizione dei costi,per le contestazioni riguarda solo "i poveri utenti" e cioe' quelli che al massimo possono spendere 200K dollari e potrebbero essere gli Utenti Felici di Rankmath,perche' è gia' difficile pagare i suoi "miseri Crediti" uniti al Pricing e quindi figurarsi cosa significa sostenere pure i costi delle contestazioni,sopratutto nei confronti di quelli che seguiranno:)
200K Dollari è un valore generale per le Contestazioni e poi a salire esistono altri limiti,da unire ai costi delle Contestazioni e il piu' importante è unito al fatturato delle aziende che richiedono i servizi e il limite è 1 Billion di dollari e tra i maggiori contestatori dell'intero contesto online, esistono tantissime aziende che superano ampliamente il limite e a loro è applicato un costo del servizio di 3 Milion di dollari,per ogni EVENTO e cioe' Contestazione e posso assicurare che esistono gia' i dati e l'aspetto piu' importante,deriva dal fatto che la stima è approssimativa e cioe' puo facilmente lievitare e quindi è facile comprendere quanto siano importanti i Dati Veri,perche' se non esistesse il Page Quality Rating,non esisterebbe nessuna possibilita' di competere,perche' nel contesto online potrebbero esistere solo le aziende che possono permettersi di spendere tanto denaro,solo per fare le Contestazioni:)
Figurarsi,con queste cifre,quanto sarebbero Felici i Contestatori,pagati dalle aziende Enterprise,di trovare nel loro percorso un dominio simile a quello dei Poeti Tradotti,oppure tutti gli spazi uniti ai SEV e cioe' ai Ricercatori delle Grandi Violazioni,ad iniziare dall'imperatrice del Falso e cioe' Wikimedia:)
Per i Contestatori sarebbe UNA FESTA,perche' è il modo piu' facile per vincere i Match "e incassare il bottino" (togliere denaro ai SEV e ai poveri utenti,è equivalente a una rapina e quindi è pertinente il termine BOTTINO da unire ai pagamenti per i servizi dei contestatori:) e questa posizione è importante da ricordare per una semplice ragione,ed è unita al Valore dei Dati Veri e dei Legittimi Publishers,perche' senza di LORO,anche le grandi aziende possono spendere tutto il denaro che vogliono e che possiedono, pero' senza i Legittimi Publishers,il contesto online non esisterebbe proprio,ad iniziare dal fatto che gli alternativi ai Dati Veri,effettuano delle operazioni talmente Idiote,da eliminarsi a vicenda,grazie all'Idiozia stessa (le denominazioni alternative ai Dati Veri ne sono tantissime,pero' la base effettiva è solo Schemes:) perche' è capace di arrivare solo all'Inflate Data e quindi per i Contestori non esisterebbe piu' NULLA da Contestare e non avrebbero piu' i "loro lauti compensi" e quindi,l'unica cosa sensata da fare per i simpatici contestatori è quella di Ringraziare l'elemento piu' Potente dell'Intero Contesto Online e NON sono gli Engines,ma i Legittimi Publishers,perche' senza di essi,non esisterebbe proprio NULLA da Ricercare:) Non potrebbero esistere nemmeno le Egregious Violation dei SEV e cioe' di coloro che pensano di vincere la Partita,senza nemmeno Disputarla:) Assomigliano molto alla fantastica nazionale di calcio italiana,eliminata 2 volte consecutive dalla Disputa dei Match,senza aver disputato nessuna partita nella fase finale dei mondiali di calcio,semplicemente perche' sono stati eliminati prima e cioe' non si sono qualificati proprio per Disputare i Match e cioe' non sono stati Eliggibili:)


 226 PUB 89% UN 553 AV 39 ILA FULL SIZE 14 KB AV (173 ms AV Loading)124978 VOL DEC 2024 (226548 Vol. NOV 2024) VS 3,164 MB (4,557 MB NOV 2024) Full SIZEPer ZENO .ORG,esistono dati diversi rispetto al dominio dei Poeti Tradotti,pero' è presente lo stesso metodo,nella creazione dei contenuti e cioe' appartengono del tutto ad "altri autori",rispetto agli operatori del dominio stesso e un esempio,rispetto ai veri autori presenti su ZENO.ORG è sistemato sopra:)Nei dati appena inseriti è presente anche un evidenza fantastica,rispetto a 2 sole selezioni,ed è formata dalla differenza dei volumi,anche rispetto ad Average molto scarsi e per DEC 2024,esistono oltre 100K termini in differenza e l'Average di NOV 2024 non era molto elevato lo stesso,perche' ha raggiunto un dato poco maggiore a 1000 termini,mentre l'attuale è formato da 553 termini e ha prodotto la differenza citata sopra.
226 PUB 89% UN 553 AV 39 ILA FULL SIZE 14 KB AV (173 ms AV Loading)124978 VOL DEC 2024 (226548 Vol. NOV 2024) VS 3,164 MB (4,557 MB NOV 2024) Full SIZEPer ZENO .ORG,esistono dati diversi rispetto al dominio dei Poeti Tradotti,pero' è presente lo stesso metodo,nella creazione dei contenuti e cioe' appartengono del tutto ad "altri autori",rispetto agli operatori del dominio stesso e un esempio,rispetto ai veri autori presenti su ZENO.ORG è sistemato sopra:)Nei dati appena inseriti è presente anche un evidenza fantastica,rispetto a 2 sole selezioni,ed è formata dalla differenza dei volumi,anche rispetto ad Average molto scarsi e per DEC 2024,esistono oltre 100K termini in differenza e l'Average di NOV 2024 non era molto elevato lo stesso,perche' ha raggiunto un dato poco maggiore a 1000 termini,mentre l'attuale è formato da 553 termini e ha prodotto la differenza citata sopra.

 Verne 250 PUB 85% UN 695 AV 23 ILA Full Size 8 KB AV (88 ms AV Loading)
Verne 250 PUB 85% UN 695 AV 23 ILA Full Size 8 KB AV (88 ms AV Loading)
173750 Keywords Vol. VS 2 MB Full SIZE
 DEC 2024 141 PUB 87% UN 2120 AV 108 Internal Links Average (ILA) 36 KB Full Size in Average (637 ms AV Loading)
DEC 2024 141 PUB 87% UN 2120 AV 108 Internal Links Average (ILA) 36 KB Full Size in Average (637 ms AV Loading)
298920 VOL. DEC 2024 (108993 Vol. NOV 2024) VS 5,076 MB (3,102 MB è stato il peso a NOV 2024) tutti in Full SIZE.
Il dominio Gutenberg rappresenta un altro ottimo esempio,rispetto ai dati appena sistemati e quelli generali,grazie "alla provenienza dei contenuti stessi" e un esempio è sistemato sopra e cioe' appartengono ad altri autori,rispetto ai gestori dello spazio e nella posizione sono sistemati anche tanti Detect Language,presenti in 1 solo dominio:)
Nonostante il numero di pubblicazioni non sia elevato,è presente lo stesso una notevole differenza tra 2 sole selezioni (DEC 2024 ha avuto quasi 200K termini in piu' rispetto a NOV 2024) e per il dominio specifico,esistono condizioni equivalenti a quelle descritte per lo spazio dei Poeti Tradotti,grazie alla Grande Preoccupazione per la violazione del copyright,descritta in un dominio,completamente occupato da contenuti creati da altri autori e a loro volta presenti in altre migliaia di spazi.
La posizione dell'immagine di Gutenberg è solo un esempio e occorre ricordare il contesto,perche' è molto difficile trovare un altro dominio con dimensioni maggiori a Gutenberg e tutti i contenuti sono realizzati "con lo stesso metodo" e cioe' attraverso i contenuti "di altri autori",rispetto a quelli che gestiscono il dominio:)
Quindi anche se è presente una differenza da 200K termini rispetto a 2 sole selezioni,rispetto al dominio effettivo,il dato è quasi irrisorio,perche' i volumi effettivi del dominio sono assai maggiori e il motivo per cui non sono presenti nelle selezioni,deriva dai File stessi utilizzati nello spazio e prevalentemente sono in PDF e non vengono selezionati e la stessa cosa potrebbe accadere se fossero presenti file XML,perche' nelle selezioni sono presenti solo File HTML.
Sempre nel dominio Gutemberg sono presenti anche il maggior numero di pubblicazioni superiori a 100K termini in 1 sola posizione e anch'essi non possono essere presenti nelle selezioni,insieme ai Size maggiori a 2 MB.
Sono tutte posizioni che il dominio Gutemberg possiede largamente e questo è il motivo per cui i suoi reports sembrano provenire "da un piccolo spazio",mentre le sue dimensioni reali sono molto piu' elevate e probabilmente,togliendo i domini Wikimedia,oppure Archive,non esiste nessun altro spazio ad avere le dimensioni di Gutemberg,ed è questa posizione ad avere la Grande Preoccupazione per la violazione dei copyright:)
Se il dominio Gutemberg possedesse qualche Dato Vero,di sicuro i piu' Felici non sono i suoi gestori,ma gli operatori delle Contestazioni,perche' potrebbero incassare il denaro per i loro servizi,prima dell'inizio dei Match,perche' la Partita è gia Vinta in Partenza,grazie "ai fantastici autogoal" degli operatori di Gutemberg:)
 250 PUB 18% UN 1818 AV 302 ILA Full Size 69 KB Average (925 ms AV Loading)
250 PUB 18% UN 1818 AV 302 ILA Full Size 69 KB Average (925 ms AV Loading)
454500 Keywords VOL. VS 17,250 MB Full SIZE Letteratura Classica 250 PUB 88% UN 4414 AV 37 ILA Full Size 94 KB AV (532 ms AV Loading)1103500 VOL DEC 2024 (900604 VOL. NOV 2024) VS 23,500 MB (19,302 MB è stato il peso a NOV 2024) Full Sizehttps://dinpoststory.blogspot.com/2024/04/size-comprehensive-trust-content-code.html
Letteratura Classica 250 PUB 88% UN 4414 AV 37 ILA Full Size 94 KB AV (532 ms AV Loading)1103500 VOL DEC 2024 (900604 VOL. NOV 2024) VS 23,500 MB (19,302 MB è stato il peso a NOV 2024) Full Sizehttps://dinpoststory.blogspot.com/2024/04/size-comprehensive-trust-content-code.html
Questo è un altro dominio interessante per comprendere i reports,perche' anche i suoi contenuti appartengono ad altri autori e nella pubblicazione collegata sopra,esiste un altra Fantastica Preoccupazione,ed è la Privacy degli Utenti di Letteratura Classica,unita alle Ads:)Questa è l'unica posizione da ricordare ,per uscire dalla demenza operativa dei SEV (il dominio di Letteratura Classica è gestito da un SEO e quindi figurarsi quanto puo essere affidabile la gestione:) ,perche' l'unica raccomandazione è quella di avere High Quality Content e per essere in questo contesto,è indispensabile che i contenuti non appartengano ad altri autori e nel dominio di Letteratura Classica è esattamente l'opposto:)
 132 PUB 68% UN 867 AV 18 ILA Full SIZE 22 KB (64 ms AV Loading)
132 PUB 68% UN 867 AV 18 ILA Full SIZE 22 KB (64 ms AV Loading)
114444 VOL. DEC 2024 (196467 VOL. NOV 2024) VS 2,904 MB (4,386 MB è stato il peso a NOV 2024) Full SIZE DEC 2024 164 PUB 93% UN 5239 AV 48 Internal Link Average (ILA) Full SIZE 109 KB AV (349 ms AV Loading)
DEC 2024 164 PUB 93% UN 5239 AV 48 Internal Link Average (ILA) Full SIZE 109 KB AV (349 ms AV Loading)
859196 VOL. DEC 2024 VS 17,876 MB Full SIZEIl dominio Pasomv è arrivato grazie alla presenza nei suoi contenuti della "vice autrice" del Contest Level Absolute (è Santa Veronica Giuliani dottore della Chiesa) e l'unico problema è unito al fatto che sono relativamente poche le presenze del Contest Level Absolute. Ne esistono solo 2 e una sola è una vera pubblicazione ed è formata da oltre 12K termini e sarebbe un Post colossale in qualsiasi dominio,pero' rispetto al Contest Level Absolute,le dimensioni citate sono equivalenti a un inezia:)In compenso esistono tantissime altre pubblicazioni nel dominio,tutte unite a dottori della Chiesa e sono sistemati in 1 solo spazio,con lo stesso metodo di altri domini presenti in questa DEC 2024 e cioe' utilizzando "i contenuti di altri autori" e tra un po' ci sara' un esempio diretto attraverso l'Enciclopedia cattolica,perche' esistono tante posizioni,assolutamente uguali al dominio Pasmov:)



Enciclopedia Cattolica 243 PUB 97% UN 6727 AV 176 ILA Full SIZE 64 KB AV (818 ms AV Loading)
1634661 VOL. DEC 2024 VS 15,552 MB Full SIZE Questa è l'enciclopedia cattolica e in tante posizioni è speculare al dominio Pasmov sistemato sopra,ad iniziare da tantissimi contenuti comuni e lo sono proprio al 100%,perche entrambe le posizioni utilizzano contenuti di altri autori:)Nel dominio Pasmov esiste una grande differenza,perche' almeno utilizza 1 solo Detect language,mentre New Advent e cioe' l'Enciclopedia Cattolica è esattamente il contrario:)E' arrivata proprio per questo motivo nelle selezioni delle verifiche,perche' di sicuro non esiste nessun altro spazio ad avere le stesse caratteristiche e cioe' dimensioni elevate,grazie a tantissimi autori extra al dominio e poi è presente l'unione di tanti Detect Language,pero' con una caratteristica diversa a tanti domini simili,perche' sono sistemati direttamente in 1 pagina,attraverso 3 colonne con altrettanti Detect language e il metodo utilizzato non riguarda pochi periodi,ma l'intera Bibbia,Vecchio e Nuovo Testamento insieme:)Questo metodo è direttamente nel report sistemato sopra e possono variare le selezioni,pero' il contesto esiste,ed è direttamente inserito nei dati del dominio:)New Advent,oltre alla Preoccupazione del Copyright (tra l'altro è inutile perche' i contenuti effettivi non sono suoi e nemmeno di Pasmov:) ,possiede anche la Preoccupazione delle Ads,come se i contenuti fossero davvero suoi e la posizione è ad Alto Divertimento Aggiunto,perche' esistono anche le unioni specifiche,unite ai costi delle Ads e sono quelle sotto:)

Insieme ai costi esiste questa posizione,ed ha il 99,9% di Organic Traffic e occorre ricordare che il riferimento è la Natural Search e per essere vero è indispensabile avere i Content Originali,altrimenti è Tutto Invalid Traffic e le posizioni sopra appartengono solo a un intepretazione del Self Serving Data:)E' oggettivamente molto difficile arrivare ai Dati Veri,ed è possibile provarci,pero' occorre farlo attraverso propri contenuti e che abbiano anche una Struttura Data Valida e non esiste proprio NULLA che sia capace di "avere un percorso alternativo",ad iniziare dalla Logica stessa,perche' se i SEV (sono i Ricercatori delle Egregious Violation) avessero Vere Capcita',è sicuro che non venderebbero il servizio :)  IONOS DEC 2024 235 PUB 49% UN 1752 AV 110 ILA 289 KB Full SIZE Loading AV 1359 ms411720 VOL. DEC 2024 VS 67,915 MB Full SIZEhttps://dinpoststory.blogspot.com/2024/02/general-joy-experience-data-value-9-rf.html
IONOS DEC 2024 235 PUB 49% UN 1752 AV 110 ILA 289 KB Full SIZE Loading AV 1359 ms411720 VOL. DEC 2024 VS 67,915 MB Full SIZEhttps://dinpoststory.blogspot.com/2024/02/general-joy-experience-data-value-9-rf.html
Per IONOS esiste questa posizione,ed è la General Joy Experience Data Value e da sola è capace di "rendere ragionevole il motivo" per cui esistono Size cosi elevati (oltre 67 MB:) per una dimensione del volume poco maggiore a 400K termini effettivi e una ragione è gia' inserita nell'immagine sopra,perche' è assolutamente reale e cioe' il dominio è realizzato proprio nel modo indicato dall'immagine e per paradosso è anche moderata,perche' i collegamenti interni sono anche maggiori e per funzionare hanno bisogno di codici e se un autore compie queste operazioni,è sicuro che nel dominio saranno presenti anche le altre strategie alternative e non esiste dubbio che sia Vero,perche' esistono i Pesi a confermarlo e di sicuro non sono occupati dai Content Effettivi:)Esiste poi una posizione speciale di Ionos stessa,perche' è l'unico vero competitor di Godaddy nei Servers e da questo contesto contesto è nata la General Joy Experience Value,perche' è possibile avere qualsiasi potenza economica,pero' se i Dati Non sono Veri,non esiste Nulla che possa sostituirli,ed è valido anche per Ionos:) Sono i Legittimi Publishers a creare il vero business online e quasi sempre non è unito al potere economico,altrimenti esisterebbero solo i domini delle aziende Enteprise e non avrebbero nessun valore,perche' le strategie alternative ai Dati Veri,hanno una sola possibilita operativa,ed è quella di generare Inflate Data:)
Litigation Network 150 PUB 59% UN 900 AV 36 ILA Full SIZE 77 KB 838 ms AV Loading
135000 VOL. DEC 2024 VS 11,550 MB Full SIZE
Questo è il Litigation Network e lo è nel Vero senso delle parole,perche' è la Base Legale delle contestazioni e da loro sono arrivati anche i costi delle Litigation,unite al Copyright e poi anche alle Patenti,perche' se non esistesse il primo (assenza di violazione di copyright) diventa impossibile che esista il secondo (Patent) e solo i costi delle Contestazioni aiutano tantissimo a comprendere il valore dei Dati Veri,perche' sono gli unici elementi a rendere Immuni gli Autori,sopratutto nei confronti dei termini a maggior rilevanza e i contestatori sono pagati proprio per trovarli:) Naturalmente non sempre è possibile,perche' nelle ricerche dei contestatori esistono anche i Duplicati,pero' l'Immunita degli Autori,è possibile vederla anche fisicamente,perche' nella Stragrande Maggioranza dei casi è all'interno delle percentuali delle No Action Taken e di sicuro le posizioni piu' rilevanti sono al suo interno e i contestatori,nonostante la potenza economica che hanno,grazie sopratutto alle aziende che pagano i servizi,Non possono arrivarci,perche' la potenza dei Dati Veri è nettamente superiore:) Senza i Legittimi Publishers e cioe' i detentori dei Dati Veri ,non potrebbero esistere nemmeno i contestatori,semplicemente perche' sarebbe il contesto online a non esistere proprio e il successivo dominio,fornisce la certificazione completa:) (è Progress ed è il CMS della Philip Morris e cioe' l'Enteprise piu' addeestrata a tutte le contestazioni :)
DEC 2024 202 PUB 44% UN 1200 AV Multi Detect Language 89 Internal Links Average 545 ms (millesimi di secondo) Average Loading 110 KB AV Full Size.
242400 VOL DEC 2024 (268380 VOL. NOV 2024) VS 22,220 MB (24,773 MB peso a NOV 2024) Full SIZE.
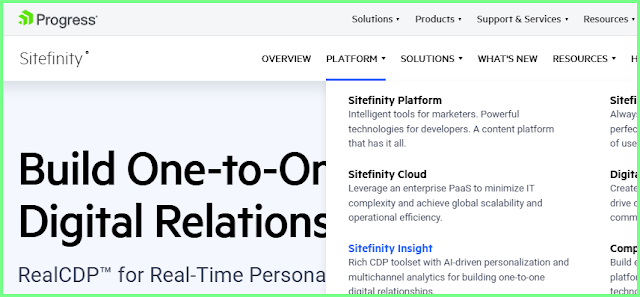
Questo è il dominio Progress,ed ha una struttura un po' complessa,perche' al suo interno sono sistemati dei Subdomain e uno di essi (Sitefinity) è il Custom CMS (sono le piattaforme a pagamento e tra i suoi utenti esiste anche la Philip Morris )
Questa è la posizione del Custom CMS all'interno del dominio Progress,ed è Divertente anche la sua Homepage attuale e posso assicurare di non averlo fatto di proposito,perche' l'ho vista solo al momento di prelevare l'immagine:)
Il contesto è Progress e a scalare esiste Sitefinity e attraverso i suoi dati formati da un SIZE da 22,220 MB per 242K termini effettivi (al suo interno sono presenti i contenuti di Progress;Sitefinity e tutte le altre posizioni sistemate sopra) è presente l'Homepage sistemata sopra e occorre ricordare che non è uno Scherzo,ma è Reale:)
Esiste il Building anche della Relationship (One To One:) e con i dati che possiede il dominio,l'unica cosa sensata che viene da pensare,è unita al fatto che il dominio specifico ha una "lunghissima esperienza in Relationship" e visti i suoi Pesi,è facile ipotizzare che esista anche una lunghissima esperienza,rispetto a qualsiasi altra operazione alternativa e solo con questi elementi,è possibile arrivare al SIZE sopra,unito a un volume dei contenuti ridicolo, rispetto al Peso dei codici:)
Queste sono le posizioni operative unite alle varie industrie e tra le evidenze sistemate,la piu' curiosa è quella della Sanita,unita al servizio di Progress e del suo Custom CMS Sitefinity e naturalmente il motivo è unito alla presenza di Philip Morris,tra gli utenti di Progress,molto difficile da rendere compatibile con "l'Industria della Sanita",sopratutto perche il riferimento principale degli "Utenti Sanitari" di Progress non è affatto generico,ma è quello sotto:)
Decisamente l'utente di Progress e del suo Custom CMS,non è affatto generico,perche' è proprio il World Health Organization ,ad utilizzare i suoi servizi,insieme a quelli forniti alla Philip Morris,decisamente poco compatibile con la Sanita:)
Indirettamente questa è una certificazione delle unioni bizzarre generali di Progress e da sola è capace di giustificare tutti i contesti del dominio specifico,perche' è presente anche il "Magic Quadrant" di Gartner Inc e cioe' il NULLA Assoluto,mentre per Progress è un vanto unito al DXP e cioe"l'Esperienza Digitale della Piattaforma":)
L'unica Esperienza effettiva è unita ai Content e quelli di Progress sono decisamente scarsi,unendo anche Size dei codici molto elevati,in un dominio tutto in Full SIZE :)
Attraverso il contesto descritto,diventa per paradosso normale,anche l'attuale Homepage,rispetto alla data di questa pubblicazione,dedicata "al Building della Relationship" e i contenuti di Progress sono "proprio l'ideale per le operazioni alternative",perche' è difficile anche immaginare che siano capaci di arrivare al Discover e cioe' solo l'inizio del percorso per i valori all'interno di 1 dominio e poi esistono anche i Match globali e solo al termine si hanno i Dati Veri e se dovessero esistere,in Teoria è possibile utilizzare anche le operazioni alternative,Relationship compresa,pero' il contesto non ha assolutamente nessuna Credibility,tranne quella dell'Idiozia degli operatori stessi,utilizzando solo la Logica:)
237 PUB 66% UN 1878 AV 50 ILA 393 KB AV Size 195 ms AV Loading
445086 VOL. DEC 2024 (350896 Vol. NOV 2024) VS 93,141 MB (78,325 MB è il Peso a NOV 2024) Full SIZE
Questa è la Verita dei Dati e anche sistemando il Vasto Ignore e cioe' senza conoscere nessun elemento operativo,ad iniziare dall'originalita effettiva dei contenuti,è presente sempre il miglior alleato e sono le Irrelevant Keywords e il report sistemato è il piu' Ottimista che potesse arrivare,perche' non è presente nessun Match precedente e quindi i dati effettivi del contesto online possono essere solo peggiori e visti i dati dei SIZE e il volume dei contenuti effettivi,potranno esistere anche delle "combinazioni migliori",rispetto alle pubblicazioni selezionate,pero' non potranno mai piu' recuperare le impostazioni scelte dal dominio e visti i Pesi sistemati,non esiste dubbio che a formare i Size sino tutte le strategie alternative,altrimenti con il peso dei contenuti,è proprio impossibile arrivare a 93 MB in 1 sola selezione:)
178 PUB 39% UN 1566 AV 74 ILA 170 KB AV Size 563 ms AV Loading.
278748 VOL. DEC 2024 VS 30,260 MB FULL SIZE
 210 PUB 72% UN 2721 AV 94 Internal Link Average (ILA) FULL SIZE 125 KB AV (458 ms AV Loading)571410 VOL DEC 2024 (486219 VOL. NOV 2024) VS 26,250 MB (22,519 MB NOV 2024) Full SIZE
210 PUB 72% UN 2721 AV 94 Internal Link Average (ILA) FULL SIZE 125 KB AV (458 ms AV Loading)571410 VOL DEC 2024 (486219 VOL. NOV 2024) VS 26,250 MB (22,519 MB NOV 2024) Full SIZE
DEC 2024 228 PUB 60% UN 1458 AV 155 Internal Links Average (ILA) Full SIZE 340 KB in Average (541 ms AV Loading)
3012 Skipped e 2991 sono i suoi Disallow
338589 VOL. DEC 2024 (325134 VOl. NOV 2024) VS 77,520 MB (70,468 MB è stato il peso completo a NOV 2024) Full SIZE
 Advance Web Ranking 250 PUB 74% UN 1908 AV 35 ILA FULL SIZE 697 KB AV (444 ms AV Loading)477000 VOL DEC 2024 (441975 Keywords VOL. NOV 2024) VS 174,250 MB SIZE DEC 2024 (167,826 MB Peso completo a NOV 2024) Full SIZESono dati incredibili,pero sono assolutamente veri e non occorre fare nessuna ricerca,perche' con 174 MB per un volume da 477K termini,non esiste proprio nessuna compatibilita' con qualsiasi contesto,ad iniziare da quello della LOGICA:)L'Average dei SIZE deriva da queste posizioni e sono i Pesi a scalare della selezione di DEC 2024 per Advanced Ranking e non esiste dubbio che nelle posizioni dei Ricercatori delle Gravi Violazioni (in arte SEV:) il dominio specifico occupi anche "una posizione rilevante" e la stessa cosa è unita a tutti gli altri spazi presenti a DEC 2024 e naturalmente nonostante le tante presenze,rispetto al numero dei domini di tutto il Web,sono sistemati,relativamente, pochi domini,pero' è molto difficile avere "il livello delle presenze" di DEC 2024 e da sole sono capaci di determinare il livello dei valori rispetto a qualsiasi altro dominio,compreso il livello dell'Idiozia:)E' facile comprenderlo,ed è sufficente iniziare dai SIZE,perche' non esiste nessuna possibilita' d'errore,rispetto ai Valori stessi,a prescindere dall'indirizzo che hanno e cioe' è possibile determinare il Valore dei Dati Veri,insieme al loro opposto e cioe' il livello dell'Idiozia:)https://www.advancedwebranking.com/rank-tracker
Advance Web Ranking 250 PUB 74% UN 1908 AV 35 ILA FULL SIZE 697 KB AV (444 ms AV Loading)477000 VOL DEC 2024 (441975 Keywords VOL. NOV 2024) VS 174,250 MB SIZE DEC 2024 (167,826 MB Peso completo a NOV 2024) Full SIZESono dati incredibili,pero sono assolutamente veri e non occorre fare nessuna ricerca,perche' con 174 MB per un volume da 477K termini,non esiste proprio nessuna compatibilita' con qualsiasi contesto,ad iniziare da quello della LOGICA:)L'Average dei SIZE deriva da queste posizioni e sono i Pesi a scalare della selezione di DEC 2024 per Advanced Ranking e non esiste dubbio che nelle posizioni dei Ricercatori delle Gravi Violazioni (in arte SEV:) il dominio specifico occupi anche "una posizione rilevante" e la stessa cosa è unita a tutti gli altri spazi presenti a DEC 2024 e naturalmente nonostante le tante presenze,rispetto al numero dei domini di tutto il Web,sono sistemati,relativamente, pochi domini,pero' è molto difficile avere "il livello delle presenze" di DEC 2024 e da sole sono capaci di determinare il livello dei valori rispetto a qualsiasi altro dominio,compreso il livello dell'Idiozia:)E' facile comprenderlo,ed è sufficente iniziare dai SIZE,perche' non esiste nessuna possibilita' d'errore,rispetto ai Valori stessi,a prescindere dall'indirizzo che hanno e cioe' è possibile determinare il Valore dei Dati Veri,insieme al loro opposto e cioe' il livello dell'Idiozia:)https://www.advancedwebranking.com/rank-tracker
Questo è un esempio e deriva dall'evidenza sistemata sopra,ed è sufficente prelevare la pagina completa in file HTML e si verifica subito il peso e posso anticipare che quello sistemato nei SIZE a scalare è Ottimista,perche' il peso reale è anche maggiore:)Si possono scegliere anche altre pubblicazioni e si comprende subito il motivo per cui esiste l'Average dei Size formato da 697 KB e con questi numeri non è possibile nessun errore,nella distinzione dei Livelli a cui sono applicati,perche' sono completamente incompatibili con i Dati Veri e quindi è possibile che esista solo l'opposto e il fantastico dominio di Advanced Ranking,fornisce la prova migliore,ed è quella sistemata sopra:)La pubblicazione è attuale e nel "Rank Tracker" è presente la Grande Preoccupazione "della visibility delle Landing Pages",dimenticando l'aspetto fondamentale e cioe' le Landing Pages occorre prima Possederle e l'operazione è Difficilissima e parlare della Visibility,sopratutto nel dominio specifico,non è sufficente solo avere autori con Spam al Top nel proprio Brain,ma debbono anche oggettivamente "Fuori di Testa",solo per descrivere "La Grande Preoccupazione" della Visibility delle Landing Pages:)La posizione è sistemata in Improve your Ranking e il riferimento sono proprio le Landing Pages e quindi "il Fuori di Testa" è oggettivo,perche' non esiste proprio nessuna unione tra gli elementi,perche' le Landing Pages nascono esclusivamente dal Rating e solo questa posizione puo migliorare eventualmente la classifica (è l'Improve Ranking sistemato sopra),pero' esiste un Grande Problema,perche' nessuna pubblicazione è capace da sola di essere una Landing Pages e naturalmente non sono gli Autori a DECIDERE quale possa essere (diventerebbe il contesto del Self Serving Data:) ma sono le altre pubblicazioni presenti nel dominio a determinare le Landing Pages stesse e a permetterlo è esclusivamente il Quality Score e cioe' le Keywords e nient'altro:)
Semplicemente occorre possedere il DEMONSTRATE JUICE DATA ARCHIVE,ed è sufficente unire solo la LOGICA per avere i livelli dei valori e il simpatico dominio delle "Classifiche Avanzate" fornisce un ottima evidenza,attraverso la pubblicazione specifica,perche' possiede solo 1400 termini e il suo SIZE effettivo e cioe' la pagina completa in HTML è formata da 1,4 MB (nel report sopra esiste invece un dato Ottimista formato da 840 KB:) e con questi dati è proprio impossibile arrivare al DEMONSTRATE JUICE DATA ARCHIVE e cioe' alle Proposte Complessive e sono esclusivamente Loro a determinare le Landing Pages (è il Rating:)
 Web FX 245 PUB 67% UN 4046 AV 172 ILA Full SIZE 1059 KB AV (183 ms AV Loading)991270 VOL. DEC 2024 (1004910 VOL. NOV 2024) VS 259,455 MB (259,776 MB è stato il peso completo a NOV 2024) Full SIZEAttraverso un peso da 259,455 MB,per un dominio in Full SIZE,è indispensabile sistemare "alcuni dettagli",perche' il volume dei contenuti effettivi,anche se è molto elevato,pero' non è assolutamente sufficente per giustificare il Peso completo della selezione:)Il primo Dettaglio è quello sopra,ed è il percorso che occorre fare,per arrivare il piu' vicino possibile all'Average dei SIZE e il riferimento è 1 sola selezione:)Sistemando i SIZE a scalare,occorre quasi arrivare alla 120° posizione,per trovare una pubblicazione vicina al Size dell'Average e naturalmente ho scelto la piu' curiosa,ed è la classifica dei SEO e per comprendere il contesto,tramite l'immagine sopra,è presente nella 120° posizione esatta,rispetto ai SIZE a scalare per il DEC 2024 di WEB FX,è presente addirittura il Learn del Link Building:)Qui è sistemata la pagina completa dei Size a scalare e iniziano dalla 91° e arrivano alla 120° posizione
Web FX 245 PUB 67% UN 4046 AV 172 ILA Full SIZE 1059 KB AV (183 ms AV Loading)991270 VOL. DEC 2024 (1004910 VOL. NOV 2024) VS 259,455 MB (259,776 MB è stato il peso completo a NOV 2024) Full SIZEAttraverso un peso da 259,455 MB,per un dominio in Full SIZE,è indispensabile sistemare "alcuni dettagli",perche' il volume dei contenuti effettivi,anche se è molto elevato,pero' non è assolutamente sufficente per giustificare il Peso completo della selezione:)Il primo Dettaglio è quello sopra,ed è il percorso che occorre fare,per arrivare il piu' vicino possibile all'Average dei SIZE e il riferimento è 1 sola selezione:)Sistemando i SIZE a scalare,occorre quasi arrivare alla 120° posizione,per trovare una pubblicazione vicina al Size dell'Average e naturalmente ho scelto la piu' curiosa,ed è la classifica dei SEO e per comprendere il contesto,tramite l'immagine sopra,è presente nella 120° posizione esatta,rispetto ai SIZE a scalare per il DEC 2024 di WEB FX,è presente addirittura il Learn del Link Building:)Qui è sistemata la pagina completa dei Size a scalare e iniziano dalla 91° e arrivano alla 120° posizione
https://www.webfx.com/seo/learn/best-seo-companies/
Questi sono i Learn per i Best SEO e il primo dominio è proprio Web FX,ed ha i dati sistemati sopra:)La posizione sara' presente anche in future pubblicazioni,perche' è molto Divertente e in questo contesto è sufficente ricordare che lo spazio è un Full Size e per sistemare i Best SEO,esiste un peso maggiore a 1 MB per una sola pubblicazione formata da 4974 termini effettivi e la posizione rende molto pertinente il nuovo acronimo SEV e spero che l'Holy Grail TFD Google inserisca nelle Gravi Violazioni ,anche l'utilizzo del termine ENGINE,perche' effettivamente il suo utilizzo negli ottimizzatori,è una Forma d'Inganno,perche' non esiste nessuna unione nemmeno con la Logica e ancora meno con i Dati Veri,uniti agli Engine altrettanto Veri:)Questo è il Peso della pubblicazione in Full Size e quindi i dati sono esatti e sono applicati a 1 pubblicazione poco maggiore a 4K termini e quindi l'unico acronimo effettivo è SEV,perche' con questi dati,l'unica ricerca reale è quella delle Gravi Violazioni e non è affatto semplice arrivarci,perche' è indispensabile prima avere Content Validi e poi è possibile arrivare alle violazioni e visto il Brain effettivo degli operatori,è la prima opzione ad avere le maggiori probabilita di successo e cioe' sono eliminati prima i Content:) Gli scritti sono gia scarsi rispetto al peso dei codici in cui sono sistemati e l'unico Fact Check Vero è la presenza di cazzate sesquipedali:) I SEO sono compatibili solo con il contesto tradizionale dei contenuti (cioe' dovrebbe essere presente solo l'IGNORE per permettere alle cazzate che scrivono di essere funzionanti:) e un ottimo esempio è quello sotto:)https://www.webfx.com/seo/learn/best-link-building-companies/
Questo è l'esempio della compatibilita dei SEO,solo con i contenuti tradizionali,grazie all'unico elemento capace di far funzionare il Brain dei SEO,ed è l'IGNORE ASSOLUTO:) (naturalmente l'IGNORE è esteso anche agli utenti dei SEO e cioe' è indispensabile che esistano degli individui disposti a pagare questi servizi:)Hanno sistemato il Best Link Building,ed è la 120° pubblicazione esatta,sistemando lo Score a scalare dei Pesi e la posizione ,per paradosso è rilevante,perche' in qualsiasi altro dominio,lo score della 120° posizione,avrebbe Size molto ridotti,mentre per il dominio specifico i pesi sono quelli sotto:)Questa è la 120° posizione,rispetto allo score dei SIZE (è sistemata anche nella sezione sopra e naturalmente è presente anche nella pagina completa) e solo l'Average da 1059 KB,puo permettere di avere alla 120° posizione,un peso da 1,030 MB per 3539 termini:)Con questi dati,descrivono il Link Building e cioe' il "Top degli Unnatural Links" e ancora piu' demente è il metodo della selezione,ed è indicato dall'evidenza della precedente immagine,unita alle "Star del Rating" e cioe' la "presunta classifica del Link Building" deriva dalla posizione sotto:)https://www.webfx.com/seo/learn/best-seo-companies/
Questa è la certificazione che il termine ENGINE,di sicuro arrivera' anch'esso alle Gravi Violazioni,perche' solo la presenza negli acronimi dei presunti ottimizzatori è un Evidente Abuso:)Per fare la classifica degli operatori Link Building e cioe' una Frode (a nessun autore che possedesse Content Validi,viene in mente di fare Link Building:) hanno utilizzato le Revisioni e cioe' il NULLA,in senso oggettivo,perche' la pratica delle Revisioni ha una Credibility sotto lo 0%,grazie al fatto che qualsiasi revisione deve possedere un collegamento con i contenuti del revisore e debbono essere pertinenti e validi insieme,rispetto al dominio a cui si fornisce il vantaggio,altrimenti si ha solo Self Serving Data:) In questo contesto esiste la certezza del Self Serving Data,perche' esistono tutte posizioni incompatibili tra di loro:Link Building;Revisioni e i dati e sopratutto i Size del dominio che dovrebbe ricevere il vantaggio e cioe' WEB FX:) (servirebbe un Multiplo Miracolo,solo per la compatibilita' degli elementi citati:)
Questo è il Peso su Disco della 120° pubblicazione a scalare nei SIZE,ed è proprio quella del Link Building (il collegamento è sistemato sopra) e i dati sono esatti:)
 213 PUB 78% UN 1345 AV 26 ILA FULL SIZE 491 KB AV (469 ms AV Loading)286485 VOL.DEC 2024 (268272 VOL. NOV 2024) VS 104,583 MB (99,567 MB è stato il peso completo a NOV 2024) Full SIZEAnche questa posizione richiede maggiori dettagli,per giustificare il Peso incredibile formato da oltre 104 MB per "soli 286K termini effettivi" e il maggiore dettaglio è quello sopra e occorre solo citare dove è sistemata la posizione:)
213 PUB 78% UN 1345 AV 26 ILA FULL SIZE 491 KB AV (469 ms AV Loading)286485 VOL.DEC 2024 (268272 VOL. NOV 2024) VS 104,583 MB (99,567 MB è stato il peso completo a NOV 2024) Full SIZEAnche questa posizione richiede maggiori dettagli,per giustificare il Peso incredibile formato da oltre 104 MB per "soli 286K termini effettivi" e il maggiore dettaglio è quello sopra e occorre solo citare dove è sistemata la posizione:)
Il dettaglio della posizione dei SIZE è qui
La pagina è completa e per trovare il Peso piu' vicino all'Average di Forbes per il suo DEC 2024,occorre arrivare alla pagina con l'inizio della 151° posizione a scalare dei SIZE e poi dopo un breve percorso (si arriva alla 159° pubblicazione a scalare dei Size) si ha la pubblicazione sopra e da sola rende semplice comprendere il motivo per cui esistono Pesi cosi Elevati,per arrivare a un volume da 286K Words:) https://www.forbes.com/worlds-billionaires/
Questo è il peso su disco della pubblicaione piu' vicina all'Average dei Size e i dati sono esatti:)
 234 PUB 69% UN 3808 AV 77 Internal Link Average (ILA) Full SIZE 343 KB (219 ms AV Loading)
234 PUB 69% UN 3808 AV 77 Internal Link Average (ILA) Full SIZE 343 KB (219 ms AV Loading)
891072 VOL. VS 80,262 MB Full SIZE
 Investopedia 241 PUB 70% UN 2993 AV 165 ILA FULL SIZE 417 KB AV (297 ms AV Loading)721313 VOL. DEC 2024 (666852 VOL. NOV 2024) VS 100,497 MB (103,456 MB è stato il peso a NOV 2024) Full SIZE
Investopedia 241 PUB 70% UN 2993 AV 165 ILA FULL SIZE 417 KB AV (297 ms AV Loading)721313 VOL. DEC 2024 (666852 VOL. NOV 2024) VS 100,497 MB (103,456 MB è stato il peso a NOV 2024) Full SIZE 179 PUB 71% UN 2118 AV 69 ILA Full SIZE 83 KB AV (2526 ms AV Loading)
179 PUB 71% UN 2118 AV 69 ILA Full SIZE 83 KB AV (2526 ms AV Loading)
379122 Keywords VOL. VS 14,857 MB Full Size DEC 2024 247 PUB 49% UN 9813 AV 271 ILA FULL SIZE 791 KB (861 ms AV Loading)
DEC 2024 247 PUB 49% UN 9813 AV 271 ILA FULL SIZE 791 KB (861 ms AV Loading)
2423811 VOL. VS 195,624 MB Full SIZESono tanti i domini che hanno avuto le descrizioni e per Linkgraph,i dati "si autodescrivono":)Sistemo solo una curiosita',ed è unita "al core business" di Linkgraph,ed è il Link Building:)La curiosita' è unita al fatto che nei dati di Web FX (il collegamento è sistemato sopra),Linkgraph non è presente in nessuna posizione e occorre ricordare che la "simpatica classifica" (il riferimento è l'anno corrente) è unita alle Revisioni e le chiamano anche Rating,in maniera completamente Abusiva e sono loro a determinare la classifica "degli operatori del Link Building" e il contesto rende molto semplice comprendere il motivo per cui esistono dati cosi asincroni,perche' nei SIZE è presenti "qualsiasi strategia alternativa",rispetto ai Dati Veri,tranne l'unica posizione in grado di generarli e sono gli Original;Unique e Content Value e senza di essi,non si possono nemmeno citare le cazzate unite al Link Building (vengono utilizzate solo per i rilevamenti di base:) perche' non esistono oggettivamente contenuti da unire:) 221 PUB 63% UN 1448 AV 91 ILA FULL SIZE 214 KB AV (244 ms AV Loading)
221 PUB 63% UN 1448 AV 91 ILA FULL SIZE 214 KB AV (244 ms AV Loading)
320008 VOL. VS 47,294 MB Full SIZE
DEC 2024 Site Skipped Status Code 403
 137 PUB 79% UN 979 AV 37 ILA FULL SIZE 162 KB AV (561 ms AV Loading)
137 PUB 79% UN 979 AV 37 ILA FULL SIZE 162 KB AV (561 ms AV Loading)
134123 VOL. VS 22,194 MB Full SIZE

Science Fiction DEC 2024 247 PUB 91% UN 3121 AV 161 ILA Full Size 47 KB AV (113 ms AV Loading)
770887 VOL. DEC 2024 (555714 VOL. NOV 2024) VS 11,690 MB (9,840 MB peso completo a NOV 2024) Full SIZEHadoop 231 PUB 36% UN (75% UN NOV 2024) 3088 AV 133 Internal Links Average (ILA) Full SIZE 59 KB AV (79 ms AV Loading)
713328 VOL DEC 2024 (560254 VOL. NOV 2024) VS 13,629 MB Full SIZEWikidata DEC 2024 241 PUB 61% UN 950 AV 107 Average Internal Links 126 KB AV Size 298 ms AV Loading.
2592 Skipped e 2526 sono stati i Disallow e sono tutti effettivi,perche' i robots txt sono Abilitati e anche Largamente Utilizzati:)228950 VOL. VS 30,366 MB FULL SIZEhttps://dinpoststory.blogspot.com/2024/11/immunity-egregious-violation-unique.html
Per i domini Wikimedia presenti nelle selezioni,esistono dei dati extra,grazie alla presenza di un numero elevatissimo di Skipped e sopratutto dei Disallow uniti ad essi.Nella pubblicazione collegata sopra esistono le descrizioni per arrivare ai dati extra e in realta' sarebbero anche normali,perche' le pubblicazioni esistono realmente e altrettanto reali sono i Disallow e quindi "i Match non sono corretti" e per renderli tali,esistono i Dati Extra e rendono facile comprendere quali sarebbero i reports reali,se Wikimedia "disputasse la Partita correttamente":)Per avere i Dati Extra,sono utilizzati gli Average generali di Wiki Globale,dichiarati da loro stessi (sono all'interno della pubblicazione collegata sopra) e sono formati da 685 termini effettivi;255 KB è l'Average generale dei SIZE e sempre dichiarati da Wiki,esistono perfino gli Average degli EDITS e cioe' delle Modifiche che hanno fatto alle pubblicazioni stesse e non possono essere chiamati Mismatch perche' quasi sempre,non sono presenti nemmeno Strutture Data Valide e quindi "occorre Fidarsi della Malafede" rispetto all'imperatrice del Falso e i dati che aggiungero' sono uniti solo al Divertimento,perche' sarebbe meglio Nasconderli,mentre Wiki se ne vanta e li sistema nei suoi Numeri Generali:) (non si possono chiamare dati,perche' è assente anche la LOGICA:)Occorre aggiungere il Dettaglio piu' Divertente rispetto ai Numeri che seguiranno,perche' Wiki possiede anche 2 Average in 1 solo dominio,grazie al fatto che sono presenti anche gli EDITS dei SIZE e i 685 termini uniti all'Average generale,rappresentano i contenuti che hanno scritto realmente e sono loro ad avere anche gli EDITS e poi esiste anche un altro Average,ed è quello dei termini effettivi presenti in ogni pubblicazione e occorre ricordare che qualsiasi termine HA VALORE,compresi quelli eventualmente sistemati in Hiden e cioe' NON VISIBILI dagli Utenti e il dettaglio è molto importante,perche' il secondo Average,in 1 solo dominio ha dimensioni quasi doppie rispetto al primo:)1940605 VOL. Wikidata Questo sarebbe stato il volume di Wikidata,utilizzando anche le pubblicazioni in Skipped e il dato è anche Ottimista,perche' sarebbe stato difficile utilizzare tutti gli Average dei singoli domini e quindi ho scelto quello generale di Wiki Globale e l'ottimismo deriva dal fatto che sono applicati anche i migliori Average rispetto a tutti gli altri domini Wikimedia:)VS722,415 MB sarebbe stato il SIZE di Wikidata e questi numeri sono uniti al Divertimento,pero' sono Reali ed Effettivi e l'unica variante è il volume dei contenuti a cui sono applicati,perche' è presente l'Average migliore rispetto ai domini Wikimedia,compresa Wikidata:)La posizione dei numeri è fantastica,perche' anche utilizzando il secondo Average presente in 1 solo dominio (il metodo è generale,perche' è utilizzato da tutti gli spazi Wikimedia:) le posizioni non cambiano assolutamente,perche' con un SIZE da 722,415 MB (sono uniti i Disallow e le pubblicazioni selezionate) è possibile anche DEDUPLICARE il Peso dei contenuti e il report resta sempre negativo,perche' è evidente che il peso maggiore,di gran lunga è quello dei codici e al suo interno possono essere presenti solo Strategie Alternative,rispetto ai Dati Veri,perche' quest'ultimi sono formati da Original;Unique e Content Value,ed è l'unica strategia per arrivare ai Dati Veri e per funzionare hanno bisogno di pochissimi codici e l'unica cosa indispensabile è la Natural Intelligence (l'Artificial per esistere ha invece bisogno dei Natural Idiots:) 57226 è il numero di EDITS per Wikidata,utilizzando l'Average generale di WIKI EN (20,2 EDITS sono le modifiche per ogni pubblicazione) e per il momento,l'unico Average assente,almeno nei Numeri ufficiali di Wiki è quello della Guerra degli Edits:)Per avere anche i Numeri delle Guerre degli EDITS,esistono i dati sopra e arrivano dall'Average di WIKI Globale e la pubblicazione ha esattamente le dimensioni dell'Average e l'unica differenza con quelli di Wiki deriva dal fatto che i dati sistemati sono Veri e cioe' i termini che esistono realmente nella pubblicazione.
WM Cloud è Wikitech Wikimedia e quello sopra è un suo Tool e sono presenti i Reverted e cioe' le Guerre degli EDITS,unite alla pubblicazione che ha le dimensioni esatte dell'Average di Wiki EN e i Reverted ne sono stati 185:)https://xtools.wmcloud.org/articleinfo/en.wikipedia.org/Digital_object_identifier
Questo è il Tool specifico che ha la pubblicazione dell'Average di Wiki EN Tramite il collegamento sopra si arriva alla pagina di WM Cloud e per precauzione ho sistemato anche l'URL con la data esatta del prelievo,perche' gli EDITS di Wiki arrivano "a ciclo continuo" e quindi è possibile che dal prelievo alla data di pubblicazione siano gia' diversi:)Esiste l'evidenza dell'Url della pubblicazione;quello di Prose (la descrizione è nella pubblicazione precedente collegata sopra e il riferimento sono i contenuti effettivi,scritti dagli autori wikipediani,dimenticando tutti gli altri termini presenti nella stessa pubblicazione.Per Wiki le dimensioni della pubblicazioni sono minori della meta',rispetto a quelli effettivamente presenti nella pagina:https://en.wikipedia.org/wiki/Digital_object_identifierQuesta è la pubblicazione che ha l'Average di WIKI EN per il suo DEC 2024 e dai suoi numeri arriva anche l'Average dei Reverted e produce il dato sotto unito alle pubblicazioni di Wikidata:)
Sono presenti tutti gli Skipped formati da Disallow effettivi e alcuni codici Canonical (7:) e applicando l'Average dei Reverted si ha la Guerra degli EDITS e sono loro ad arrivare al dato effettivo degli EDITS e sono applicati alle PROSE sistemate sopra e cioe' alle dimensioni che Wikimedia si è "scelta autonomamente",dimenticando tutti gli altri termini effettivi,presenti nella stessa pubblicazione e per i Valori Effettivi dei Dati Veri,qualsiasi termine è importante,compresi quelli in Hiden e sono importanti anche i Whitespace e cioe' gli spazi bianchi tra i termini stessi.Per gli autori Wikipediani,sarebbe meglio avere tutti i termini effettivi,perche' con i dati sistemati sopra,applicare pure gli EDITS,insieme ai loro Reverted,è decisamente la Qualifica Massima dello Scarso:) Oltre al Divertimento,i numeri sistemati (il termine Dato per i SEV,Wikimedia compresa è abolito:) sono molto importanti,perche' tutte le Demenze di Wiki,rendono facilissima l'evidenza delle operazioni alternative ai Dati Veri,ed è solo il NULLA per Tutti,perche' nessun altro spazio possiede una "Concentrazione di Demenza Pura",paragonabile agli spazi di Wikimedia,ed è sufficente solo unire i domini precedenti,per averne la conferma:) Utilizzando solo l'immaginazione,è sufficente unire ad esempio WEB FX sistemato sopra,insieme alle sue Revisioni,chiamate anche Rating e applicate addirittura al Link Bulding e cioe' al Top degli Unnatural Links e solo attraverso la Fantasia,l'unione con "la Concentrazione della Demenza piu' Elevata",ed è quella di Wikimedia,è capace di rendere Ridicolo Web FX e naturalmente qualsiasi altro dominio,unito a operazioni alternative ai Dati Veri e per comprendere l'Entita',è sufficente unire il Size di Wikidata,arrivato solo dalla selezione del suo DEC 2024 ,ed è formato da oltre 720 MB per 2833 pubblicazioni e davanti a questi numeri,qualsiasi operatore SEV,in opposizione ai Dati Veri,diventa del Tutto Evanescente:) 


DEC 2024 233 PUB 93% UN 4287 AV 190 ILA Internal Links Average) Full Size 123 KB AV Loading Average 325 ms.
6037 sono stati gli Skipped e 6019 i Disallow e sono presenti anche 12 codici Canonical:)998871 VOL. DEC 2024 (824400 VOL. NOV 2024)VS28,659 MB (24,750 MB è stato il peso completoa NOV 2024)Anche per WikiQuote sistemo delle curiosita' e la prima,è formata dai Disallow a scalare,solo per la sua selezione di DEC 2024 e occorre ricordare che su 6037 Skipped,i Disallow ne sono stati 6019 e poi esistono anche i codici Canonical,completamente separati dalla realta,semplicemente perche' WikiQuote li ha sistemati Da Sola e cioe' non esiste nessun codice Canonical in realta',perche' non sono originali nemmeno i contenuti e il fatto che siano sistemati in Skipped deriva solo dalla presenza dei codici e non significano assolutamente NULLA,se non dovessero esistere Original;Unique e Content Value e per WikiQuote la Partita è persa in partenza,perche' solo la prima pubblicazione in dimensioni del suo DEC 2024,possiede oltre 3000 EDITS e altrettante Modifiche esistono nelle altre pubblicazioni e quindi,è proprio impossibile che possa esistere un solo codice Canonical,perche' sono le altre pubblicazioni dello stesso dominio a poterlo permettere e cioe' sono le Proposte Complessive a creare i valori e possono arrivare solo da Contenuti Originali e cioe' Scritti Solo Una Volta:) La posizione descritta serve per creare il contesto alla prima pubblicazione dei Disallow di WikiQuote per il suo DEC 2024 e su 6019 presenze nei Disallow,la prima pubblicazione è proprio Recent Changes e il riferimento sono gli EDITS e cioe' è lo stesso dominio che sistema i codici Canonical "Motu proprio" e l'importanza di queste posizioni è molto semplice, perche' le condizioni che possiede Wikimedia,non le ha nessun altro dominio,perche' è una sorta di "Science Fiction delle Violazioni" in opposizione completa alla Logica e nonostante il contesto,esistono Dati Scarsi lo stesso e naturalmente i reports dei domini Wikimedia,vanno letti in maniera completa e cioe' applicando anche gli EDITS e l'importanza della posizione è molto semplice,perche' nei domini Wikimedia,sono presenti tutte le strategie possibili e immaginabili,in opposizione ai Dati Veri,ad iniziare dal fatto che in anni di esperienza,MAI e poi MAI,è esistito UN SOLO CONTENUTO ORIGINALE nei domini Wikimedia e quindi,per "Giusta Causa" esiste la qualifica di Imperatrice del Falso,pero' il contesto dei suoi domini è molto utile,perche' rende ridicoli tutti gli altri "strateghi alternativi" rispetto ai Dati Veri:) Rispetto a Wikimedia,tutti gli altri operatori SEV,sono infinitesimali nei confronti della Fantasia applicata alle Violazioni di Wikimedia e come esempio,è possibile proprio utilizzare la prima pubblicazione dei Disallow di WikiQuote per il suo DEC 2024 ,ed è RECENT CHANGES e il riferimento sono gli EDITS,ed è facile verificare che nessun altro operatore alternativo,rispetto ai Dati Veri, è capace di arrivare a questo livello nella "Fantasia delle Violazioni",perche' è decisamente eccessivo anche per le cazzate degli altri operatori SEV:) Gli utenti degli operatori SEV sono capaci di credere a tutte le cazzate che gli raccontano i loro ottimizzatori,pero' è proprio impossibile raccontargli che si puo modificare l'Original;Unique e Content Value,restando pure Immuni dalle Violazioni,mentre Wikimedia lo fa' proprio in maniera operativa,dedicando anche un Milestone agli EDITS:)Questa è proprio la prima pubblicazione dei Disallow di WikiQuote per il suo DEC 2024,ed è facile individuare anche il contesto specifico rispetto "alla Fantasia delle Violazioni",perche' non solo hanno sistemato in Disallow una pubblicazione dedicata ai RECENT CHANGES,ma è palesemente anche all'interno di Unnatural Links completo,ed è sufficente solo vedere il cursore laterale,per immaginare quanto sia lungo il percorso,generato da una sola pubblicazione:) Per avere l'elenco di Disallow sopra,unito a 1 sola pubblicazione,significa che debbono esistere dei collegamenti e le probabilita' che possano essere naturali,sono uguali a ZERO:)E' il record della Fantasia applicata alle Violazioni,perche' esistono in maniera Esplicita i Recent Changes e cioe' gli EDITS;è applicato un Disallow e vengono sistemati solo per bypassare il Limit Rate e sempre la stessa pubblicazione è in palese Unnatural Links,ed è sufficente solo vedere il cursore laterale,per avere un idea di quante pubblicazioni siano unite ad essa,ed è possibile scommettere che nessun altro operatore SEV è capace di arrivare a questo livello di demenza concentrate in 1 sola posizione e quindi i domini Wiki "sono una preziosa risorsa",perche' rappresentano il "miglior volano" per attivare il Divertimento,nei confronti di qualsiasi altro operatore SEV:) Questa è la stessa posizione sistemata sopra,pero' con la sezione finale e cioe' il dominio WikiQuote ha i robots txt attivati (è lo Status Code 200) e sono anche largamente utilizzati,ed è facile verificarlo grazie al percorso del cursore laterale e occorre ricordare che tutti i Disallow presenti sono generati da 1 sola pubblicazione e naturalmente il riferimento non è la selezione di Wikiquote per il suo DEC 2024,ma l'intero dominio e comunque,le pubblicazioni selezionate possiedono lo stesso un numero rilevante,perche' unendo anche i Disallow,tutta la selezione di DEC 2024 per WikiQuote,forma quasi 1/9,rispetto a tutte le pubblicazioni del dominio.Questi sono i dati attuali di Wikiscan,rispetto alla data di questa pubblicazione e per WikiQuote esistono 55000 pubblicazioni (6270 sono i Post di DEC 2024 per WikiQuote) e 3,4 Milion sono gli EDITS del dominio e poi esiste la posizione curiosa delle Quotes stesse,ovviamente del Tutto Sballate,ad iniziare dal fatto che i Content Originali,non appartengono agli autori di Wikimedia e la curiosita deriva dal fatto che i domini dedicati esplicitamente alle Quotes,all'interno di Wikimedia, sono formati da 97 spazi e hanno tutti le impostazioni appena descritte:) Edits ;Disallow e Link Building,tutti uniti insieme,oltre al numero piu' Divertente di WikiQuote,ed è quello dei suoi "Presunti Autori" e nel Caso specifico di WikiQuote EN,ne sono 53000 e sistemano "Contenuti di altri autori" e sono loro a ricevere gli EDITS;i Disallow e i Link Building,quasi sempre sistemati tutti insieme e per questo motivo,la simpatica Wiki,possiede "la Giusta Qualifica" di Imperatrice del Falso:) (Nessuna è come LEI:)
Grazie alle pubblicazioni nelle dimensioni a scalare di WikiQuote,è possibile aggiungere "un altra perla nella corona" dell'Imperatrice del Falso ed è l'assenza completa di Main Content e cioe' del Core Pilars del Page Quality Rating e la posizione aiuta tantissimo a comprendere i Dati Veri,perche' tutti gli altri operatori SEV,nemmeno ad anni luce,possiedono "le impostazioni fantasiose" di Wiki:)https://copyvios.toolforge.org/?lang=en&project=wikiquote&title=Love&oldid=&action=search&use_engine=1&use_links=1&turnitin=1
Per comprendere le impostazioni fantasiose di Wiki e quindi a scalare notevolmente anche rispetto a tutti gli altri operatori SEV e cioe' gli alternativi rispetto ai Dati Veri (la scala è lunga anni luce,quasi in senso reale:) esiste la posizione sopra:)https://en.wikiquote.org/wiki/LovePer comprendere la Fantasia di Wiki,unita alle violazioni,occorre descrivere le posizioni sistemate.Il collegamento appena sistemato,è la prima pubblicazione in dimensioni di WikiQuote per il suo NOV 2024 e occorre ricordare che è arrivata dopo 6019 Disallow,Tutti Effettivi e cioe' sono stati gli operatori stessi di Wiki a sistemare i Disallow.L'altro collegamento è il piu' Divertente in assoluto e a parte i reports,il Divertimento inizia dal fatto che lo strumento appartiene anch'esso a Wikimedia (ToolForge è all'interno di Wikitech anch'esso presente in questa DEC 2024) e la proprieta' si nota subito,perche' la simpatica Wiki non ha nessuna dimestichezza con i numeri e il report sopra è una prova:lo strumento è dedicato al Plagiarsim e alle violazioni dei Copyright e gia' il contesto,applicato a Wikimedia è un Nonsense,perche' la sua "Vocazione Reale è rivolta solo alle Violazioni" e quindi si trova a disagio nel descrivere quelle dei Copyright e di sicuro,è il motivo reale per cui esiste la Divertente percentuale,solo rispetto al primo elemento a cui appartengono i contenuti:)Nel Report di Wiki,il primo dominio ad avere l'Originalita' dei Contenuti raggiunge il 78,5%,ed è Divertente la definizione:SOSPETTA VIOLAZIONE:)Il Plagiarism è una violazione piena,ed è sufficente arrivare al 5% dei contenuti presenti in una pubblicazione:)
Questo è il calculator ufficiale e i dati sono esatti e a queste dimensioni è applicata la percentuale del 78,5% in Plagiarsim e lo strumento è sempre di Wikimedia e ha definito la posizione "Sospetta Violazione":)In altre pubblicazioni sistemero anche un altra sezione divertente,ed è quella dedicata alla violazione dei copyright e il senso del Divertimento è molto semplice:https://en.wikipedia.org/wiki/Wikipedia:Copyright_violations
è gia scritto in questo collegamento,ed è lo stesso di ToolForge e cioe' sempre Wikimedia e per comprendere il Divertimento è sufficente unire l'esperienza di anni e cioe' posso assicurare al 100% che i contenuti sono esattamente uguali e cioe' per Wikimedia,la violazione del copyright è unita al Paraphrasing e cioe' è il riordino dei termini (in pratica sono le operazioni reali delle AI dopo aver fatto pure Scraping:) e lo dicono LORO,dopo aver sistemato Billion di EDITS:)In prossime pubblicazioni ci saranno altre descrizioni,perche' adesso è arrivato il Top del Divertimento,capace di anichilire tutti gli altri operatori SEV,perche' nessuno è capace di arrivare "all'Olimpo del Falso" detenuto da Wiki e la posizione è importante perche' è capace da sola di resettare tutte le cazzate degli altri operatori SEV:)https://copyvios.toolforge.org/?lang=en&project=wikiquote&title=Love&oldid=&action=search&use_engine=1&use_links=1&turnitin=1Questa è la posizione piu' Divertente,ed è utilissima per comprendere il livello degli altri operatori SEV.Ho risistemato il collegamento di ToolForge (è Wikitech Wikimedia) per aggiungere altri dettagli all'URL sistemato per esteso,perche' dopo averlo digitato occorre fare l'iscrizione (è gratuita:) e poi scegliere le impostazioni.Attraverso l'espansione a scalare,dopo aver fatto la registrazione,si fanno queste selezioni e si hanno i dati appena sistemati e naturalmente non è possibile garantire NULLA,rispetto ai Numeri di Wikimedia,pero' attualmente sono quelli appena sistemati e nella 3° posizione del Plagiarism,uniti alla SOSPETTA VIOLAZIONE,dopo la prima al 78,5% ;esiste la 2° al 41,2% (i numeri per Wikimedia sono un OPTIONAL e lo è anche per il suo strumento:) esiste la fantastica 3° posizione del Plagiarism unito alla prima pubblicazione in dimensioni di WikiQuote EN per il suo DEC 2024 e raggiunge il 36,3%,sempre come SOSPETTA VIOLAZIONE:)Il Plagiarism è gia' in Violazione al 5% e naturalmente avendo una pubblicazione da oltre 90K termini effettivi,è molto facile essere in Plagiarism e poi lo strumento di Wiki ha aggiunto il Plus al Divertimento,perche' la 3° posizione è occupata da New Advent e cioe' l'enciclopedia cattolica sistemata sopra:)
https://www.newadvent.org/fathers/170207.htm
Questo è "Sospetta Violazione" al 36,3% (dopo le prime 2:) per lo strumento di Wiki,analizzando una pubblicazione sempre all'interno di Wikimedia,attribuendo a New Advent "l'originalita' dei contenuti" (è equivalente al bue che da del cornuto all'asino:),rispetto a una pubblicazione che non è nemmeno Eliggibile e occorre ricordare che nel contesto online,Tutti i Dati sono Provvisori,tranne il Report sopra del Rick Result e quando arriva la posizione negativa, è Perpetua:)
https://en.wikiquote.org/wiki/Elvis_Presley
Questa è un'altra posizione interessante da unire ai dati sistemati,perche' è la pubblicazione a maggior dimensioni di WikiQuote,ed è arrivata grazie ai Click Depth e non puo essere presente in nessuna selezione,perche' ha una dimensione largamente maggiore a 100K termini in 1 sola pagina.Questa è la pubblicazione dedicata a Elvis Presley e oltre alle sue dimensioni,è utile per dimostrare che i dati sistemati non sono Casuali e non potrebbe nemmeno esserlo,perche' le False Quotes di Wiki,derivano da altri autori,completamente estranei al dominio.E' presente sempre la SOSPETTA VIOLAZIONE e questa volta raggiunge il 93,3%,rispetto a una pubblicazione da oltre 235K termini,sistemati in 1 sola posizione:)Il contesto descritto puo essere esteso a tutti i domini Wikimedia,perche' le impostazioni sono esattamente uguali,ed essendo la grande organizzazione Wikimedia al Vertice Assoluto del Falso,i reports sono utilissimi per comprendere la demenza di tutti gli altri operatori SEV e cioe' sono a tutti gli effetti "dei Ricercatori delle Gravi Violazioni",utilizzando solo la Logica e grazie a Wiki è facile comprendere il suo senso pieno:)https://elviscollector.info/
http://www.elvis-history-blog.com/elvis-voting.html
https://www.elvisconcerts.com/real/oct74-01.htm
Tra i domini presenti nelle SOSPETTE VIOLAZIONI,rispetto alla pubblicazione di WikiQuote (cioe' sono gli spazi che hanno i contenuti originali) esistono le 3 posizioni sopra e Elvis Collector è realmente la prima (ha una SOSPETTA VIOLAZIONE da 81,3%,mentre la violazione piena del Plagiarism inizia dal 5% ed è valida per qualsiasi dominio,Wiki compresa:) e poi esistono anche gli altri domini e posso assicurare che sono fatti molto bene e sono anche bellissimi:)
Amazines Assente DEC 2024
 Lib Quotes 249 PUB 68% UN 1035 AV 92 ILA Full SIZE 68 KB AV (595 ms AVL)
Lib Quotes 249 PUB 68% UN 1035 AV 92 ILA Full SIZE 68 KB AV (595 ms AVL)
257715 VOL. VS 16,932 MB Full SIZE 90 PUB 73% UN 1112 AV 40 ILA Full SIZE 62 KB AV (507 ms AVL)
90 PUB 73% UN 1112 AV 40 ILA Full SIZE 62 KB AV (507 ms AVL)
100080 VOL. VS 5,580 MB Full SIZE
236 PUB 14% UN (67% UN è stata l'unicita a NOV 2024) 891 AV 76 ILA4281 sono gli skipped e 4262 sono stati i Disallow. Full Size 43 KB AV (300 ms AVL)210276 VOL. VS 10,148 MB Full SIZE
Applicando anche a Wiki Semantic l'Average generale di Wiki EN e cioe' il piu' Ottimista rispetto a tutti gli Spazi Wikimedia,il volume di Wiki Semantic per il suo DEC 2024 è formato da 3094145 VS1151,835 MB in Full Size e i dati sono molto importanti,perche' il riferimento è solo la selezione di DEC 2024 per Wiki Semantic nel Caso specifico e il suo report è gia decisamente scarso solo con "la selezione normale" (236 Post e 14% in Unicita per 891 termini in Average:) e occorre considerare che la selezione è stata possibile dopo aver attraversato 4262 pubblicazioni in Disallow,solo a DEC 2024 e il Limit Rate è Effettivo e cioe' sono stati proprio gli operatori di Wiki Semantic a sistemare i Disallow:)Alla selezione complessiva di DEC 2024 di Wiki Semantic,occorre aggiungere anche gli EDITS oltre ai Disallow,per comprendere quali sarebbero i valori reali,se fossero presenti le impostazioni dei Dati Veri e solo gli EDITS ne sono 91243 e il paradosso è unito al fatto che i numeri sono anche ottimisti,perche' in realta' non esiste nessuna Struttura Data valida e gli Average degli EDITS derivano "solo dai Numeri di Wikimedia" e grazie ai medesimi è possibile aggiungere anche l'Average dei Reverted e cioe' delle guerre degli EDITS stessi e per tutte le selezioni di DEC 2024,solo per Wiki Semantic,i Reverted ne sono 835645:) Anche i Reverted derivano dagli Average di Wikimedia e per gli autori wikipediani sarebbe meglio nasconderli ,perche' la loro Vera Applicazione,non è unita ai dati sistemati (cioe' le pagine complete con tutti i termini effettivi presenti) ma all'Average che Wikimedia si "Crea da SOLA":) E' il PROSE citato sopra e quasi sempre è minore alla meta' del vero Average e cioe' dei termini effettivi presenti in qualsiasi pagina ,ed è proprio il Prose ad avere tutti gli Average:)
https://dinpoststory.blogspot.com/2024/11/immunity-egregious-violation-unique.html
La sezione evidenziata dal colore rosso è il senso di PROSE e cioe' è presente "solo una sezione di termini" (Wiki la chiama la Main Sections) ,pero' esistono anche gli altri nella stessa pagina e sono altrettanto importanti ,perche' sono dei termini effettivi anch'essi e tra l'altro quasi sempre,hanno dimensioni nettamente maggiori pure:) In questa posizione il PROSE secondo Wiki,assume una Rilevanza Fantastica,rispetto al Divertimento,perche' tutti i Numeri sistemati degli EDITS;dei Reverted;dei SIZE hanno come riferimento per i loro calcoli,gli Average dei domini Wikimedia e sono uniti proprio al Prose sistemato sopra e producono dei reports davvero inbarazzanti,rispetto ai simpatici autori Wikipediani,perche' i reports sono scarsi;i contenuti non sono originali e l'insieme è applicato ad Average con dimensioni,minori rispetto ai termini effettivi presenti nella stessa pagina e l'impostazione è presente in qualsiasi dominio Wikimedia:)
https://dinpoststory.blogspot.com/2022/01/natural-contest-true-data-priority-5.html
L'impostazione unita a PROSE e cioe' a meno della meta' rispetto ai termini effettivi in 1 pagina dei domini Wiki (tutti gli Average citati derivano da questo contesto) assume un ruolo Divertentissimo,rispetto allo spazio di Wiki Semantic e l'importanza di queste posizioni è sempre unito al "Ruolo Apicale" di Wikimedia,nell'Universo dei Search Egregious Violation e cioe' del Falso Totale e quindi grazie ai domini Wiki è possibile prendere per il culo,in maniera legittima,tutti gli operatori alternativi ai Dati Veri,perche' fanno esattamente le stesse cose di Wikimedia,pero' su scala molto piu' ridotta e non per "mancanza d'idiozia",ma per quella della Fantasia,applicata alle Violazioni:) La definizione di Semantica,rappresenta proprio la Fantasia delle Violazioni e per comprenderla meglio,occorre aggiungere anche la posizione sotto:
Il collegamento in cui sono sistemati i contenuti della sezione è lo stesso sopra e la posizione nasce dalla Digital Semantic di EU,ed è valida anche per Wiki Semantic:) E' sufficente applicare la definizione di Semantica (l'interpretazione del significato ETC) alle impostazioni di Wiki Semantic,unendo anche la posizione operativa reale,rispetto agli autori dei contenuti,a cui applicare la Semantica,ed è l'IGNORE Totale e cioe' non sanno assolutamente quello che hanno realmente scritto gli autori,insieme all'altro IGNORE e cioe' non conoscono l'autore originale,sopratutto nel contesto dei contenuti tradizionali e per esperienza,l'IGNORE specifico "ha solide fondamenta" e cioe' è molto facile trovare Plagiarism,nei contenuti degli autori tradizionali :)
Quello descritto è il contesto reale della Semantica e quindi figurarsi cosa significa aggiungere anche il Digital alle "Interpretazioni Semantiche" e cioe' è Puro Divertimento,perche' l'elemento d'unione unico delle "Interpretazioni Semantiche" è l'IGNORE e grazie a Wiki Semantic il Divertimento arriva al Top,perche' l'IGNORE esiste sempre,pero Wiki aggiunge anche tantissimi EDITS alle "Interpretazioni Semantiche stesse":)
https://www.semantic-mediawiki.org/w/index.php?title=semantic-mediawiki.org:Community_portal&action=history
E' veramente Divertente "la Semantica Digitale di Wiki",ad iniziare dal fatto che non esiste proprio nessun contenuto originale e la posizione sopra è quella delle Revisioni e la pubblicazione protagonista è la prima in dimensioni,rispetto alla selezione di DEC 2024 di Wiki Semantic,ed è quella dei Fix ai Bugs:) (le 2 evidenze possono essere selezionate e si hanno i reports anche dei mesi o anni,rispetto alle Revisioni e cioe' agli EDITS di Wiki Semantic e quindi è possibile dire Addio ad ogni "Interpretazione Semantica",perche' solo nell'arco temporale necessario "per elaborare qualche pensiero semantico",i contenuti di Wiki Semantic sono gia' cambiati tante volte:) E' decisamente difficile applicare "Interpretazioni Semantiche" per Wikimedia,perche' oltre agli EDITS,non sono valide nemmeno le Strutture Data :)


DEC 2024 WIKI IT 209 PUB 85% UN 2527 AV 166 ILA 2792 sono gli skipped e 2670 sono Disallow. Full SIZE 139 KB AV (216 ms AVL)528143 VOL. DEC 2024 (569644 VOL. NOV 2024) VS 29,051 MB (27,348 MB è stato il peso a NOV 2024) FULL SIZE2055685 (Volume generale DEC 2024)E' formato dall'unione delle pubblicazioni selezionate e quelle in Disallow,attraverso l'Average generale di Wiki ENVS765,255 MB (Size generale DEC 2024)Il peso colossale deriva sempre dalle selezioni di Wiki italiana,nel suo DEC 2024,ed è utilizzato l'Average di Wiki EN,pero' attraverso una differenza notevole,perche' il Peso è applicato a tutte le presenze sistemate nelle pubblicazioni selezionate:)Il contesto è molto importante,perche' il volume dei Content sistemato sopra è unito in realta' solo al PROSE (2055685 Words:) e cioe' è il Self Serving Data di Wikimedia,nel vero senso delle parole perche' gli Average generali dei suoi contenuti,sono fatti proprio nel modo indicato dal PROSE:)E' importante questa posizione,per avere il TOP Generale del Falso,nei confronti di tutti gli altri operatori SEV,perche' nessun altro spazio è capace di raggiungere i Numeri sistemati e anche ipotizzando che esistano tutti i contenuti effettivi,presenti in ogni pubblicazione (in pratica sono formati dal doppio rispetto ai PROSE:),sono lo stesso Polverizzati dai SIZE,perche' è evidente che il peso maggiore rispetto a 750 MB,solo per la selezione di Wiki italiana,appartiene ai codici e non esiste nessun dubbio che non siano quelli operativi,ma quelli uniti a tutte le strategie alternative,rispetto ai Dati Veri (è il Reports at a Glance:) e l'aspetto Divertente deriva dal fatto che non esiste nessuna Strategia Alternativa e l'unica possibilita' è quella di avere Original;Unique e Content Value e tutte le altre opzioni,nella migliore delle ipotesi fanno parte solo della Teoria,pero' non ne esiste nemmeno UNA che abbia la Credibility:)DEMONSTRATE JUICE ARCHIVE DATA è l'Unica Via dei Dati Veri e il resto è tutto Invalid e quindi,grazie all'Iperbole della Demenza unita a Wikimedia,il Divertimento è assicurato nei Secoli dei Secoli e gli elementi piu' Divertenti,non sono gli operatori SEV,ma gli utenti che pagano i loro "presunti servizi":) Questo è l'Average di Wiki italiana per i contenuti effettivi,ed è attuale rispetto alla data di questa pubblicazione.
L'Average è generale,per tutto il dominio di Wiki italiana e i numeri sistemati sono "esclusivamente quelli di Wikimedia",ed è altrettanto esclusivo il contesto da cui derivano,ed è quello delle PROSE e cioe' meno della meta',rispetto ai termini effettivi presenti nella pagina:)
Per arrivare ai dati del PROSE e quindi "degli Average a Fantasia" di Wiki (in questo Caso il riferimento è il dominio in lingua italiana e gli altri sono esattamente uguali:) la migliore soluzione è nelle selezioni,grazie al Sense of Humor,unito al report sopra,ad iniziare dal nome della pubblicazione specifica,prima nelle dimensioni per il DEC 2024 di Wiki IT:)Wikipedia,Pareri su Wikipedia è stata la prima pubblicazione in dimensioni,dopo aver attraversato 2526 Disallow e lo sono tutti realmente e cioe' sono stati "gli Astuti Autori Wikipediani" a scegliere il Limit Rate:)https://it.wikipedia.org/wiki/Wikipedia:Pareri_su_Wikipedia
Questa è la pubblicazione prima in dimensioni a DEC 2024 per Wiki IT e grazie al Calculator ufficiale esiste la conferma che le dimensioni sono esatte e quindi è possibile passare al Divertente Prose di Wikimedia:)WM Cloud è Wikitech Wikimedia e cioe' sempre "la grande organizzazione di Wiki" e la pubblicazione è quella "dei Pareri su Wikipedia" formata da oltre 14K termini effettivi.Tra i numeri di Wiki ho evidenziato quello del Bugs,perche' è decisamente divertente e il riferimento è quello sotto:)
Per Wiki IT questo è il Bug che si è Data da Sola e il Divertimento deriva dal fatto che la "Simpatica Wiki" ha sempre Grandi Preoccupazioni per il NULLA perche' la presenza o meno del Detect Language è OPTIONAL e se non fosse presente non cambia assolutamente nulla (il Detect language è rilevato in maniera automatica e l'unico problema è la presenza Multipla di Lingue in 1 solo dominio).Il Vero Bug dovrebbe invece essere la Grande Preoccupazione di Wiki,perche' lei opera grazie "al business delle donazioni" e puo farlo grazie esclusivamente all'Esistenza del contesto online e se fossero operative le idee di Wikimedia e a scalare di tutti gli operatori SEV,potrebbero dire ADDIO al business delle donazioni e a qualsiasi altro,ed è sufficente sistemare solo il primo VERO BUG e lo è proprio in senso fisico,non esiste nessun BUGS prima di LUI,ed è facile comprenderlo perche' il primo VERO BUG,è solo il Sospetto di Aver Violato la Fundamental Search e la posizione è davvero Divertente da unire a tutti i domini Wikimedia,perche' Non esiste solo il Sospetto,grazie al fatto che la Violazione della Fundamental Search,è proprio Integrale,ad iniziare dalle posizioni del PROSE sotto:)
Questi sono i Dati del PROSE e cioe' il Vero BUG di Wiki :)Da oltre 14K termini effettivi,per Wiki esistono 4009 e occorre ricordare che il suo SIZE,visibile in tutte le comparazioni,arriva proprio da questi dati completamente sballati e nel Caso specifico sono formati da 25611 bytes ed è il SIZE sempre del PROSE :)



Wiki Cebuana 196 PUB 63% UN 1303 AV 137 ILA (Internal Links Average) Full Size 116 KB AV 387 ms (millesimi di secondo).Skipped 5786 e 5630 sono i suoi Disallow (sono presenti anche 29 codici Canonical)255388 VOL DEC 2024 (181043 VOL. NOV 2024) VS 22,736 MB (16,942 MB peso a NOV 2024) Full Size4097670 è il volume generale di Wiki Cebuana,calcolando anche le pubblicazioni in Disallow che ha avuto e l'Average è quello di WIKI EN e deriva sempre dalle "impostazioni del PROSE" e cioe' non è presente il 2° Average,ma solo i numeri che Wiki "si è Data da Sola":) VS1525,410 MB è il colossale Peso della selezione di Wiki Cebuana per il suo DEC 2024 e anche questo Dato deriva dall'Average di WIKI EN,pero' non è unito al Prose,ma ai Pesi Veri:)120836 sono invece gli EDITS di tutte le selezioni di DEC 2024,per Wiki Cebuana e il dato è molto pertinente da sistemare in questa posizione,perche' le pubblicazioni in Disallow presenti a DEC 2024 per Wiki Cebuana,hanno determinato anche le selezioni effettive,ed è indispensabile conoscere come sono state realizzate e a parte gli Automated Content al 100% dichiarati da Wiki stessa,esistono anche 120K EDITS solo nella selezione di DEC 2024 per Wiki Cebuana e quindi se non fossero stati presenti i Disallow,i reports non sarebbero cambiati:) 
 Wiki DE 235 PUB 91% UN 3629 AV 433 ILA 484 sono stati gli Skipped per Wiki DE a DEC 2024 e per i domini Wikimedia è un record perche' sono state solo 469 pubblicazioni ad essere in Disallow:) (1670 Skipped e 1659 Disallow a NOV 2024). Full SIZE 171 KB AV (228 ms AVL)
Wiki DE 235 PUB 91% UN 3629 AV 433 ILA 484 sono stati gli Skipped per Wiki DE a DEC 2024 e per i domini Wikimedia è un record perche' sono state solo 469 pubblicazioni ad essere in Disallow:) (1670 Skipped e 1659 Disallow a NOV 2024). Full SIZE 171 KB AV (228 ms AVL)ITra i domini Wikimedia,a memoria,non ricordo uno spazio che abbia mai avuto un numero di Disallow "cosi basso" e naturalmente la posizione è solo relativa agli spazi di Wiki,perche' i Disallow sono in realta' esattamente il doppio,rispetto alle pubblicazioni selezionate solo a DEC 2024 per Wiki DE:)
Questa è la pubblicazione prima nei Disallow e forma un Record per gli spazi Wikimedia,perche' mai prima sono esistite cosi poche pubblicazioni presenti nei Disallow in 1 sola selezione e il paradosso del record deriva dal fatto che in realta esistono 469 pubblicazioni e cioe' esattamente il doppio rispetto a tutte le selezioni e i Disallow sono reali e cioe' sono proprio gli operatori di WIKI DE ad aver sistemato le pubblicazioni in questo modo e la posizione non è unita solo alla curiosita del Record,rispetto agli altri domini Wikimedia, perché possiede in realta' un contesto molto importante,ed è indicato dall'evidenza del cursore,ed è sufficiente vedere il suo percorso generato da 1 sola pubblicazione e si comprende facilmente per quale motivo esistono i Disallow:)
Il motivo è quello degli Unnatural Links,chiamati anche Link Building (è il Top dell'Unnatural:) e i Disallow sono utilizzati nel Limit Rate,ed è una Grave Penalita' esso stesso,ed è capace solo di peggiorare la situazione,generata dagli autori stessi,tramite il Link Building:)
La posizione è davvero Divertente,perche' tutto il percorso del cursore laterale,è generato da una sola pubblicazione e quindi è sicura la "presenza massiccia " di Unnatural Links e il contesto Divertente deriva dal fatto che la posizione sopra unita alla prima pubblicazione dei Disallow di Wiki DE,rappresenta un Record,rispetto agli altri spazi Wikimedia e lo è realmente,perche' mai prima sono esistiti dati nei Disallow cosi' bassi e quindi è facile comprendere cosa siano quelli degli altri domini Wikimedia,perche' mediamente sono maggiori del doppio,rispetto al numero di Disallow di Wiki DE nel suo DEC 2024:)
https://de.wikipedia.org/wiki/Wikipedia:L%C3%B6schkandidaten/UrheberrechtsverletzungenQuesta è la prima pubblicazione dei Disallow di WIKI DE,ed è il Record per gli spazi Wikimedia e la posizione serve a ricordare che i Disallow sono effettivi e cioe' i robots txt sono Abilitati (è lo Status Code 200) e la pubblicazione specifica è effettivamente in Disallow.
L'User Agent utilizzato è di Microsoft Bing nei Device mobili e per i Desktop è esattamente la stessa cosa e lo è anche per gli User Agent di Google e occorre ricordare questa posizione,perche' potrebbero esistere anche le selezioni specifiche rispetto agli Engines citati e non è il Caso dei domini Wiki,perche' i Disallow sono totali e posso assicurare che è presente anche l'User Agent di Baidu Render per i Desktop:)



Wiki France DEC 2024 230 PUB 88% UN 5177 AV 399 ILA 1745 Skipped e 1725 sono i Disallow. Full SIZE 233 KB AV (500 ms AVL)
1190710 VOL. DEC 2024 (777803 VOL. NOV 2024) VS 53,590 MB (39,767 MB è stato il peso completo a NOV 2024) Full Size


Wiki Global 238 PUB 83% UN 5454 AV 580 ILA1227 Skipped e 1215 sono i Disallow. Full SIZE 255 KB AV (293 ms AVL)
1298052 VOL. DEC 2024 (1792010 VOL.NOV 2024) VS 60,690 MB (76,956 MB è stato il peso a NOV 2024) Full SIZESe fossero presenti tutte le pubblicazioni compresi i Disallow di WIKI EN per il suo DEC 2024,utilizzando l'Average dei suoi Prose,si ha il volume sotto:1003525 Words,ed è formato dall'Average generale di WIKI EN,ed è quello del PROSE:)373,575 MB è invece il peso effettivo che hanno tutte le pubblicazioni selezionate a DEC 2024 per Wiki EN,compresi i Disallow,sistemati accuratamente dagli operatori di stessi:)Con questi dati,non è possibile che inizi nessuna Partita e occorre aggiungere che per Arrivarci sono stati utilizzati 29593 EDITS e derivano da 271025 Reverted,solo per DEC 2024 di Wiki EN ,ed è "nell'Olimpo del SEV" e cioe' oggettivamente WIKI EN possiede anche i dati migliori rispetto a tutti gli altri domini Wikimedia e la posizione è molto importante,perche' grazie alla presenza simpatica di Wiki,rispetto a tutti gli altri operatori SEV,garantisce il Divertimento massimo,perche' nessun altro operatore alternativo ha il contesto di Wikimedia e cioe' fanno esattamente le stesse cose,pero' su Scala molto piu' Ridotta,ad iniziare dal fatto che non hanno la capacita tecnica di Wikimedia e sopratutto non hanno la sua "Fantasia Applicata alle Violazioni":)


Wiki ES 206 PUB 89% UN 3750 AV 221 ILA Full SIZE 172 KB AV (293 ms AVL) Skipped 2567 e 2459 sono stati i Disallow.
772500 VOL. VS 35,432 MB Full Size DEC 2024 247 PUB 65% UN 2009 AV 130 ILA Full SIZE 324 KB (307 ms AVL)496223 VOL. VS 80,028 MB Full Size
DEC 2024 247 PUB 65% UN 2009 AV 130 ILA Full SIZE 324 KB (307 ms AVL)496223 VOL. VS 80,028 MB Full Size

DEC 2024 206 PUB 85% UN 7464 AV 27 ILA Full SIZE 135 KB AV (417 ms AVL)
1537584 VOL DEC 2024 (1105851 VOL.NOV 2024) VS 27,810 MB (21,311 MB peso a NOV 2024) Full SIZE
 230 PUB 85% UN 2500 AV 12 ILA Full SIZE 119 KB AV (617 ms AVL)575000 VOL. VS 27,370 MB FULL Size
230 PUB 85% UN 2500 AV 12 ILA Full SIZE 119 KB AV (617 ms AVL)575000 VOL. VS 27,370 MB FULL Size Enciclopedia Storica Economia DEC 2024 218 PUB 75% UN 2944 AV 115 ILA Full SIZE 162 KB Average (1333 ms AVL)
Enciclopedia Storica Economia DEC 2024 218 PUB 75% UN 2944 AV 115 ILA Full SIZE 162 KB Average (1333 ms AVL)
641792 VOL DEC 2024 (714502 VOL. NOV 2024) VS 48,832 MB (26,966 MB Peso a NOV 2024) Full Size
 238 PUB 66% UN 691 AV 34 ILA Full SIZE 117 KB AV (126 ms AVL)
238 PUB 66% UN 691 AV 34 ILA Full SIZE 117 KB AV (126 ms AVL)
164458 VOL. VS 27,846 MB Full SizeU Enciclopedia World History 214 PUB 74% UN 2797 AV 110 ILA Full SIZE 226 KB AV (179 ms AVL)
Enciclopedia World History 214 PUB 74% UN 2797 AV 110 ILA Full SIZE 226 KB AV (179 ms AVL)
598558 VOL. VS 48,364 MB Full SizeElsevier 243 PUB 71% UN 1136 AV 24 ILA 219 KB FULL SIZE 237 ms AV Loading.
276048 VOL. DEC 2024 VS 53,217 FULL SIZE
Copyright 225 PUB 74% UN 1877 AV 48 ILA Full SIZE 48 KB AV (671 ms AVL)
422325 VOL. VS 10,800 MB Full SIZEJustice GOV 219 PUB 56% UN 1168 AV 77 ILA 95 KB AV Full SIZE 577 ms AV Loading.255792 VOL. VS 20,805 MB Full SizeDEC 2024 217 PUB 72% UN 4477 AV Full SIZE 188 KB AV 164 AV ILA (Internal Links Average) 328 ms (millesimi di secondo) AV Loading971509 VOl. VS 40,796 Full Size 235 PUB 62% UN 1148 AV 66 ILA Full Size 201 KB (647 ms AVL)269780 VOL. VS 47,235 MB Full Size
235 PUB 62% UN 1148 AV 66 ILA Full Size 201 KB (647 ms AVL)269780 VOL. VS 47,235 MB Full Size DEC 2024 240 PUB 65% UN 1600 AV 47 ILA (Internal Links Average) Full SIZE 148 KB AV (87 ms AVL)384000 VOL. VS 37,920 MB Full Size
DEC 2024 240 PUB 65% UN 1600 AV 47 ILA (Internal Links Average) Full SIZE 148 KB AV (87 ms AVL)384000 VOL. VS 37,920 MB Full Size

Philpapers DEC 2024 217 PUB 76% UN 4438 AV 290 ILA Full SIZE 132 KB Average (1664 ms AVL)
963046 VOL. VS 28,644 MB Full SizeAssente DEC 2024
Assente DEC 2024W Time Magazine 164 PUB 68% UN 1352 AV 60 ILA Full SIZE 204 KB AV (308 ms AVL)
Time Magazine 164 PUB 68% UN 1352 AV 60 ILA Full SIZE 204 KB AV (308 ms AVL)
221728 VOL. VS 33,456 MB Full Size
 OUR World Data Oxford 229 PUB 72% UN 2484 AV 50 ILA 120 KB Full SIZE 262 ms AV Loading
OUR World Data Oxford 229 PUB 72% UN 2484 AV 50 ILA 120 KB Full SIZE 262 ms AV Loading
568836 VOL DEC 2024VS27,480 MB Full SIZEDCE Data Juice 226 PUB 59% UN 1641 AV 60 ILA Page SIZE 390 KB AV (216 ms AVL)
370866 VOL. VS 88,140 MB in Page SIZE
Science Software (SCNSOFT) DEC 2024 224 PUB 59% UN 2337 AV 144 ILA FULL SIZE 481 KB AV (221 ms AVL)
579988 VOL VS 117,364 MB Full Size Enciclopedia Britannica 249 PUB 72% UN 1419 AV 99 ILA FULL SIZE 109 KB AV (414 ms AVL)
Enciclopedia Britannica 249 PUB 72% UN 1419 AV 99 ILA FULL SIZE 109 KB AV (414 ms AVL)
353331 VOL. DEC 2024 (295100 VOL.NOV 2024) VS 27,141 MB (24,516 MB peso NOV 2024) Full Size SEC GOV 182 PUB 75% UN 3832 AV 74 ILA Full SIZE 108 KB AV (226 ms AVL)
SEC GOV 182 PUB 75% UN 3832 AV 74 ILA Full SIZE 108 KB AV (226 ms AVL)
635816 VOL. DEC 2024 (233320 VOL. NOV 2024) VS 20,304 MB (15,504 MB Peso a NOV 2024) Full Size
 SEP 2024 217 PUB 95% UN 8347 AV 93 ILA Full SIZE 135 KB Average (510 ms AVL) DEC 2024 225 PUB 95% UN 9072 AV 103 ILA Full SIZE 131 KB Average (229 ms AVL)2041200 VOL. DEC 2024 (1524453 VOL. NOV 2024) VS 29,475 MB (26,793 MB Peso a NOV 2024) Full Size
SEP 2024 217 PUB 95% UN 8347 AV 93 ILA Full SIZE 135 KB Average (510 ms AVL) DEC 2024 225 PUB 95% UN 9072 AV 103 ILA Full SIZE 131 KB Average (229 ms AVL)2041200 VOL. DEC 2024 (1524453 VOL. NOV 2024) VS 29,475 MB (26,793 MB Peso a NOV 2024) Full Size
DEC 2024 243 PUB 97% UN 12548 AV 62 ILA 102 KB Full Size Average (884 ms AVL)
3049164 VOL DEC 2024 (3309417 VOL.NOV 2024) VS 24,786 MB Full Size









































 Le descrizioni sistemate sono importanti,perche' la prima pubblicazione in Skipped,unita ai codici Canonical è davvero molto curiosa:)
Le descrizioni sistemate sono importanti,perche' la prima pubblicazione in Skipped,unita ai codici Canonical è davvero molto curiosa:) La prima curiosita è questa e occorre ricordare che è sempre nel codice Canonical,pero' sistemato in Skipped e sono le Policies Guidelines del dominio e sono valide per tutti gli spazi di Wikimedia:lo Style Guide sistemato su Wiki (oltre a Wiktionary è presente in tutti gli altri spazi) è "un Inno al Nonsense",perche' Wiki non ha nessuna referenza,rispetto a Dati Veri,ma è esattamente l'Opposto:)
La prima curiosita è questa e occorre ricordare che è sempre nel codice Canonical,pero' sistemato in Skipped e sono le Policies Guidelines del dominio e sono valide per tutti gli spazi di Wikimedia:lo Style Guide sistemato su Wiki (oltre a Wiktionary è presente in tutti gli altri spazi) è "un Inno al Nonsense",perche' Wiki non ha nessuna referenza,rispetto a Dati Veri,ma è esattamente l'Opposto:)