Syndicated Content Lost Brain è il nome scelto per questo FGL JULY 2025 e il motivo è gia' scritto nei dati generali del report e cioe' il riferimento del Syndicated Content è la ONE Position,ed è solo un elemento del Din Fantasy Calculator:)Questa è la definizione ufficiale dell'Holy Grail TFD Google,rispetto al Syndacated Content,ed è solo uno dei tanti elementi "denominati anche strategie" uniti alle ottimizzazioni:)E' una delle posizioni piu' Divertenti da unire agli Ottimizzatori stessi e occorre ricordare che sono anche all'interno degli operatori SEV e ufficialmente hanno ancora la denominazione SEO,pero' in realta' sono dei ricercatori per arrivare alle Gravi Violazioni,cioe' SEV:) (Search Egregious Violation è la loro vera ragione sociale e operativa insieme:) Questo è l'esempio piu' spudorato delle ottimizzazioni unite al Syndicated Content e poteva solo arrivare da Linkgraph,lo "specialista del link building" e cioe dell'Unnatural Links:) Dopo le Solemn Quotes;gli Account Generali;le Ripetute Violazioni (in realta ne sono solo DUE possibili:);la mancata compliance con le Strutture e la Relationship,sono arrivate anche le Ottimizzazioni nel Top delle Violazioni e sono esclusivamente i Duplicati,senza nessuna necessita di attivare anche l'Elsewhere (Subdomain e Pluri Account) e poi è arrivato anche l'elemento piu' IGNORATO dagli operatori SEV,ed è la Grandissima Furbizia dell'Holy Grail TFD Google:)I Furbi del Syndicated Content operano nella maniera indicata da Linkgraph e cioe' tanti domini,uniti a quello principale (Padroneggiare l'arte del link building è la definizione di Linkgraph:) ed è il senso operativo reale anche del Syndacated Content,pero' la Furbizia di Google è assai piu' elevata,ed ha sistemato la LOGICA dei Dati Veri,ed è formata dai Duplicati,per tutte le Ottimizzazioni o meglio Presunte Tali,Syndicated Content compreso:)Il problema sono sempre i Duplicate Content e per questo motivo anche i Syndicated ne fanno parte e rappresentano una festa per le tantissime Sister Site di questo dominio,perche' ogni spazio è autonomo e non puo essere unito ai Syndicated,perche'occorre possedere anche un codice Canonical per avere tutte le unioni e non è possibile sistemarli Motu Proprio,ad iniziare dalla conoscenza dei Duplicati Effettivi:)Questa è la posizione piu' simpatica da unire ai Syndicated Content e naturalmente la simpatia dipende dai Point of View:)Per gli operatori SEV è una posizione "decisamente antipatica",perche' sono sistemati i Duplicate Content effettivi e non sono quelli dei singoli domini,ma è il contesto online generale a determinare i Veri Duplicati e quindi figurarsi cosa significa aggiungere anche l'Elsewhere dei Subdomain oppure i Syndicated e cioe' centinaia di domini o Pluri account,avendo il collegamento con lo spazio principale:)E' la Gloria per le tantissime Sister Site di questo dominio,perche' nessuna di esse è un Subdomain e non partecipano a nessun Syndicated e per essere tale,significa che almeno il dominio principale dovrebbe avere tutti codici Canonical e potrebbero anche esistere,pero' è difficilissimo che avvenga,sopratutto quando esistono centinaia di domini collegati:)In questa pubblicazione avevo in mente di sistemare proprio le Sister Site,pero' la Fantasia Infinita del Supreme Case Creator "ha deciso diversamente" e naturalmente "ho scelto di seguirlo",perche' è l'operatore in assoluto a Piu' Alto Divertimento Aggiunto e tra un po' si comprendera' quanto è VERA l'Affermazione:)Indirettamente il Divertimento per il Syndicated Content è gia' in questa posizione,oltre a quella sistemata sopra e non è "un contesto qualunquista" ma è la Fundamental di tutte le Ricerche:)Per tutti i Duplicati,compresi quelli di tutte le Ottimizzazioni e quindi anche dei Syndicated, la verifica è generale in senso effettivo,ed è formata dalla comparazione con tutti i contenuti del web e il report finale ,forma i codici Canonical,oppure gli Alternate e le posizioni vengono verificate "nel NEXT STAGE" e cioe' "nell'ipotetica verifica successiva",naturalmente sperando che ESISTA e se fossero i Syndicated Content,è molto difficile che possa esistere un NEXT STAGE:) Se fossero solo le "presunte ottimizzazioni" dei Syndicated Content ,questa è la Divertente Raccomandazione:)E' possibile anche fare "la richiesta di revisione" per la penalita' del Syndicated Content,pero' non debbono esistere altre violazioni precedenti (DUE:) e naturalmente il riferimento è a tutte le Ottimizzazioni e sono le brillanti idee dei SEV e quindi le violazioni sono proprio garantite e quasi sempre "superano agevolmente" le Ripetute Violazioni (DUE:) e a questa posizione occorre anche Arrivarci,perche' non è possibile unire "le richieste di revisione" alla presenza di Duplicati e ancora meno se dovessero esistere anche gli Elsewhere abilitati e cioe' i Subdomain:)
Per gli operatori che avessero in mente di chiedere la revisione,rispetto a qualsiasi forma di ottimizzazione,Syndicated Content compresi,esistono anche le posizioni sopra e sono entrambi molto Divertenti,perche' esiste la sicurezza di superare ampliamente le Ripetute Violazioni e Addio No Longer Violation:)La guida alle AI generated è semplicissima,ed è sufficente Togliere le Primarie Purpose,ed è in pratica il motivo reale per cui vengono pagate le generative content e a questa posizione occorre anche Arrivarci,per tutte le ottimizzazioni,Syndicated Content Compresi:)
Sempre per le Ottimizzazioni ,dopo un discreto percorso,iniziando dai Duplicati,è presente anche il Search Quality User Report:)
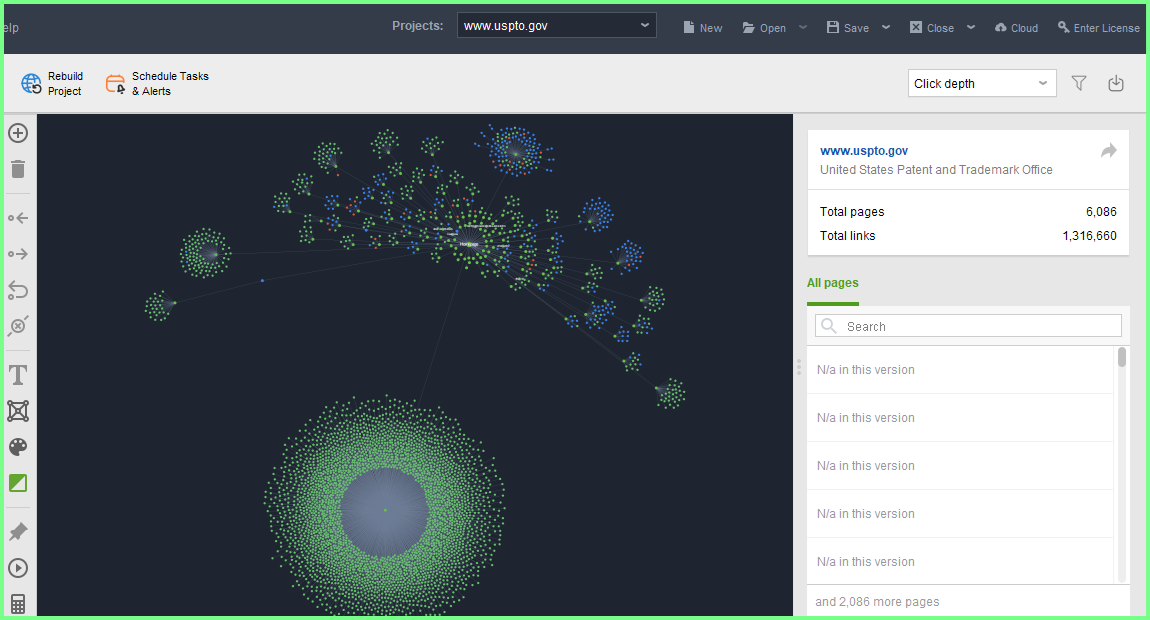
E' stato sistemato tante volte,pero' la sua presenza "si Rinnova Sempre" grazie all'URL della Data e alla presenza dell'Account Generale e per i dati che seguiranno,il contesto si trasforma nella Verifica Parallela,perche' è l'unica posizione che ha dati maggiori,rispetto a quelli che FGL JULY 2025,tranne l'attuale Origin RF ONE e la precedente FGL JUN 2025:) Restando nell'ambito delle Ottimizzazioni e delle sue Violazioni,il Search Quality User Report,rende palese la difficolta di essere nel No Longer Violation,sopratutto utilizzando il Syndicated Content:)
Questo è solo l'inizio del Search Quality User Report,ed è molto Divertente da unire ai Syndicated Content e anche alle "richieste di revisione":) E' piu' Credibile "un dozzinale oroscopo",rispetto alla possibilita' che un operatore conosca i Dati del Keywords Stuffing,solo per citare un elemento presente nel Search Quality User Report,utilizzandolo come esempio:)
Nel contesto online esistono tantissimi Tools dedicati al Keywords Stuffing,pero' non ne esiste materialmente proprio NESSUNO che conosca i Dati Veri:)
Sono quelli delle Quality Guidelines e sono definite "difficili da testare" solo per eufemismo,perche' in realta i Tools dedicati al Keywords Stuffing non conoscono assolutamente nessun dato e al massimo forniscono il report di 1 sola pubblicazione,senza conoscere nemmeno quali sono i Dati Veri e cioe' viene applicato il Keywords Stuffing alla pubblicazione integrale,immaginando che i Match non esistano:)
Dopo tanta esperienza,non ricordo nessuna pubblicazione che sia stata mai integrale,perche' è oggettivamente impossibile non avere Match e l'unica opzione è di averne il minor numero possibile e il contesto va applicato all'intero dominio e cioe' sono le Proposte Complessive a formare il Keywords Stuffing Reale e gli operatori con i loro Tools,non conoscono assolutamente nulla (al massimo 1 pubblicazione,senza conoscere nemmeno i termini immuni che esistono e tra l'altro sono molto variabili pure,ad ogni Match:) e quindi chi dovesse fare la "richiesta di revisione" è meglio che si Affidi alla Logica,perche' non puo oggettivamente sperare che sia in NO LONGER VIOLATION e utilizzando la strategia delle ottimizzazioni,unita al Syndicated Content,la LOGICA ha un unico suggerimento,ed è quello di non fare nessuna richiesta di revisione perche' le Violazioni sono implicite nella strategia stessa e cioe' tutto Unnatural Links:)
Il Search Quality User Report,unito anche alla Violazione delle Ottimizzazioni e quindi anche alla strategia del Syndicated Content,ha tante posizioni al suo interno e quella sistemata sopra è la sua sezione finale,ed esprime la LOGICA opposta al NO LONGER Violation,semplicemente perche' quelle descritte sopra sono le operazioni effettive che fanno anche gli operatori del Syndicated Content (Linkgraph suo malgrado ha detto la Verita:) e quindi è inutile fare la richiesta di revisione,quando si fanno queste operazioni e il contesto piu' Divertente da unire al Syndicated Content,è quello sotto,perche' esiste anche il principale elemento da unire al Divertimento,ed è il denaro speso per la cazzata del Syndicated Content e per tutte le ottimizzazioni in generale,perche' gli operatori SEV arrivano SEMPRE DOPO la creazione dei contenuti e visti quelli che hanno loro,i poveri utenti che si affidano "alle loro cure",non hanno nessuna speranza di avere Content Migliori,ma è esattamente il contrario:) Se dovessero avere Content Validi,applicando le strategie dei SEV,Syndicated Content compreso,esistono notevoli probabilita' di eliminare anche loro:)
La posizione finale dell'ultima sezione del Search Quality User Report per la Violazione delle Ottimizzazioni è davvero la piu' bella,perche' dopo tutte le posizioni negative descritte,solo nel Search Quality User Report (occorre ricordare che è solo una sezione delle Violazioni unite alle Ottimizzazioni:) esiste anche l'Abuso OR Strategie Sfruttatrici degli Ottimizzaztori stessi ,NON MENZIONATE SOPRA e le menzioni ne sono talmente tante,da rendere il contesto,il miglior elemento da unire al Divertimento e all'immagine sotto:)
Quella dell'Holy Grail TFD Google Merchant è di sicuro la posizione piu' Divertente da unire alle Violazioni del Syndicated Content e lo sono proprio in maniera Implicita,grazie alla strategia Demente Stessa:)La definizione di Inappropriate Content è unita alle Landing Pages e quindi a tutti i Prodotti;alle Ads e a qualsiasi altro servizio e il Divertimento unito alla violazione specifica,deriva dal fatto che i Syndicated Content sono utilizzati dagli operatori "che se lo possono permettere",perche' significa gestire centinaia di domini e occorre pagare anche "gli operatori SEV" che seguono "la brillante strategia" e quindi il Divertimento è proprio assicurato,perche' attraverso il Syndicated Content i costi sono elevati e altrettanto elevata è la probabilita' di essere in piena violazione,ad iniziare dai Duplicati uniti anche alle Ottimizzazioni e se per miracolo (non esistono altre possibilita:) fosse possibile uscire immuni dai Duplicati ,sempre i simpatici operatori dei Syndicated Content ,per continuare a "farsi del male" hanno aggiunto anche gli Unnatural Links,collegando centinaia di spazi a 1 dominio principale,utilizzando sempre gli stessi contenuti:)
Naturalmente la sistemazione di queste posizioni non è Casuale,ma è unita alla Fantasia Infinita della Casualita' stessa e inizia dalle posizioni opposte al Syndicated Content e sono quelle del Department Logical Data e saranno loro a festeggiare FGL JULY 2025:)
Il senso delle posizioni sistemate è unito proprio al Department Logical Data,in maniera oggettiva e inizia dall'immagine sotto:)
https://keywordtdarchive.blogspot.com/2018/05/over-optimization-key-archive.html
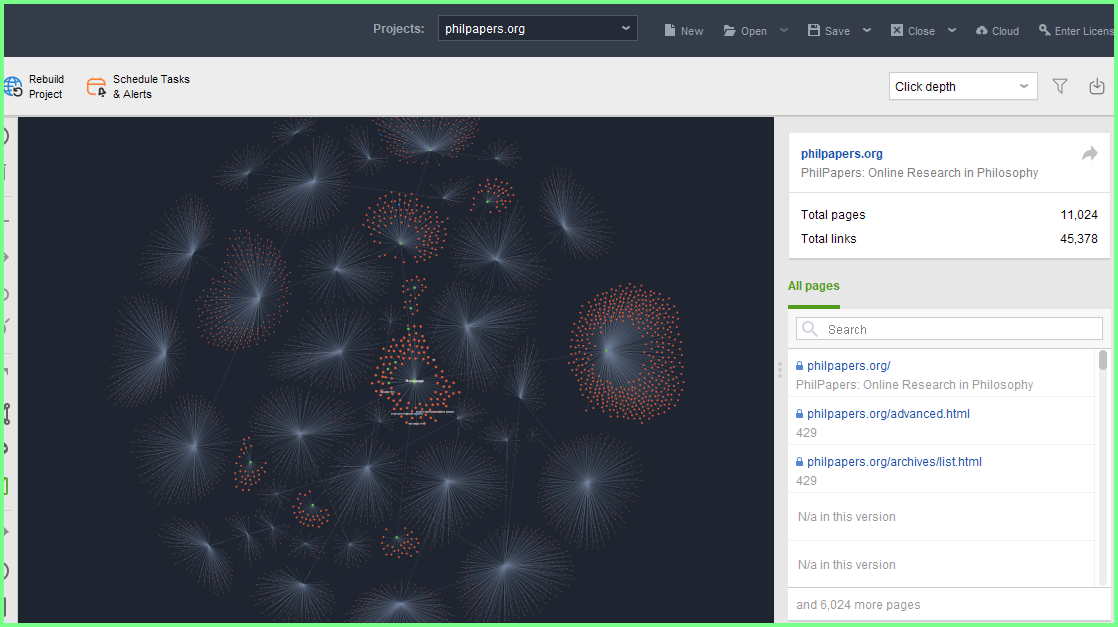
L'unione al Department Logical Data ha la certificazione piu' importante:Key TD Archive è una Sister Site e la sua pubblicazione è proprio dedicata alle Over Ottimizzazioni,arrivate anch'esse al Top delle Violazioni,grazie ai Duplicate:)
Solo la presenza dell'Account Generale,certifica che non esiste nessun Syndacated Content con la Sister Site specifica e anche con tutte le altre e in questa posizione,occorre ricordare la data della pubblicazione,ed è MAY 2018,ed è molto importante per i contenuti che seguiranno:)
Ho risistemato l'immagine perche' l'Over Using delle Ottimizzazioni in questa posizione "avra' un doveroso Developer" ed è unito alla Top Violazione dei Duplicati,senza la necessita di unire l'Elsewhere e nemmeno i Syndicated Content:)Naturalmente da MAY 2018 sono stati tanti gli sviluppi,rispetto alla Over Ottimizzazione e in questa posizione è possibile citarne UNO,grazie al fatto che solo alcuni mesi dopo le Over Ottimizzazioni è nato il Frame Global Limit ,attraverso le verifiche interne dei domini e la differenza rispetto ai dati sistemati a MAY 2018 è colossale,perche' l'Abuso delle Ottimizzazioni ,possiede in realta' 1 sola pubblicazione attraverso Content Integrali,ed è una cosa piu' vicina alla Science Fiction rispetto alla realta',perche' mai è avvenuto che esistesse:)Per aggiornare il ruolo delle Ottimizzazioni,Syndicated Content compreso,ho scelto la posizione sopra e tutti i domini che hanno partecipato a FGL JULY 2025 la possiedono.
L'evidenza di colore blu indica il volume complessivo della selezione,mentre il colore rosso indica il volume eliminato e il colore verde "indica l'aggiornamento delle Ottimizzazioni" e cioe' il volume rimasto Immune dai conflitti,ed è lui a dover sostenere l'impatto degli Internal e External Links e solo i termini effettivi presenti possono farlo.https://keywordtdarchive.blogspot.com/2018/05/over-optimization-key-archive.html
Per rendere operativi e pertinenti gli aggiornamenti dell'Over Using delle Ottimizzazioni,è molto utile ricordare i suoi contenuti originali,ed era MAY 2018:)Ho sistemato delle evidenze interne,perche' i periodi ne sono tanti,ed è anche normale grazie al fatto che la pubblicazione ha oltre 6000 termini effettivi:inizia da un affermazione fantastica (era MAY 2018:) e cioe' "l'utilizzo esagerato delle ottimizzazioni" non garantisce nessun Ranking,ma solo l'impegno e cioe' Tanto Effort,è capace di farlo e per comprendere cosa significa attualmente,è sufficente vedere anche i contenuti attuali "dei principali ottimizzatori",ed è molto difficile la ricerca dell'EFFORT,anche nell'anno 2025:) (sono in realta' tutti SEV e l'unico impegno effettivo è quello di arrivare alle Gravi Violazioni)E' fantastico anche il periodo successivo e a MAY 2018 ho scritto che non esiste nessuna alternativa all'IMPEGNO nella creazione dei contenuti e le "scorciatoie delle ottimizzazioni facili" appartengono solo al Run by Idiots:)L'aspetto straordinario è proprio la data della pubblicazione,grazie al fatto che i contenuti originali sono nati in questo dominio,ed era APR 2018 e la posizione di Key TD Archive serviva per avere dei collegamenti,rispetto alle pubblicazioni successive dedicate alle Ottimizzazioni.Il contesto straordinario della data è molto semplice,perche' nello stesso periodo è nato lo Spam Brain,ed è in pratica un evoluzione del Run by Idiots,ad iniziare dai termini stessi utilizzati,insieme alla loro applicazione,ed è proprio quella delle Ottimizzazioni:)Quando vengono citati i report dello Spam Brain,quasi sempre sono descritti i Links,dimenticando quali sono le penalita' maggiori presenti nello Spam Brain stesso e sono proprio i Duplicati,in larghissima maggioranza e attualmente hanno anche la prima posizione,rispetto a tutte le violazioni possibili:)Un altro periodo fantastico da citare è la Pertinenza dei contenuti rispetto alle possibili ottimizzazioni,sempre scritto a MAY 2018 e in quel periodo ho glorificato "La Monotematicita' dei Contenuti" e senza saperlo assolutamente,stavo descrivendo i Main Content e cioe' Il Core Pillars del Page Quality Rating e occorre ricordare che dall'Update delle General Guidelines di JAN 23 2025,sempre i Main Content sono anche nella prima posizione effettiva delle Spam e cioe' senza di LUI non esiste nessun DATO VERO,ed è facile comprendere quanto è elevata la differenza,rispetto a qualsiasi altro contenuto del contesto tradizionale:)
https://keywordtdarchive.blogspot.com/2018/05/over-optimization-key-archive.html
Questo è un altro periodo fantastico,all'interno delle Over Ottimizzazioni,ad iniziare sempre dalla data in cui sono stati scritti,ed è MAY 2018:)L'Overusing delle Ottimizzazioni unito "al tentativo d'ingannare i motori",rappresentano l'Attuale Circumventing System,ed è la peggiore delle Egregious Violation e attualmente è anche superata dalla LOGICA,perche' la prima Violazione unita alle Ottimizzazioni sono diventati i Duplicati e quindi gli operatori delle "presunte ottimizzazioni" (sono in pratica formate dalle brillanti idee dei SEV a cui è possibile aggiungere anche i Syndicated Content:) debbono aggiungere anche una notevole dose di presunzione alla loro attivita,perche' è oggettivamente gia' difficile uscire immuni dai Duplicati e poi aggiungere anche l'eventuale Elsewhere,insieme ai Syndicated Content,occorre davvero una notevole presunzione da parte degli operatori e da questa posizione derivano anche i periodi sotto,sempre scritti a MAY 2018,per l'Over Using delle Ottimizzazioni:)
L'insieme è nato da questa posizione,pero' solo in ordine temporale,ed è formata dalla pubblicazione piu' vicina all'Average che ha avuto l'intera selezione e occorre ricordare che è stata la prima ad aver avuto 244 pubblicazioni,ed è presente anche l'Average Century formato da 5009 termini effettivi:)Qui è sistemata la pagina completa
Solo la posizione è gia' una garanzia rispetto al volume che ha avuto FGL JULY 2025 ,perche' la pagina inizia dalla 91° posizione a scalare nelle dimensioni e arriva alla 120° e quindi è quasi alla meta' esatta dell'intera selezione e la pubblicazione che ha l'Average piu' vicino all'intera selezione,a sua vola è quasi alla meta' della pagina prelevata:)A questo punto occorre ricordare cosa contiene la pubblicazione specifica e sopratutto è indispensabile conoscere la data originale della pubblicazione stessa:)AUG 27 2019 è la data esatta:)https://dinpoststory.blogspot.com/2019/08/din-long-data-twin.html
La pubblicazione contiene questa posizione,ed era AUG 27 2019,dedicata alle Over Ottimizzazioni e alle Quotes e attualmente è cambiata solo la posizione delle violazioni:)Sempre ad AUG 27 2019 esisteva anche questa posizione,ed è proprio l'ideale da unire ai LOST LINKS che seguiranno,perche' le sue penalita' sono quelle sopra,oltre a tutte le Ottimizzazioni all'interno della prima violazione dei Duplicati:)Il contesto straordinario è sempre la data della pubblicazione,perche' solo alcuni giorno dopo (era SEP 10 2019:) è arrivata anche l'evoluzione dei Links in NOFOLLOW e quando ho scritto la pubblicazione nessuno conosceva il Developer che sarebbe arrivato:)Attualmente solo per i Links,ipotizzando che i Duplicati abbiano la percentuale minore possibile,la prima violazione sono i DISALLOW e quindi quando si fanno le operazioni dei LOST,quasi tutti uniti a Links in DOFOLLOW,l'unica possibilita' è quella di Pensarci Molto Bene Prima di utilizzarli,perche' non è possibile recuperare il contesto tramite i Disallow,perche' sono loro stessi una Grave Violazione e nel Caso dei Links è proprio la Prima:)
La posizione appena descritta è stato solo il primo motivo,da cui è nata questa pubblicazione e in realta' avrebbe avuto impostazioni diverse,se non fossero esistite le posizioni che seguiranno:)

Questa posizione è arrivata solo grazie alla Fantasia Infinita della Casualita':)
In questo Caso non esiste un ordine temporale,perche' la posizione sopra è arrivata dopo diverse ricerche,pero' è molto curiosa lo stesso,perche' è all'interno dei Discovery e cioe' è la prima volta che è stata prelevata la pubblicazione,ed è proprio quella delle Over Ottimizzazioni e il contesto piu' curioso rispetto ai contenuti che seguiranno,è la data stessa del Discovery ed è 24 Aprile 2025 e il report è arrivato a JUN 26 2025:) 
E' proprio la posizione da cui sono arrivati i Syndicated Content e per comprendere "quali sono stati gli esisti del report" ,è sufficente vedere la data dell'URL (28 JUN 2025) e la presenza dell'Account Generale,per avere il valore positivo del report:)Esistevano tante posizioni da sistemare e avevo scelto il report dell'Holy Grail TFD Search Console,per avere la Verifica Generale,rispetto ai dati di FGL JULY 2025 e sono particolari loro stessi,perche' non sono mai state presenti 244 pubblicazioni in 1 sola selezione,avendo anche un Average superiore a 5000 termini e solo per ricordare la selezione piu' vicina nel numero di pubblicazioni,JULY 2020,esistevano 10 pubblicazioni in meno e contemporaneamente è elevata anche la differenza degli Average e quindi il report di FGL JULY 2025 è proprio unico in tutti i sensi e solo la presenza di FGL MAY 2025,non ha permesso che fosse LUI il nuovo Origin RF ONE:) https://dinpoststory.blogspot.com/2025/06/department-logical-union-true-data.html
Dalla pubblicazione del Department Logical Union True Data,ed è quella del Resfresh,esiste anche questa posizione,unita a JULY 2020 e significa che i codici di Search Console uniti alle Proprieta gia' esistevano https://dinpoststory.blogspot.com/2020/09/fgl-star-unique-content-sep-2020.html
Per avere la conferma,esiste anche SEP 2020,ed è l'altra selezione che ha avuto 234 pubblicazioni presenti e al suo interno è presente un collegamento per Search Console dell'anno 2015 e significa che i codici gia esistevano e non possono essere modificati o rimossi e l'importanza di queste posizioni è molto semplice:L'importanza delle posizioni dell'Holy Grail TFD Search Console e fantastico coetaneo è quella sopra,ed è il NO LONGER delle Violation e per averle è indispensabile anche Arrivarci ,iniziando sempre dai Duplicati,per tutte le Ottimizzazioni,Syndicated Content compresi e occorre ricordare che le Violazioni Ripetute,sono esse stesse unite sempre ai Duplicate,ed è solo l'inizio del percorso e quindi è facile comprendere quanto sia importante la presenza dell'Holy Grail TFD Search Console e per questo motivo l'avevo scelta come Verifica Generale per i dati di FGL JULY 2025 e poi le combinazioni del report arrivato a JUN 26 2025 sono state talmente straordinarie,da rendere necessaria questa pubblicazione:)https://dinpoststory.blogspot.com/2023/08/din-colors-five-solemn-core-pilars-data.html
Per comprendere la differenza,rispetto alle posizioni sistemate (l'Over Ottimizzazioni al Discover da MAY 2018,mentre esiste il Refresh per la pubblicazione precedente:) esiste il contesto sopra,ed è unito alle Sitemap,pero' è valido anche per chi non dovesse averla:)
Qualsiasi ChangeFreq e priorita sistemata nelle Pubblicazioni,rispetto a qualsiasi dominio,è completamente IGNORATA e cioe' gli autori,insieme ai loro eventuali ottimizzatori,non Decidono quali sono le Frequenze delle Visite e non possono Decidere nemmeno quale pubblicazione possa avere la Priorita e cioe' se un autore sistema un codice Canonical in proprio e ne esistono tanti,sopratutto nei presuntuosi domini Wikimedia,il contesto è completamente IGNORATO,mentre NON è IGNORATA la presenza del LastMod e significa semplicemente la data della pubblicazione originale e per essere valida,debbono esistere gli stessi contenuti trovati la prima volta (è il Discover:) compresi i Links presenti e sono validi esclusivamente gli Anchor Text uniti ai termini effettivi,tranne naturalmente quelli in Duplicato e queste posizioni sono valide,fino all'arrivo dei Thin Content e se fosse presente,è l'intera pubblicazione ad essere eliminata e ovviamente,non potra essere nei Refresh:)Questi sono i motivi per cui è possibile avere il Discover dall'anno 2018,insieme al Refresh della pubblicazione precedente,nello stesso report,ed è gia una condizione difficilissima che possa accadere,sopratutto quando esistono dimensioni colossali rispetto ai contenuti oggettivi stessi e non ha nessuna importanza il fatto che i domini siano separati e ognuno ha una Proprieta (i codici di Key TD Archive e Key Stuffing Archive,insieme a tutte le altre Sister Site,hanno Proprieta diverse rispetto a questo dominio),perche' esiste sempre l'Account Generale a poter creare problemi sia per questo spazio e anche per tutte le Sister Site e il primo Grande Problema sono i Duplicati stessi e quindi prima di sistemare altri contenuti,è indispensabile ricordare a cosa sono uniti i Possibili Problemi:) https://dinpoststory.blogspot.com/2025/06/department-logical-union-true-data.html
Questo è un Possibile Problema,ed era sistemato a JULY 2020,ed è presente anche nella pubblicazione che ha avuto il piu' Veloce Refresh di sempre,almeno per questo dominio e visto il contesto operativo dei contenuti stessi (è nel peso sistemato sopra:) è molto probabile che sia il Refresh piu' veloce in assoluto:)L'importanza di questa posizione è molto semplice,perche' nel report dell'Holy Grail TFD Search Console,esistono un numero di pubblicazioni assai maggiori,rispetto alla selezione e la migliore evidenza è nel SIZE sistemato sopra,grazie al fatto che è arrivato alla meta' esatta,rispetto alla vita di questo dominio:)Questo è il SIZE piu' recente in file XML e cioe' compresso e la data è JUN 1 2025 e attualmente è anche aumentato e i 50 MB in file XML sono molto vicini e nei dati non sono comprese immagini;video e nessun altro codice semplicemente perche' non sono proprio abilitati e non sono comprese nemmeno le posizioni strutturali.Questa è la posizione che rende semplici i SIZE e quindi diventera' molto facile comprendere anche il valore del file XML di JULY 2020:)https://dinpoststory.blogspot.com/2025/04/crown-colors-fgl-may-2025.html
Grazie al Crown Colors di MAY 2025 si ha il SIZE sistemato sopra e contiene tutti gli elementi strutturali del dominio presenti in qualsiasi pubblicazione,comprese le pagine interne,ed è formato da 238,9 KB:)Dalle posizioni descritte deriva il SIZE di tutta la selezione di FGL JULY 2025 e l'unione con il report di Search Console è molto semplice,perche' nelle selezioni di FGL JULY 2025,prevalentemente esistono pubblicazioni presenti proprio nel File XML di JULY 2020 e cioe' la maggioranza delle pubblicazioni selezionate appartengono al periodo temporale precedente a JULY 2020 e non potrebbe essere in altro modo,perche' solo l'anno 2018 ha 55 pubblicazioni all'interno della selezione di FGL JULY 2025:)
Il senso è molto semplice,perche' le selezioni nelle verifiche interne dei domini sono tantissime e FGL JULY 2025 ha il record assoluto nel numero delle presenze (244:),pero' rispetto all'Holy Grail TFD Search Console sono "una piccola frazione" e i dati maggiori arrivano proprio dall'arco temporale precedente a JULY 2020,semplicemente perche' le possibilita di selezione sono anche maggiori,rispetto ai 5 anni successivi e oltre l'80% delle selezioni hanno anche il Refresh,compresa la pubblicazione precedente:)Il Refresh e cioe' la Fundamental Search è avvenuta attraverso questi dati e significa che sono stati visti prima i Duplicati interi e poi quelli Globali e solo al termine si hanno i Dati Veri e esclusivamente LORO,possono almeno in TEORIA, essere uniti a eventuali ottimizzazioni e quindi figurarsi cosa significa applicare anche i Syndicated Content a questo contesto:)I Syndicated Content,all'interno delle ottimizzazioni sono unite ai Duplicati e significa operare in centinaia di domini,ed avere pure tanti collegamenti tra di essi,in maniera del Tutto Irresponsabile,perche' è sufficente solo la LOGICA a non permettere queste unioni:) I collegamenti possono esistere attraverso Content Validi reciproci e la posizione è molto Instabile,perche' puo variare ad ogni Match,mentre i collegamenti restano FISSI e non è possibile applicare nessun LOST e cioe' Eliminare i Links stessi e da questa posizione deriva il Syndicated Content Lost Brain,perche coloro che fanno queste operazioni hanno Perso proprio il loro Brain,oltre ai links,semplicemente perche le operazioni sono separate del tutto dalla Logica dei Dati Veri:)Esiste anche il paradosso "della LOGICA Parallela" da unire agli operatori SEV (visto il contesto le operazioni delle presunte ottimizzazioni hanno come unico e vero scopo quello di arrivare alla ricerca delle gravi violazioni:) perche' possono benissimo creare "un contesto online parallelo",grazie al fatto che non esiste nessun limite fisico e hanno anche tanto denaro a disposizione e il motivo per cui non lo fanno,è molto semplice,perche' la VERA POSIZIONE DOMINANTE non è quella delle Ricerche e degli Engines,ma è la LOGICA dei DATI VERI,ad essere Realmente Dominante e quindi l'augurio è che gli operatori SEV,pensino realmente di creare un "contesto online parallelo",attraverso tutte le loro cazzate,perche' il Divertimento è garantito lo stesso e l'unica scommessa,per gli oppositori alla LOGICA dei Dati Veri,sara' il tempo necessario per arrivare al fallimento totale,ed è facile prevedere che dovranno essere utilizzati nanosecondi,per rendere valida la scommessa,rispetto al fallimento totale:) https://dinpoststory.blogspot.com/2025/05/demonstrate-juice-effort-data-archive.html
Proprio a FGL MAY 2025 esiste il precedente report dell'Holy Grail TFD Search Console,ed è sufficente solo vedere "il SIZE galattico" unito alla presenza dell'Account,per comprendere quante presenze possono esistere e poi ogni Engines puo decidere di sistemare i codici Canonical dove vuole,pero' i contenuti al 90% sono nati in questo dominio,ed è oggettivamente molto difficile farne un altro uguale,contemporaneamente:)Occorre aggiungere un altro particolare importante rispetto alla presenza del SIZE da 52 MB,ed è valido per qualsiasi altro dato fosse presente e e cioe' i calcoli dei Pesi sono realizzati solo dalle Novita Trovate nel dominio e quindi nei 52 MB dei SIZE non sono compresi i Pesi Noti Precedenti e possono essere solo quelli dei Refresh,ipotizzando che i contenuti esistano ancora:)Dopo tutte le posizioni descritte,questo è il report arrivato a JUN 26 2025 e il SIZE è molto vicino a quello di MAY 2 2025 e non sono presenti i Pesi gia' Noti e ad esempio potrebbe essere il Refresh della pubblicazione precedente:)Fino a questo punto,pensavo di utilizzare il report di Search Console come verifica generale,rispetto ai dati che ha avuto FGL JULY 2025 e poi è arrivato il suo Average delle dimensioni e grazie ai contenuti della pubblicazione coinvolta (esistevano le Over Ottimizzazioni insieme alle penalita dei Dofollow e tutto questo sistemato ad AUG 2019 e cioe' poco prima dell'evoluzione dei Links in NOFOLLOW,senza conoscere NULLA,utilizzando solo la LOGICA :) è iniziata l'idea di cambiare i contenuti che pensavo di scrivere in questa pubblicazione,perche' dopo aver visto i contenuti di AUG 2019,la prima idea è stata quella di verificare il contesto attuale delle Ottimizzazioni e dei Links in generale,ed è arrivata la posizione sistemata sopra e cioe' attualmente,la prima violazione rispetto a qualsiasi Ottimizzazione,sono i Duplicati e se i dati fossero positivi,esiste anche la prima violazione dei Links e sono i Disallow e ovviamente sono applicati a tutti Links in Dofollow:)Ci saranno tante posizioni e ho scelto di sistemarle tutte,perche' ognuna è importante rispetto ai Dati del Report e inizia dal Setting e dalle Associations,insieme alla verifica dell'autore e l'importanza è molto semplice,perche' è proprio questa posizione ad essere l'Inizio del No Longer Violation,grazie al fatto che la verifica della Proprieta è possibile farla SOLO UNA VOLTA e i codici sistemati non possono essere rimossi o modificati (sarebbe una pessima idea:) ed esistono dall'anno 2015 e occorre ricordare che è anche l'anno in cui è nata Search Console stessa:)
Questa posizione ricorda che la verifica ha avuto successo e non è un contesto banale,perche' davanti a 52 MB precedenti e 51,7 MB attuali,è indispensabile ricordare anche queste posizioni,ed hanno gia' la Verifica Diretta,grazie alla data dell'URL e alla presenza dell'Account Generale e con oltre 50 MB nei SIZE,uniti anche alla categoria di questi contenuti,è molto difficile che accada:)Anche questa posizione non è affatto banale e tantomeno è scontata la sua presenza (se fossero i domini del Syndicated Content o della Relationship,sono elevatissime le probabilita di avere posizioni opposte rispetto a quelle sistemate:)Non esiste nessuna Associations rispetto al dominio specifico e potrebbero essere presenti anche le Sister Site non sistemate nelle Proprieta.https://dinpoststory.blogspot.com/2025/05/demonstrate-juice-effort-data-archive.html
Anche il Setting e le Associations hanno delle penalita' molto gravi e quindi la loro presenza non è affatto banale e tantomeno scontata,perche' nella prima posizione esiste il No Longer delle Violazioni per il Setting stesso a cui segue i Blocchi dei robots txt e occorre ricordare che il NO LONGER significano DUE Violazioni,rispetto a tutte le Policies e quindi figurarsi cosa significa avere i Syndicated Content insieme a tutte le altre ottimizzazioni,applicate solo dopo aver superato i Duplicati e la posizione non è affatto definitiva,perche' lo stesso contesto si ripete a ogni Refresh e nelle No Longer Violation,la posizione dei Duplicati non solo è la prima,ma deriva dal contesto online generale e cioe' è il Taken Against Content Generally e cioe' la Fundamental Search sistemata sopra e nelle stesse No Longer Violation sono compresi i Mismatch (se modificano i Links attraverso i Lost,è molto probabile che gli autori cambino anche i contenuti:) insieme ai Multi Fact Check e la posizione è LOGICA,perche' non possono esistere Dati Veri insieme a Fatti Falsi e per gli operatori SEV,il FALSO è l'unica opzione che hanno,perche' sono FALSE anche le loro impostazioni:) Non è assolutamente credibile nemmeno l'idiozia degli operatori stessi e quindi esiste solo una possibilita',unita alle loro operazioni e deriva dal fatto vero che sono anche Ladri e l'affermazione è anche pertinente e ufficiale,perche' sono esattamente le Strategie Sfruttatrici sistemate sopra:)Altri particolari uniti al Setting e alle Associations sono nella pubblicazione di MAY 2025 sistemata sopra.
Questa è una sezione interessante del Setting,ed è presente il robots txt valido e per essere tale significa che non esiste nessuna limitazione,rispetto a qualsiasi pubblicazione e a queste condizioni,è piu' facile comprendere cosa significano oltre 50 MB nei SIZE:)Sono presenti anche le Richieste Generali,fatte nei precedenti 90 giorni a scalare da JUN 26 2025 e sono state 1520 le Richieste e sono loro a formare l'eventuale High Fail Rate,pero a questa posizione è indispensabile anche arrivarci,perche' nelle Richieste non sono comprese le pubblicazioni Eliminate dai Match o da qualsiasi altra violazione.
Queste sono le presenze delle Proprieta e ognuna ha dati autonomi e per essere tali significa che ogni proprieta è stata verificata e i codici sistemati non possono essere piu' modificati e tantomeno rimossi.La data del report è sempre JUN 26 2025 e fino a questa posizione,pensavo di sistemare "contenuti normali" rispetto a quelli descritti nella pubblicazione precedente e poi è stata proprio LEI a "modificare tutto",grazie al Refresh piu' Veloce della Storia e probabilmente lo è in maniera oggettiva,perche' se dovesse esistere una pubblicazione simile,per comprendere la Velocita del Refresh dovra avere esattamente le stesse condizioni:1 solo Content Creator;1 dominio da oltre 60 MB in file HTML;solo 10 anni di scritti effettivi e naturalmente dovra avere anche la stessa categoria dei contenuti e grazie a queste posizioni,Super Verificate dall'Holy Grail TFD e fantastico Coetaneo,Search Console,le probabilita' che esista la stessa Velocita del Refresh sono molto scarse,anche in qualsiasi futuro:)
Anche la Timeline del report è molto interessante,perche' rende semplice comprendere la complessita dei dati e di conseguenza rendono ridicoli tutti gli operatori delle ottimizzazioni,perche' in realta non conoscono assolutamente NULLA rispetto ai Dati (è tutta Millanteria,mista ad invidia per il Brain che Madre Natura ha donato loro:) e la Timeline sopra rende semplice comprendere il contesto appena descritto:)
La prima evidenza è dedicata al Tempo di Risposta piu' elevato dell'intera Timeline e ha coinvolto in realta 1 sola Richiesta,insieme al SIZE sistemato.Questa è un altra sezione fantastica delle Timeline,ed è evidenziato il maggior numero di Richieste,rispetto all'intero report ed ha un Average di Risposta assai minore rispetto alla Timeline precedente,formata da 1 sola Richiesta.Questa è la Timeline finale del report,naturalmente tra quelle selezionate e sono presenti 24 Richieste e tra di esse,esiste anche il Refresh della pubblicazione precedente e la Fantasia Infinita della Casualita' ha voluto che fosse proprio quella dedicata alle nuove impostazioni che avra Key Stuffing Archive,attraverso tutte le posizioni descritte al suo interno,ed è stata fatta proprio per descrivere il contesto che avra' Key Stuffing Archive:)
Questa è una sezione delle descrizioni fatte nella pubblicazione precedente,ed è quella del Refresh piu' veloce della storia e visto il suo contesto,probabilmente lo è veramente e in questa posizione è impossibile descrivere tutte le posizioni citate,tranne una,ed è l'immagine stessa di Key Stuffing Archive,perche' ha il collegamento proprio della pubblicazione precedente e quando l'ho scritta materialmente non immaginavo proprio che avesse tutte le combinazioni descritte insieme a quelle che seguiranno,compresi i tantissimi domini che hanno partecipato a FGL JULY 2025.Il collegamento della pubblicazione precedente,è nel banner dell'Avoid Concern Trust,mentre su Key Stuffing Archive,il collegamento è sistemato nel nome del dominio e la soluzione è servita per rendere semplici le selezioni:)
Naturalmente anche questa posizione è molto importante e serve a ricordare che nei precedenti 90 giorni o nell'ultima settimana,se ci fossero stati dei Problemi,vengono segnalati.E' possibile anche quantificare "i Possibili Problemi",ed è sufficente unire oltre 50 MB alla categoria specifica di questi contenuti e diventa facile avere dei Problemi,sopratutto quando l'arco temporale è formato da 90 giorni:)Questo è l'Host Status dei precedenti 90 giorni a scalare da JUN 26 2025 e ho sistemato questa posizione,perche' è presente anche l'URL con la data del prelievo e non poteva essere sistemato nell'immagine precedente perche' non è possibile avere l'Espansione con le descrizioni dell'Host Status insieme all'URL e alla data del prelievo:)Questo è l'Host Status specifico del report di JUN 26 2025 e sono le migliori posizioni da unire a oltre 50 MB nei prelievi,perche' è molto piu' facile avere problemi negli High Fail Rate:)Questo è un esempio pratico degli High Fail Rate anche per il report di JUN 26 2025,ed è sufficente solo vedere la Timeline,per avere anche la data esatta del report:)Non avere High Fail Rate nei Robots TXT,significa avere tutte le pubblicazioni disponibili,senza nessun limite e tra l'altro,è meglio che non esistano proprio,perche' coloro che attivano i robots txt,lo fanno perche' "desiderano anche utilizzarli" e non esiste dubbio che lo fanno e il miglior esempio sono i domini Wikimedia e solo per avere le loro assurde selezioni,mediamente occorrono 10 pubblicazioni in Disallow (sono fatte con robots txt) per avere 1 pubblicazione normale da sistemare nelle selezioni e il contesto è proprio negativo e quindi "la Vera Idea Brillante" è quella di non abilitare proprio i robots txt,perche' l'operazione finisce male di sicuro:)Questo è un esempio per arrivare agli High Fail Rate e quindi occorre pochissimo impegno per essere al loro interno e l'esempio sistemato sopra ha come arco temporale di riferimento solo 1 settimana:)Quindi i robots txt è meglio non abilitarli proprio e la posizione è comunque fantastica,perche' esistono anche i SIZE del Report e non avere nessun limite nelle selezioni,rispetto a oltre 50 MB,diventa un contesto straordinario,grazie anche all'unione della categoria di questi contenuti:)
Dopo le posizioni sistemate,proprio in ordine temporale rispetto alle selezioni fatte,è arrivata l'idea di questa pubblicazione.Il Refresh sono arrivati all'89% e questo sarebbe stato il dato da unire alla Verifica Generale,rispetto a quella di FGL JULY 2025 ,utilizzando solo la presenza dell'Account Generale,insieme alla data del prelievo e la Verifica Generale è gia fatta,perche' attraverso il volume del dominio unito alla percentuale dei Refresh,è sufficente solo l'Esistenza dell'Account Generale,per avere immediatamente anche la verifica:)Avendo gia questi dati,ho scelto di conoscere cosa contenessero gli altri elementi e il primo ad essere verificato è quello delle Page Resources Load,arrivato al 71% e cosa significa è nell'immagine sotto:)
Questi sono i dati specifici delle Page Resources Load e il suo 71%,rispetto sempre al report di JUN 26 2025 produce un SIZE da 37,8 MB e quindi è fondamentale conoscere cosa contiene:)
Esistono 2 evidenze,pero' quando ho aperto la pagina,la prima selezione è stato il primo FEED e al suo interno contiene 10 pubblicazioni e al primo impatto non ho visto le successive e questa posizione serve anche a ricordare i dati generali,perche' possono essere formati sia dai FEED e dalle pubblicazioni normali e se un operatore dovesse scorrere tutta la pagina,anche il primo FEED è classificato come 1 solo elemento,anche se possiede 10 pubblicazioni al suo interno:)
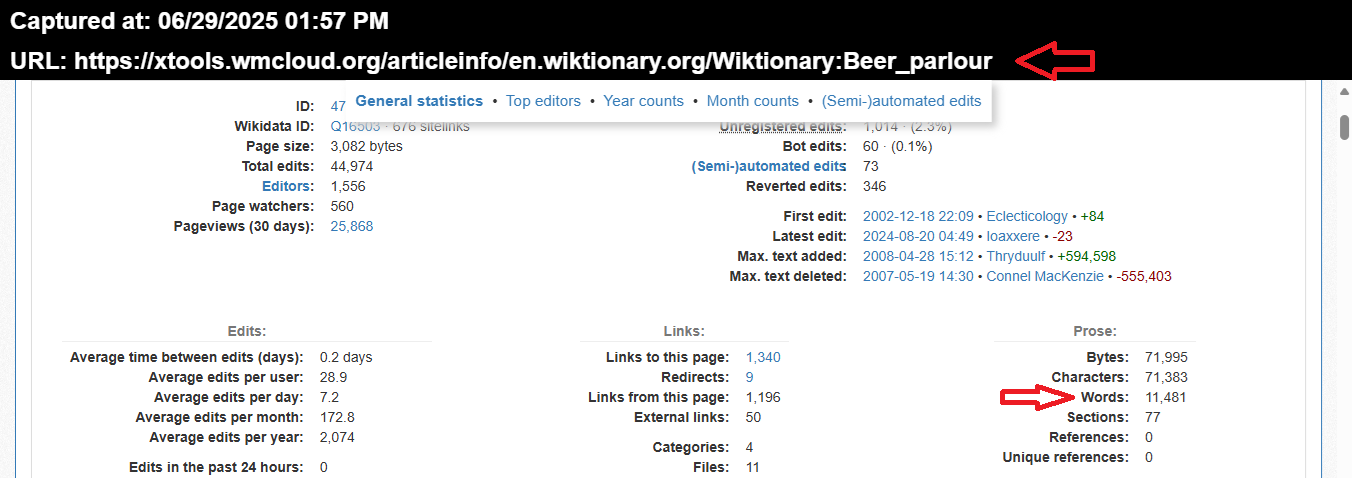
Ho aperto la pagina nel modo indicato sopra,per evidenziare anche l'espansione e ricorda che gli elementi presenti nel report non seguono le Richieste fatte,ma ne esiste UNA sola,anche contenendo 10 pubblicazioni.Fino a questo punto sapevo solo che il FEED era formato da pubblicazioni in Refresh e ne esistevano 10,pero' l'informazione è generalista e quindi fino all'apertura del FEED non conoscevo quali pubblicazioni fossero presenti e non immaginavo proprio di trovare i contenuti sotto:)
https://dinpoststory.blogspot.com//feeds/posts/summary?max-results=10&orderby=published&alt=json-in-script&callback=jQuery18006746087505016476_1750836037142&_=1749600000000
Questo è esattamente il Primo FEED trovato nel report di JUN 26 2025 e appena visto non è semplice trovare le pubblicazioni presenti e in questa posizione per rendere semplice la ricerca ho evidenziato i 2 ID sopra:)Sono proprio gli ID di questo dominio,insieme a quello del Department Logical Union True Data e cioe' la pubblicazione che ha il Refresh piu' veloce della storia e lo è realmente,perche' è molto difficile solo trovare un contesto simile a quello in cui è nata:)Qui è sistemata la prima pagina completa del Page Resource Load
In questo contesto speciale,l'avrei sistemata anche in maniera integrale,pero' ha dimensioni molto grandi e quindi esiste il collegamento sopra:)Esistono 682 reports solo per il Page Resource Load e il primo è il FEED sistemato sopra e tutta Page Resources Load arriva a 37,8 MB e rappresenta il 71% dell'intero report e poi esiste la curiosita' del primo FEED,perche' in realta possiede 10 pubblicazioni al suo interno e la prima pagina in cui è sistemato,a sua volta possiede 10 reports lei stessa:) (il totale è formato da 682 report e quindi esistono 69 pagine,solo per il Page Resource Load:)Per avere un idea del numero di pubblicazioni che contiene Page Resource Load all'interno del report di JUN 26 2025,esiste anche l'espansione delle opzioni e ho scelto il Time,pero' partendo dalle pubblicazioni piu' lontane nel tempo rispetto all'arco temporale della selezione (sono le selezioni fatte in 90 giorni a scalare da JUN 26 2025)Il risultato,applicando l'opzione Time,dalla prime pubblicazioni selezionate per il report di JUN 26 2025 è quello sopra e sono presenti altri 2 FEED e ognuno contiene 5 pubblicazioni e poi esistono anche le pubblicazioni singole e in questa posizione mi piace citare Crono + Traffico dell'anno 2015,ed è stata una delle prime pubblicazioni unite ai Post Base e in quel lontanissimo periodo (10 anni nel contesto online sono equivalenti a un arco temporale vicino all'Eternita:) li definivo "la chiave di lettura" rispetto a tutte le altre pubblicazioni e senza saperlo stavo descrivendo i Main Content:)Ho sistemato le posizioni esattamente come le ho prelevate e solo a questo punto è arrivato anche il Syndicated Content,insieme all'altra immagine sistemata sopra e rispetto al SIZE Generale,la sua posizione è relativamente piccola (è formata da 2,63 MB) pero' i suoi contenuti sono Pesantissimi e non esiste dubbio che siano anche Unici in Tutti i Sensi e il motivo inizia dalla posizione sotto:)
Questo è quello che contiene tutto il Syndicated nel report di JUN 26 2025 e cioe' sono tutti FEED e per comprendere la loro Unicita Generale,esiste l'immagine sotto,ed è possibile scommettere che è Unica al 100%:)E' un Syndicated Content in Refresh e non esiste nessun dubbio che sia una posizione Assolutamente Unica,grazie alle operazioni stesse del Syndicated descritte sopra,unite alle "presunte ottimizzazioni":)
Questo è quello che contiene il primo FEED e sono evidenziati gli ID e la pubblicazione è proprio quella precedente unita al Refresh piu' veloce e il contesto è straordinario,grazie forse all'unico Refresh,mai applicato ai Syndicated Content e naturalmente non ho dati esatti a riguardo,pero' la LOGICA unita alle Probabilita',suggerisce che il Refresh applicato ai Syndicated Content è oggettivamente UNICO:)Quindi la pubblicazione dedicata alle nuove impostazioni di Key Stuffing Archive,è nata dal contesto piu' straordinario possibile e il suo mcollegamento è nel Banner di Avoid Concern Trust:)
Sempre a JUN 26 2025 è arrivato anche il report di Key TD Archive e naturalmente i SIZE sono minori,pero' la sua posizione è importante lo stesso,sopratutto in questo contesto,perche' dalle posizioni dei SIZE deriva anche l'immagine sotto:)Qui è sistemata l'importanza dei SIZE,perche' nei Refresh i Pesi non sono calcolati,grazie al fatto che sono gia' NOTI,mentre esistono quelli dei Discovery e tra le pubblicazioni esiste proprio quella dedicata alle Ottimizzazioni nata a MAY 2018 e dopo quasi 7 anni ha avuto il suo Discover:)Sono sufficenti solo queste posizioni per alimentare il Divertimento nei confronti degli operatori alternativi ai Dati Veri perche' è la LOGICA l'unica posizione realmente Dominante e i report sistemati sono uniti ad essa,attraverso un contesto fantastico,perche' le descrizioni unite alla LOGICA,quasi sempre sono arrivati prima dei Developers e la pubblicazione dedicata alle ottimizzazioni di MAY 2018 è solo uno dei tanti esempi possibili:)
Nonostante i dati sistemati non esiste nessun Links e quindi solo i Content effettivi hanno fatto la differenza,compresa la pubblicazione piu' veloce dei Refresh:)La posizione è anche normale,perche' esclusivamente i Content sono capaci di creare Valore e in questo contesto la posizione sopra sara' molto utile rispetto agli altri domini che hanno partecipato a questo FGL JULY 2025,perche' spesso i dati sono esattamente opposti e cioe' i contenuti sono scarsi,pero' la presenza dei Links è elevata:)https://docs.google.com/spreadsheets/d/1qjFSd-ismxeNqEStX8MtRQpxUFz5xyn-X7ayx4VyRuo/edit?usp=sharing
Questo è Google Docs e sono presenti i Links del report:Esiste l'espansione degli Internal Links e indica tutte le operazioni tra i domini presenti nelle Proprieta e quindi sono anche tutti verificati e per essere presenti i loro dati significa che non esiste nessun Mismatch,compresi i termini utilizzati nei Links:)
Tra le Proprieta esiste anche AV su Google e quello sopra è il suo report sempre arrivato a JUN 26 2025 e potrebbe benissimo far parte degli Internal Links,perche' le sue dimensioni sono molto elevate e tante pubblicazioni sono ancora valide:)Sempre nel report di JUN 26 2025 i 34 MB di AV sono formati per il 58% da Refresh e quindi debbono esistere dei Content Validi per averlo e significano centinaia di Pubblicazioni e quindi i Links potrebbero essere presenti e la stessa posizione è valida per i Discover e cioe' i contenuti trovati la prima volta e al 42% sono risultati validi e per essere Tali,occorre prima superare i Duplicati e poi non aggiungere tutte le altre violazioni e solo a queste condizioni esiste il Discover e solo queste posizioni forniscono i Dati Veri e tutto il resto è Invalid Traffic al 100%:)
Anche l'Holy Grail TFD Microsoft partecipa ai Dati e la posizione sopra è arrivata a JUN 25 2026 e cioe' solo 1 giorno prima del report dell'Holy Grail TFD Google e il contesto è solo Casuale:)Nei precedenti 6 mesi rispetto alla data dell'URL,dall'anno 2015,esistono ancora 70 pubblicazioni Valide e 12 sono state eliminate,pero' sono state Escluse solo dai Match avuti nel corso del tempo:No URLS Applicable significa proprio questo e le posizioni sono all'interno dei filtri degli INDEX e formano gli URLS Applicable e la loro assenza significa solo che le pubblicazioni sono state escluse dai Match.La posizione piu' probabile,per le pubblicazioni eliminate dall'anno 2015 è questa,grazie al fatto che non esistono URLs Applicable e cioe' l'elenco di tutte le violazioni possibili e quindi solo i Match hanno eliminato le pubblicazioni e per arrivare a questa posizione,è sufficente avere dimensioni in Thin Content rispetto ai termini rimasti immuni dai Match.Comunque a JULY 2025,solo il fatto che esistono ancora 70 pubblicazioni dall'anno 2015,è Festa Totale:)
Dall'anno 2016 sono state eliminate 11 pubblicazioni,pero' ne restano 93 e anche questa posizione non ha URLs applicabili e cioe' nessuna violazione è stata commessa (è il Quality Checks dell'Holy Grail TFD Microsoft:) e le pubblicazioni eliminate lo sono state solo per i Match avuti nel corso degli anni,ed è sufficente solo arrivare alle dimensioni dei Thin Content per essere eliminati e significa avere dimensioni quasi doppie rispetto agli Average dei contenuti tradizionali,pieni zeppi di EDITS;senza Struttura Data;senza Fact Check ;e tante posizioni in cui sono sistemati i contenuti dei simpatici autori tradizionali e tutto questo,è realizzato quasi alla meta',rispetto alle dimensioni dei Thin Content:)
L'anno 2017 ha avuto 9 pubblicazioni eliminate,pero' restano Valide 57 pubblicazioni e anche in questa posizione,non esistono violazioni rispetto ai contenuti eliminati,tranne i Match avuti.Il report ha l'arco temporale formato da 6 mesi,rispetto alla data dell'URL (JUN 25 2025) e non significa che siano state selezionate tutte le pubblicazioni presenti e l'unica sicurezza è quella delle pubblicazioni eliminate e naturalmente non possono partecipare a nessuna selezione successiva.
Nel corso degli anni sono state tante le posizioni simili sistemate e ad esempio i dati sopra sono di arrivati a MAY 2022 e in quel Caso sono state 7 le pubblicazioni eliminate e ne sono rimaste 87
Questo è sempre l'anno 2022 ,ed esiste la posizione generale rispetto al report di allora ed ha avuto 31 pubblicazioni eliminate e nei filtri sono anche indicati gli Status Code,pero' nessun URLs tra le pubblicazioni eliminate è coinvolto e quindi anche nell'anno 2022 sono stati i Match a eliminare i contenuti.Questo era il report per l'anno 2017 arrivato nell'anno 2022 e sono state 5 le pubblicazioni eliminate pero' ne sono restate 78 e il riferimento temporale del report sono sempre i 6 mesi precedenti rispetto alla data dell'URL e le pubblicazioni eliminate e quelle rimaste immuni,sono solo quelle selezionate e quindi è possibile che ne esistano anche altre,perche' queste posizioni hanno tante pubblicazioni dedicate e se non esistessero le dimensioni di questo dominio,per il report dell'anno 2025,non esisterebbe nessuna pubblicazione presente:)Questo è l'incredibile anno 2016 per il report dell'anno 2022 e posizioni simili ne esistono tante nel corso degli anni e se non ci fossero state le pubblicazioni rimaste immuni sopra (101:) nel report di JUN 2025 non sarebbe arrivato proprio nessun dato:)
https://dinpoststory.blogspot.com/2022/05/just-time-google-patent-k3-may-2022.html
Altre descrizioni sono in questa pubblicazione ed è proprio dell'anno 2022 e al suo interno sono presenti anche i reports appena sistemati.
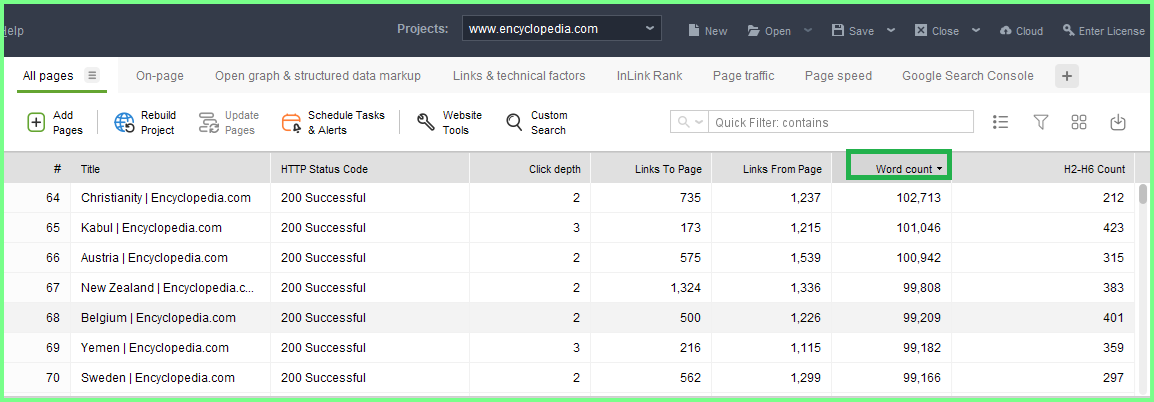
Questo è un altro esempio di reports simili,pero è dell'anno 2021,ed esiste anche la differenza nella selezione,perche' l'anno 2022 sistemato sopra ha l'arco temporale completo delle selezioni (cioe' 1 anno),mentre quello appena sistemato ha la divisione in mesi e nel Caso specifico è il mese di Giugno 2021 e sono presenti 41 pubblicazioni immuni (in quel periodo avevano gia 5 anni le pubblicazioni:) e non esiste nessuna pubblicazione eliminata.
Questo è il mese di Dicembre 2015 in un report dell'anno 2021,ed esistevano ancora 47 pubblicazioni e nessuna eliminata,in 1 solo mese:)Questo era solo il mese di Aprile 2015,sempre in report dell'anno 2021 e ne erano 53 le pubblicazioni presenti e anche questi dati hanno come arco temporale di riferimento sempre i 6 mesi precedenti alla data presente nell'URL e quindi è possibile che non tutte le pubblicazioni del mese di Aprile 2015 siano prelevate:)Questo è solo il mese di Marzo 2015 in un report dell'anno 2021,ed erano 46 le pubblicazioni,sempre con lo stesso arco temporale di riferimento (6 mesi) rispetto alla data presente nell'URL e grazie a JULY 2020 è possibile quantificare anche la presenza dei Match:)
Grazie a JULY 2020 è possibile quantificare anche il livello dei Match,rispetto alle pubblicazioni presenti nei reports dell'anno 2021 e saranno state circa 30 MB in file XML e occorre ricordare questa posizione,perche' rende molto piu' semplice comprendere i dati sistemati.In questa pubblicazione avevo in mente anche di sistemare alcune Sister Site e in maniera particolare pensavo a Key Stuffing Archive,pero' la pubblicazione ha gia dimensioni notevoli,ed esistono anche gli altri domini che hanno partecipato a FGL JULY 2025 e quindi le Sister Site saranno nelle prossime pubblicazioni.L'idea di sistemare le Sister Site è dovuta a un fatto semplice,ed è la composizione dei loro contenuti e in questa posizione è molto utile ricordarlo,perche' tutti i dati di questo dominio,non hanno nessuna risistemazione,anzi è esattamente l'opposto e non hanno nessun contenuto di altri autori (nemmeno 1 periodo e al massimo esistono solo delle immagini:) e tra di essi,il piu' elevato è quello delle Page Solemn,solo per avere le comparazioni dei dati:)https://dinamic1hc.blogspot.com/2018/07/bing-yahoo-string-3-comparazione.html
Questo è un altro fantastico esempio da ricordare e ho scelto proprio le String e cioe' sono le divisioni dei periodi applicati poi al Plagiarism:)Significano centinaia di pubblicazioni,unite a ogni RF dall'anno 2016 e le String e cioe' le divisioni dei periodi sono tutte su Key Stuffing Archive e quella sopra è molto particolare,perche' da lei è nata la prima Page Solemn nell'anno 2018 e i dati derivano dalla 3° Comparazione Generale,ed è stata scritta ad APR 2015,ed è presente nel report dell'anno 2021/2022,ed è anche attuale:)Questo Amarcord è utilissimo per comprendere da cosa derivano i dati,ed è sufficente solo immaginare di avere 53 pubblicazioni in 1 mese (APR 2015:) ,senza nessuna risistemazione;senza contenuti di altri autori,compresi gli eventuali commenti se fossero abilitati e senza tutte le String sistemate sopra (la posizione è solo un esempio perche ne esistono tantissime altre:) e avendo al suo interno anche la 3° Comparazione Generale:)Sono tutte le descrizioni fatte a formare i SIZE sistemati sopra e derivano solo dai Content Effettivi e nessun elemento strutturale ne fa' parte ,compresi i codici perche' non è abilitato nessun Tags:dal nome del dominio;dal nome delle pubblicazioni;dagli Headers;dagli Anchor Text e naturalmente non esistono Link Building;Relationship;Syndicated Content insieme a tutte le altre "presunte ottimizzazioni" e occorre ricordarle le posizioni,perche' quasi sempre sono proprio loro a far elevare i SIZE,rispetto ai Content effettivamente presenti:)
E' facile la verifica:è sufficente prendere il dato del Crown Colors di FGL MAY 2025 (non ha nulla al suo interno,ed esiste solo 1 immagine) e applicarlo a qualsiasi pubblicazione e si hanno i SIZE effettivi e per fare prima nelle verifiche è sufficente prendere le pubblicazioni vicine agli Average e grazie ai SIZE si hanno tutte le verifiche:)Questa è la posizione piu' bella da unire ai dati sistemati,perche' ha notevoli capacita di ricordare il contesto dei Dati Veri e non sono uniti solo ai Match interni ai domini,ma derivano dai Conflitti Globali e sono loro a determinare le posizioni appena sistemate:)Le Guidelines di Microsoft sono largamente compatibili con quelle di Google e le operazioni di verifica iniziano nello stesso modo,ed è quello della Fundamental Search e cioe' si verifica se esistono Duplicati in tutto il Web e poi arrivano le altre Violazioni e sono gli URLS Applicabili,sistemati nei reports dell'Holy Grail TFD Microsoft e da esso derivano tutti i dati anche degli altri "presunti Engines" e "presunte vittime del monopolio della ricerca":)Dopo aver verificato i contenuti,esistono le altre violazioni e il limite è 3 Strike,pero' gia' al primo le cose sono messe molto male e tra le possibili violazioni,esiste l'evidenza piu' Divertente rispetto ai domini che seguiranno,ed è quella del Disallow:)E' possibile scommettere "tutti gli atomi dell'universo" che i Disallow sono a loro volta uniti a posizioni in Dofollow e tra un po' saranno proprio loro i protagonisti grazie alla presenza del LOST sistemati in diversi reports rispetto ai domini che hanno partecipato a FGL JULY 2025 e il senso operativo è "quello dei Links Persi" o meglio sono stati gli autori a eliminarli e la presenza dei Disallow serve a coprire queste pessime operazioni.Naturalmente gli Engines "conoscono i veri intenti" degli operatori e appena si vede 1 Disallow è come avere un Report at a Glance anche rispetto "ai Veri Intenti degli Astuti Autori",ed è normale avere subito Uno Strike per i Disallow stessi e solo formalmente esistono 3 Strike,prima di arrivare all'eliminazione dell'account,perche' dopo aver trovato 1 Disallow,diventa facile fare "Strike davvero",perche' esiste la sicurezza di trovarne tantissimi altri:) E' un operazione talmente idiota da poter essere fatta solo da operatori allo stesso livello e occorre ricordare che ai Disallow è indispensabile anche Arrivarci,perche' le probabilita di essere eliminati prima dai Duplicati sono molto piu' elevate in generale e poi grazie al Brain che possiedono gli operatori che immaginano di arrivare ai Dati Veri tramite i Disallow,non esiste proprio speranza nemmeno d'iniziare i Match:)Nonostante le pubblicazioni eliminate,quelle sopra hanno i Content Validi e il paradosso è unito al fatto che sono anche aumentati,rispetto agli archi temporali precedenti e la posizione deriva solo dai Discover e cioe tante pubblicazioni sono state eliminate,pero' ne esistono un numero maggiore all'interno dei Content Validi:)Questo è un Compare nei 6 mesi precedenti,ed esistono varie opzioni,pero' il numero di Content Validi non cambia e rispetto all'attualita significano 50 pubblicazioni in piu':)E' questa posizione a dover essere unita ai SIZE,insieme alla creazione effettiva dei contenuti e per l'HEROIC DIN non esiste nessuna risistemazione,ma è esattamente il contrario e sempre gli stessi contenuti non hanno nessun apporto da autori esterni e l'esempio sistemato è quello di Key Stuffing Archive,attraverso i contenuti uniti alle Page Solemn e sempre Key Stuffing Archive,possiede un altro fantastico esempio e sono le tantissime String utilizzate sopratutto nei primi anni di questo dominio,unite al Plagiarism e in teoria dovrebbero essere su questo spazio,perche' le pubblicazioni protagoniste degli RF appartengono ad ESSO e formalmente sono poco minori a 100,pero' le pubblicazioni reali unite agli RF ne sono oltre 400 e quindi è facile comprendere quale sia la differenza nel possesso o meno delle STRING,rispetto ai SIZE e non essendo presenti le posizioni descritte,Resta UNA SOLA POSSIBILITA,rispetto al numero di Pubblicazioni che hanno ancora Content Validi e cioe' hanno Scritti Integrali e Naturali al 100%,attraverso 1 solo Content Creator e possono essere state Scritte SOLO UNA VOLTA,grazie al fatto che anche l'Holy Grail TFD Microsoft ha i Mismatch e nel suo Caso è definita la mancata compliance del Markup,pero' il senso è lo stesso del Mismatch e cioe' non puo esistere nessuna Modifica rispetto ai contenuti trovati la prima volta (è il Discover) e naturalmente gli stessi contenuti debbono anche essere validi,prima all'interno del dominio specifico e poi nel contesto globale e solo questa posizione forma i Dati Veri e il loro numero è quello degli INDEX sistemato sopra e per averli,occorre superare tutto il Quality Checks e sono equivalenti alle Quality Guidelines di Google e tutte queste posizioni possono avere Content scritti solo UNA Volta,senza nessuna modifica successiva:)
Anche le violazioni dei Copyright sono nei Calcoli degli INDEX e per comprendere cosa significa,è sufficente avere qualche Alta Rilevanza nei propri contenuti,ed esiste la sicurezza al 100% di ricevere contestazioni e la posizione è davvero Divertente,perche' il Powered dell'Holy Grail TFD Microsoft è il VERO ENGINE di tutti i "Presunti Engine",ritenuti vittime del monopolio del Trust da parte del Dipartimento Giustizia USA (DOJ:) nei confronti dell'Holy Grail TFD Google:) Il contesto Divertente è unito al fatto che il Vero Powered "dei presunti Engine" (è l'Holy Grail TFD Microsoft:) a sua volta è tra i principali contestatori per le violazioni dei Copyright,pero' sull'Holy Grail TFD Google e solo per avere un idea di cosa significa,è sufficente ricordare che Microsoft Corporation (ed è solo un elemento nelle contestazioni per Microsoft:) è circa 4 volte maggiore,rispetto a tutto il gruppo dell'HG TFD Bertelsman e sono i piu' "sensibili alle violazioni del copyright" e quindi il dato sopra ha un contesto davvero straordinario,sia per le dimensioni dei contenuti oggettivi a cui sono unite le possibili violazioni dei copyright e per il contesto stesso in cui è sistemato il report,ed è quello dell'Holy Grail TFD Microsoft,perche' a sua volta è uno dei primi contestatori,pero' su Google,ed è facilissimo trovarlo ad ogni Just Time e per il momento non ho dati esatti e posso citare solo alcuni numeri a memoria e sinceramente non ricordo nessun Just Time in cui l'Holy Grail TFD Microsoft non sia stato presente nelle contestazioni,ed è facile comprenderne il motivo,perche' i termini dei Just Time sono tutti ad Alta Rilevanza e sono i preferiti dai Contestatori,semplicemente perche' sono pagati proprio per questo motivo:) (attualmente i Just Time sono in DCE1 K5 ancora per poco tempo e significano 6 anni dei Just Time e quindi è facile immaginare anche il numero delle contestazioni :)Questo è un altro meraviglioso report rispetto ai dati sistemati,compresi i loro SIZE,insieme al metodo di creazione dei contenuti (senza risistemazioni;senza contenuti di altri autori;senza le String e naturalmente senza l'attivazione di tutti i codici uniti alle presunte ottimizzazioni:) e non esiste nessun URL bloccato e quindi tutti possono essere prelevati dalle selezioni e come conseguenza diretta non puo esistere nessun Disallow e quindi non possono essere negli Strike:) In teoria ne esistono 3 prima di avere l'Account eliminato,pero' al primo Strike dei Disallow,è facile prevedere l'Addio all'Account,perche' i Disallow vengono utilizzati quando gia' esistono altre violazioni e le loro maggiori applicazioni sono quelle unite agli Unnatural Links,meglio noti come Link Building e quindi i Disallow servono "in quantita industriali" e dopo averne trovato UNO,sono elevate le probabilita di trovarne centinaia e quindi dopo il primo Strike,è facilissimo arrivare al terzo e ultima violazione per l'intero account,naturalmente nell'ipotesi che i contenuti non sono stati eliminati prima dai Duplicati:)
Questi sono tutti i Backlinks da Any Site (sono equivalenti agli External di Google) e ne esiste solo UNO,grazie al fatto che è una pubblicazione risistemata e negli ANY Site,è compreso qualsiasi dominio dell'intero WEB e possono essere presenti anche tutte le Sister Site del dominio non presenti nelle proprieta'.Solo come esempio,in questa posizione potrebbe essere presente anche Key Stuffing Archive,perche' non è all'interno delle Proprieta e possiede un contesto anche molto Curioso da unire ai Backlinks stessi,grazie al fatto che Key Stuffing Archive ha quasi lo stesso numero di pubblicazioni di questo dominio,ed è molto curioso anche il suo SIZE,naturalmente realizzato grazie alla presenza delle comparazioni di Page Solemn,insieme alle tantissime String sistemate negli anni.Questo è solo Key Stuffing Archive tra le Sister Site non presenti nelle proprieta e insieme al dato sopra esistono anche 18 pagine interne e 1 solo Draft e quindi è a un centinaio di pubblicazioni da questo dominio e potrebbe contenere facilmente tanti backlinks verso questo spazio,perche' le String derivano da pubblicazioni di questo dominio e anche le Page Solemn hanno lo stesso legame,perche' sono nate per delle comparazioni con questo spazio.Posso assicurare di avere gia' tutti i dati e nonostante le Page Solemn;nonostante le String,anche unendole tutte insieme,non potranno mai arrivare al SIZE incredibile di Key Stuffing Archive:)La data del prelievo è MAR 12 2025 (lo è per Key Stuffing Archive) e il contesto piu' incredibile è il SIZE stesso di Key Stuffing Archive,ed è formato da 65,3 MB e 68,492 è il Peso su disco e cioe' il SIZE reale ed è tutto in file XML e cioe' compresso pure:)Attraverso questi dati,figurarsi se non potevano esistere dei Backlinks da UNA Sister Site e appena li ho visti,ho subito pensato a un elemento del Din Fantasy Calculator,ed è quello del Numero delle Posizioni in cui sono stati sistemati i contenuti:)
Per arrivare a 65,3 MB,addirittura in file XML,non sono sufficenti le Page Solemn e nemmeno le String,sommate insieme,perche' un SIZE del genere in XML e cioe' compresso,significa avere un file HTML (sono le pubblicazioni effettive) ampliamente maggiore a 80 MB:)Key Stuffing Archive ha esattamente le stesse impostazioni di questo dominio e cioe' nulla è abilitato e grazie ai Backlinks sistemati sopra (sia quelli di Google e di Microsoft) esiste la sicurezza che non sono presenti "rapporti da Syndicated Content",insieme a tutte le altre possibili violazioni e viste le dimensioni di Key Stuffing Archive sarebbe ampliamente possibile e la verifica è immediata,perche' se fossero presenti violazioni,non esisterebbe l'Account Generale:) (i possibili problemi derivano dal dominio principale e anche da tutte le Sister Site:)
Per avere il contesto rispetto ai dati sistemati,il miglior aiuto arriva proprio da Key Stuffing Archive e occorre ricordare che nel suo SIZE non sono comprese tutte le posizioni e i collegamenti sistemati sopra e nemmeno quelli uniti ai file CSV,perche' il prelievo del SIZE è arrivato molto prima (era MAR 12 2025:).Il collegamento è direttamente nel banner di Avoid Concern Trust e si ha la pubblicazione sopra e da essa è possibile arrivare a Data Unit Web Server 19.https://dinamic1hc.blogspot.com/2025/06/data-unit-web-server-19.html
In questa posizione per rendere piu' semplici i collegamenti,ho sistemato il link diretto per Data Unit Web Server 19.
Il motivo per cui esiste Data Unit Web Server 19 inizia dai dati sopra e da quelli sotto:)Questo era il SIZE del dominio a JUN 1 2025 e attualmente è anche un po' aumentato e la curiosita' è unita al fatto che dopo le conversioni fatte,insieme a tutte le comparazioni con Web Server 19,aggiungendo anche Data Unit Web Server,si arriva al SIZE di Key Stuffing Archive,pero' con una grandissima differenza,perche' tutti i dati sistemati nelle comparazioni hanno i dati in file HTML,mentre quelli di Key Stuffing Archive sono in file XML:)Solo la Fantasia Infinita della Casualita' poteva generare questi dati,perche' nemmeno impegnandosi al massimo e organizzare tutto di proposito,non sarebbe stato mai possibile avere questi dati:)Per avere solo un idea di cosa significano,in Data Unit Web Server è presente questa posizione,formata da 100 autori,ed è impressionante solo il loro elenco,oltre alla vastissima varieta degli autori stessi:)Sommati tutti insieme il dato arriva a 11 Million Words e la posizione è Super Artificiale e allo stesso livello lo è quella di Web Server 19,mentre sono naturali i dati di questo dominio e in parte lo sono anche quelli di Key Stuffing Archive,perche' le Page Solemn,insieme alle String non sarebbero mai arrivate al suo SIZE (tra l'altro le Page Solemn sono anche parziali,perche' tante le possiede anche AV2:) e quindi anche per key Stuffing Archive esistono contenuti naturali e cioe' realmente scritti da me stesso e non è possibile quantificarli,pero' esistono e visto il suo SIZE sono anche rilevanti nelle dimensioni e anche per key Stuffing Archive sono formate esclusivamente dai Content Effettivi presenti,grazie al fatto che non esiste nessuna abilitazione e quindi nemmeno i loro codici e non è presente nessuna presunta ottimizzazione e quindi non esistono nemmeno i loro codici:)
Dopo tutti i dati sistemati,ho scelto di cambiare le posizioni delle dimensioni,perche' il "dato tradizionale",nato da file XML a MAR 2019 non era piu' sostenibile nelle comparazioni dei dati:)
Quindi ho scelto di sistemarli insieme e quello piu' vicino alla realta,è proprio quello da 10,9 Million Words:)Arriva proprio dai calcoli di Data Unit Web Server 19 e il paradosso deriva dal fatto che è un dato anche molto relativo,perche' nei reports degli Holy Grail TFD Google & Microsoft è compresa anche la posizione sotto e da sola è capace di rendere molto relativo anche il Super Dato da 10,9 Million Words:)
E' il Din Fantasy Calculator a rendere molto relativo anche il Super Dato da 10,9 Million Words,ad iniziare dagli Average uniti al Comprehensive Amount e significano le Dimensioni stesse degli Average uniti alle Quality Guidelines per Google e ai Quality Checks per Microsoft e in pratica sono la stessa cosa e sono proprio loro ad essere presenti nei Reports sistemati sopra:)Esistono anche gli altri elementi del Din Fantasy Calculator e occorre ricordare che sono tutti pienamente operativi nel contesto online e dopo gli Average è simpatico citare anche il numero di posizioni in cui sono sistemati i contenuti e la differenza è elevatissima e la migliore esperienza è possibile averla attraverso le Page Solemn,grazie al fatto che è facile verificare quanto è difficile avere Content Validi in 1 sola posizione:)Per festeggiare i Content Validi in 1 sola posizione (rappresenta il valore effettivo di 1 dominio:) ho scelto questo contesto:)E' il GAP delle Keywords e cioe' le differenze che esistono tra 2 domini o qualsiasi altro numero.Naturalmente ho scelto i domini piu' Divertenti da unire al contesto e il Divertimento stesso è nelle posizioni evidenziate e permettono di Distinguere i Calcoli Veri,dai domini coinvolti.La stessa posizione è possibile applicarla a tutto il Syndicated Content e quindi a qualsiasi altra ottimizzazione e il senso è molto semplice,perche i Calcoli Veri si Fermano al Costo oggettivo dei CPC o PPC e sono i costi dei Clicks e solo loro sono Veri,mentre il resto,grazie ai domini coinvolti,rappresenta un contesto molto piu' vicino alla Science Fiction rispetto alla Realta' dei Dati:)
Lo strumento è validissimo,pero' non è un Engine e cioe' non conosce i Dati Veri e gli Estimated dei costi finali (l'arco temporale è 1 mese) sono una Stima dei Costi reali,pero' difficili da rendere compatibile con Wiki EN e Dumps Wikimedia,perche' il loro GAP delle Keywords è decisamente evanescente:)Per comprendere la posizione l'evidenza piu' Divertente è ORGANIC e nei Dati Veri ha 1 solo riferimento,ed è quello della Natural Search,completamente incompatibile con Wikimedia e a scalare lo è anche rispetto a qualsiasi altro operatore SEV (solo nominare la Natural Search rispetto agli operatori citati è equivalente all'Acqua Santa gettata su satana :).L'Organic è la prima risposta unita alla Natural Search e vista la presenza di Wiki EN e Wiki Dumps,il Divertimento diventa comprensibile e per aumentarlo è sufficente citare un altra evidenza,da cui derivano i dati sistemati sopra,ed è l'unione tra Domain e Subdomain presenti nei calcoli,difficilissimi da rendere compatibili con l'Organic e cioe' Natural Search.Sistemando i Subdomain si attiva l'Elsewhere nei Duplicati e quindi non esiste proprio nessuna speranza di arrivare all'Organic,perche' la sua prima violazione sono sempre i Duplicati:)
Questa è una sezione dell'immagine precedente e serve per descrivere le altre evidenze: (MAX C...) è il costo massimo per 1 Click e il riferimento è solo Google USA,attraverso il Device Mobile e vicino ad essa esistono le Competition e nel Caso specifico sono in Low e quindi figurarsi i costi degli High.Esiste un altra posizione non evidenziata (è quella con i puntini gialli vicino ai costi massimi per 1 Click) ed è il Keywords Difficulty e in realta sarebbe lo Stuffing,ed è impossibile renderlo compatibile con l'Organic,perche' quest'ultimo è determinato solo dalle Proposte Complessive e lo strumento è validissimo pero' non è un Engine e quindi diventa un Estimate anche il Keywords Stuffing,semplicemente perche' i Dati Veri non si conoscono:)Se esistesse l'Organic e cioe la Natural Search Vera;se non esistesserro i Domain uniti ai Subdomain;se esistesse il vero keywords Stuffing,allora quelli sopra sarebbero i costi in 1 mese e sono applicati a Google USA :)I calcoli sono Veri,pero' è Ignorato il percorso per Arrivarci e la posizione è normale,perche' lo strumento non è un Engine e quindi applica ai calcoli quello che conosce.Questa posizione,oltre alla curiosita,possiede dati molto importanti,da unire a qualsiasi reports,sopratutto per i simpaticissimi utenti che pagano i servizi degli ottimizzatori e cioe' gli operatori SEV e l'unica vera garanzia è quella di mandare i loro utenti nelle Gravi Violazioni,perche' le "brillanti idee dei SEV" non sono proprio Compatibili con la Natural Search o Organic,mentre utilizzano tantissimo i Subdomain e solo la loro presenza rende ancora piu' difficile essere in Organic e poi si è aggiunta la Bella Notizia di tutte le ottimizzazioni,arrivate al Top delle Violazioni,ed è sempre quella dei Duplicati:)Esiste una sola evidenza ancora non citata,ed è quella dei mobili e il motivo è quello sotto:)Questo è il motivo per cui sono presenti i Mobili nei costi dei clicks sistemati sopra e anche loro appartengono all'incredibile anno 2015 e insieme a tutti gli altri fantastici coetanei,rendono molto semplice la valutazione dei costi stessi:)
Nei fantastici coetanei è compreso anche Sundar Pichai e per festeggiare i suoi 10 anni alla guida di Google ho utilizzato il logo del Demonstrate Juice Data Archive perche' ha l'unione piena con la LOGICA dei Dati Veri ,ed è l'Unica e Vera posizione dominante:) DOJ e tutta la nazione USA debbono solo ringraziare di aver avuto la fortuna che Google sia nata da loro,perche' è l'unico vero sostegno ai suoi servizi e cioe' all'81% di tutta l'economia USA e i servizi hanno stretta necessita di possedere solo Dati Veri e le altre Big Tech non sono assolutamente capaci di farlo e sopravvivono solo grazie alla presenza di Google:)
Solo immaginare il contesto online,tramite le impostazioni di Wikimedia;Amazon;Social Media e tutte le altre Big Tech,renderebbe felice un unico soggetto ed è il China Planet e per questo motivo ha sempre attaccato Google,perche' gli altri sono uniti solo a Dati Falsi,completamente separati dalla Logica e per il China Planet non rappresentano una Preoccupazione,perche' è molto piu' facile Competere con i Falsi,grazie al fatto che il primo Falso del pianeta Terra è il China Planet stesso,ed è sufficente vedere solo Baidu,per averne la conferma:)
Esistono tante altre selezioni ,pero' la pubblicazione ha gia' dimensioni notevoli e quindi altri contenuti saranno in prossime pubblicazioni e tra l'altro,tante descrizioni sono anche nei domini che hanno partecipato a questo straordinario FGL JULY 2025:)

PUB2
 IAB JULY 2025 140 PUB 68% UN 2467 AV 67 ILA FULL SIZE 80 Total Links Page 188 KB Average (264 ms Average Loading)
IAB JULY 2025 140 PUB 68% UN 2467 AV 67 ILA FULL SIZE 80 Total Links Page 188 KB Average (264 ms Average Loading)
3445380 VOL. VS 26,320 MB VS 80 TLP Full Size32% DUP VS 110521 Volume eliminato VS 9380 Internal Links (ILA) VS 11200 Total Links Page
 170 PUB 31% UN 11426 AV 48 ILA 62 TLP (Total Links Page) FULL SIZE 230 KB Average(419 ms è l'Average del Time Size)
170 PUB 31% UN 11426 AV 48 ILA 62 TLP (Total Links Page) FULL SIZE 230 KB Average(419 ms è l'Average del Time Size)
242420 VOL. VS 39,100 MB Full Size 69% DUP VS 167269 Vol. Eliminato VS 8160 Internal Links (ILA) VS 10540 TLP (Total Links Interni + Esterni al dominio)
 153 PUB 32% UN 1104 AV 59 ILA 268 KB Full SIZE (749 ms Average Loading)168912 VOL. VS 41,004 MB 68% DUP VS 114860 VOL. Eliminato VS 9027 Internal Links VS 10863 Total Links (interni + esterni al dominio) VS 114,597 secondi Time Loading Full Size
153 PUB 32% UN 1104 AV 59 ILA 268 KB Full SIZE (749 ms Average Loading)168912 VOL. VS 41,004 MB 68% DUP VS 114860 VOL. Eliminato VS 9027 Internal Links VS 10863 Total Links (interni + esterni al dominio) VS 114,597 secondi Time Loading Full Size 
July 2025 549 Average per 220 pubblicazioni ha raggiunto il 38% avendo anche 65 TLP in Average in 1 dominio Full Size:)
Nel report di July 2025 per Comscore esiste anche questa posizione:nelle prime 9 pubblicazioni a cslare nelle dimensioni,esistono anche 5 Detect language in 1 solo dominio:)
A 192 PUB 67% UN 137 KB AV SIZE 241 ms AV Loading 3125 AV Keywords 50 AV Internal Links 63 AV TLP (total links interni + esterni al dominio) 600000 VOL. VS 26,304 MB FULL SIZE 33% DUP 198000 Vol. Eliminato VS 9600 Internal Links (ILA) VS 12096 TLP VS 46,272 secondi Time Full SIZE
97743 VOL. VS 8,370 MB
61% DUP 59623 VOL. Eliminato VS 3999 Internal Links VS 5394 TLP
Questo è il motivo per cui esistono selezioni relativamente scarse nel dominio di Semrush:esistono 29 codici Canonical;70 Disallow e altri NOINDEX,a cui hanno aggiunto anche dei Broken Links e sono Veri anch'essi:) Il codice Canonical esiste realmente,pero' è sistemato solo da Semrush,ed essendo "un antico operatore SEV",simile a MOZ,esiste anche l'AutoConsiderazione e cioe' Semrush immagina di essere un Autorita',pero' senza mai avere nessun DEMONSTRATE:) Questa è un altra posizione capace di giustificare il motivo per cui le selezioni di Semrush sono relativamente scarse.Occorre ricordare che esistono quasi 100K termini effettivi in 1 sola posizione e l'Average è maggiore a 4 volte quello dei contenuti tradizionali e quindi la definizione di scarso rispetto al volume della selezione,è sempre relativa:) (se fossero i contenuti tradizionali,per avere l'equivalenza della selezione specifica,servirebbero 8 volumi da 200 pagine ciascuno:) Tornando ai Disallow di Semrush ne esistono 70 in 1 sola selezione e sono tutti effettivi,compreso quello unito alle Enterprise e significa che i robots txt sono abilitati e anche largamente utilizzati:)Questa posizione è molto utile perche' rende facile comprendere il valore degli Altri Dati:) Dopo il volume relativamente scarso della selezione,è presente anche il Plus dell'Ottimismo del report specifico e sono i tanti subdomain presenti in 1 solo spazio e sono LORO a formare gli Elsewhere,uniti ai Duplicati e quindi figurarsi cosa sarebbe il report se esistessero anche le selezioni di 894 Subdomain (895 comprende anche lo spazio principale:).
Esiste anche la presenza di tanti Detect Language e nei Subdomain sono presenti alcuni esempi e il totale nello spazio di Semrush è formato da 14 Detect language e anche loro fanno parte delle selezioni.Nonostante tutti i limiti sistemati,rispetto al contesto piu' ottimista,i Duplicati esistono lo stesso in gran numero,ed è facile immaginare cosa sarebbero i dati se venissero applicati anche le posizioni dell'Elsewhere,semplicemente perche' i Subdomain esistono e uniti a Semrush,non è possibile "aspettarsi nulla di buono":) Se nel Contesto Online non esistessero gli Engines e non fosse presente nessuna LOGICA,per iniziare a sistemare dei Dati VERI è possibile cominciare da Semrush,ed è sufficente fare l'opposto delle sue operazioni,per avere i Dati Veri:) I Subdomain in mano a Semrush rendono facile comprendere il motivo per cui sono nelle Gravi Violazioni e rende anche semplice comprendere il motivo per cui esistono gli Elsewhere uniti ai Duplicati e per Semrush è uno sforzo del tutto inutile,perche' il suo dominio diretto ha gia' "dei gran Duplicati",senza nessuna necessita di unire anche i suoi Subdomain:)


53% DUP. 173074 VOL. Eliminato Vol. Immune 153482 Average Immunita 795 VS10422 è il totale degli ILA e 17370 sono stati i Total Links (TLP )Quindi se esistesse il contesto piu' Ottimista dei reports (Fundamental Search;Strutture Data;generative content;Scraping;Violazione Copyright e tutte le altre Quality Guidelines Assenti) e non fosse avvenuto nessun Match in precedenza (è un Evento che non si mai verificato:) i contenuti rimasti immuni dai Conflitti dovrebbero coprire 17370 Total Links Page (interni + esterni al dominio) e cioe' dovrebbero essere quasi tutti degli Anchor Text:)All'Ottimismo dei dati,occorre aggiungere anche questa posizione,ed è quella dell'Elsewhere unita ai Duplicati e quindi i dati reali sarebbero anche peggiori e solo per restare nei Veri Intenti per cui esistono i Subdomains (sono i simpatici rilevamenti di base e cioe' dei numeri,senza nessuna unione con i Dati Veri:) la posizione sopra amplifica in maniera esponenziale le Top Cause dell'Invalid Traffic e formalmente ne esistono tantissime,pero' nella realta' solo UNA Top Causa è realmente decisiva,anche rispetto alla sola presenza di tutte le altre,ed è l'Original;Unique e Content Value e cioe' la Top Causa regina dell'Invalid Traffic e la posizione sopra del dominio di Turnitin è la migliore evidenza:) Questo è il suo DNS e cioe' il Provider o ISP e la posizione è molto Divertente da unire agli High Fail Rate,sopratutto rispetto ai DNS,perche' diventa del tutto inutile avere la verifica del proprio ISP per certificare i dati,grazie al fatto che il simpatico dominio di Turnitin non ha nessuna Preoccupazione rispetto agli High Fail Rate,semplicemente perche' non ci Arriva Proprio:)Qualsiasi violazione che avesse commesso,arriva sempre dopo i Duplicati e quindi anche se esistesse Tutto Scraping o generative content,non cambia assolutamente NULLA e per il simpatico dominio di Turnitin,spero che i suoi Dati Scarsi siano almeno Naturali:)

242 PUB 91% UN 5569 AV 176 ILA FULL SIZE 57 KB AV SIZE 324 ms è l'Average dei Loading
1347698 VOL. VS 13,794 MB 9% DUP. 121292 VOL. Eliminato VS 43076 TLP (35712 TLP Total Links Page sono stati presenti a JUN 2025 per il dominio dell'enciclopedia Astronautica) e 78,408 secondi è il Loading per l'intera selezione di JULY 2025 161 PUB 55% UN 1033 AV 94 ILA Full Size 392 KB Average (1033 ms AV Loading)
45% DUP VS 110 TLP 230391 VOL. VS 63,112 MB Full SIZE45% DUP 103675 VOL. Eliminato
Vol. Immune 126716 Average effettivo 787
VS
15134 ILA VS 17710 TLP (sono applicati al volume rimasto immune formato da 126716 Keywords:) VS 117,072 secondi Time Loading
 Computer World 248 PUB 54% UN 2330 AV 77 ILA 248 KB Average Full Size (326 ms AV Loading)
Computer World 248 PUB 54% UN 2330 AV 77 ILA 248 KB Average Full Size (326 ms AV Loading)
46% DUP. VS 109 TLP 577840 VOL VS 61,504 MB Full SIZE46% DUP 265806 Termini Eliminati VS312034 Vol. Immune e 1258 è l'Average effettivo rimastoVS19096 Internal Links VS 27032 Total Links (interni + esterni) VS 80,848 Loading Time Full Size
 Wikitech Wikimedia 235 PUB 83% UN 1557 AV 64 ILA 3760 Skipped e 3745 sono i Disallow.Full SIZE 74 KB AV (301 ms AV Loading)
Wikitech Wikimedia 235 PUB 83% UN 1557 AV 64 ILA 3760 Skipped e 3745 sono i Disallow.Full SIZE 74 KB AV (301 ms AV Loading)17% DUP VS 89 Total Links Page
365895 VOL. VS 17,390 MB Full Size
17% DUP 62202 Vol.Eliminato 303693 Vol. Immune 1292 AV Effettivo KeywordsNei domini Wikimedia il "Volume rimasto immune dai Match" è molto relativo,perche' non sono considerate le pubblicazioni in Disallow e nemmeno i PROSE che Wikimedia Decide da Sola:)Sono i contenuti che hanno scritto realmente gli autori wikipediani e mediamente sono inferiori al 50% rispetto ai termini effettivi presenti nelle pagine dei domini Wikimedia e occorre ricordare che i suoi EDITS sono uniti proprio ai Prose e quindi per forza di cose ,i calcoli dei termini rimasti immuni dai Match sono molto relativi,pero' la loro presenza è sempre importante,perche' grazie alla Demenza Operativa di Wikimedia,diventa molto facile la comprensione di qualsiasi altro report:) VS Ipotizzando che il dominio Wikitech abbia tutte "Posizioni Naturali" (nella realta non ne esiste nemmeno UNA:) attraverso i termini rimasti immuni dai Match (303693 e 1292 è l'Average) deve sostenere 15050 Internal Links e 20915 Total Links PageOccorrono Tanti Auguri per Wiki e il migliore di essi ,sarebbe "un Trapianto del Brain" perche' sono stati gli operatori a sistemare i Links e il numero non è proprio compatibile con la LOGICA dei Dati Veri:) Il CMS di Wikitech è MediaWiki e il Provider è sempre Wikimedia e la posizione conferma uno dei soggetti piu' Divertenti del contesto online e sono i Custom CMS,grazie solo al loro costo:)Nella realta' i CMS e cioe' le Piattaforme,non determinano assolutamente NULLA e i domini Wikimedia,rappresentano il migliore esempio,perche' tutte le operazioni sono decise dal BRAIN degli autori e naturalmente sono sempre gli stessi BRAIN a creare anche i contenuti:)Visto il contesto molto particolare di MediaWiki


A 238 PUB 71% UN 222 KB AV SIZE 539 ms AV Loading 2931 AV Keywords 647 AV Internal Links (ILA) 745 AV TLP Total Links Page
697578 VOL. VS 52,836 MB FULL SIZE
29% DUP 202297 VOL. Eliminato
VS
495281 VOL.Immune e 2081 è il suo Average
Anche questi dati per i domini Wikimedia sono sempre relativi ad iniziare dal fatto che non sono presenti le pubblicazioni in Disallow e per JULY 2025 sono state 3847 per Wiktionary su 3859 Skipped e poi occorre aggiungere anche il PROSE:)
Queste sono le dimensioni dell'intera pagina,ed esistono piccole differenze nei Calculator,pero' non sono nemmeno lontanamente paragonabili al PROSE di Wikimedia:)
Normalmente utilizzo l'URL (nel Caso specifico è quello sistemato sopra) per conoscere le dimensioni,pero' il Calculator ufficiale non ha ritenuto l'URL valido e per avere i dati sopra,ho fatto l'upload dell'intera pagina e in questo Caso la risposta è stata positiva e il calcolo delle dimensioni è quello sopra.
Nello stesso report è presente anche il Calculator di MS Words,ed è quello della Microsoft e poi esiste anche il Calculator fantastico delle verifiche e occorre ricordare che tutti i suoi dati ,assai maggiori rispetto a quelli del Calculator Ufficiale,avvengono i millesimi di secondo e nel Caso specifico esiste anche l'Average ed è formato da 539 ms e cioe' ogni reports,ha richiesto circa mezzo secondo e ne sono tantissimi quelli di JULY 2025 per Wikitech:)
Ho descritto il contesto dei Calculators per evidenziare al massimo i dati che seguiranno e iniziano dalla posizione sotto:)
https://en.wiktionary.org/wiki/Wiktionary:Beer_parlourRispetto ai dati che seguiranno,è indispensabile ricordare il SIZE e in tutti i domini Wikimedia,non esistono posizioni strutturali (Wikimedia li chiama Template,pero' in realta sono dei termini effettivi e formano solo dei Common Content e cioe' sono dei Duplicati anche loro:).
Il SIZE completo della selezione,escluse le pubblicazioni in Disallow è formato da 52,836 MB,ed è un peso notevole,sopratutto nei confronti dei termini effettivi presenti e quelli rimasti immuni sono formati da 495281 Keywords,pero' senza il calcolo del PROSE e cioe' dei contenuti che hanno scritto effettivamente gli autori wikipediani:)
Esistono decine di migliaia di EDITS e centinaia di Reverted (sono le guerre degli EDITS:) per 1 sola pubblicazione e il dato piu' importante è quello del PROSE,ed è formato da 11K termini e quindi la pagina che contiene la pubblicazione ha una dimensione pari al 600% maggiore,rispetto al PROSE e queste percentuali con variazioni si ripetono per tutte le pubblicazioni dei domini Wikimedia e quindi per Giusta Causa,la grande organizzazione Wikimedia è anche il Capo dei SEV e cioe' i ricercatori che operano esclusivamente solo per arrivare alle Egregious Violation:)
Quindi i numeri di Wikimedia sono sempre assai relativi,tranne per 1 posizione,ed è quella sotto:)
Le Keywords di tutti i domini Wikimedia sono "Ampliamente Variabili" grazie al PROSE sistemato sopra,mentre non sono Variabili i links sistemati e sono gli operatori stessi a farlo:)
La pubblicazione sopra ha l'Average dei SIZE e naturalmente è quello effettivo ,grazie ai termini realmente presenti nella pagina,ed esistono 668 LINKS:)
Ho scelto di sistemare questa posizione,perche' a memoria,non ricordo proprio nessuna selezione di Wiktionary che abbia mai avuto 647 ILA (sono gli Average degli Internal Links) e 745 TLP (è un Average anch'esso rispetto alla somma degli internal + external links)
Questa è la pubblicazione che ha l'Average dei SIZE per la selezione di JULY 2025 di Wiktionary ,ed è formato da 222 KB,ed ha 668 Links e occorre ricordare che solo i termini effettivamente scritti li rendono validi,tranne naturalmente quelli in Duplicato e per i domini Wikimedia,diventa Tutto Molto Complicato,grazie ai Dati Sotto:)
153986 sono stati gli Internal Links e 177310 sono stati i TLP e anche se non esistessero i PROSE e fosse realmente valido il volume rimasto immune dai Match (495281 Keywords) è talmente elevata la presenza dei Total Links Page da rendere impossibile la compatibilita' con le Keywords Immuni e quindi figurarsi quali possono essere i rapporti,inserendo i Dati Veri di Wiktionary e cioe' quello che hanno scritto realmente gli autori wikipediani,ed è nei dati del Prose:)
Se il rapporto fosse la meta' rispetto a quello sistemato (600% maggiore da parte dell'intera pagina rispetto alle Keywords del Prose:) ,ed è solo un ipotesi,il volume immune di Wiktionary,sarebbe minore di 1/3 rispetto a quello sistemato e significano 165K Keywords e quindi,solo nel numero,i TLP sarebbero maggiori:)
L'ipotesi è anche ottimista,perche' è presente un altro elemento Senza Variazioni,ed è quello dei SIZE,ed è spropositato anche rispetto al volume complessivo (52,836 MB non sono proprio compatibili con un volume da 697K termini,sopratutto in 1 dominio Full Size:) e quindi figurarsi cosa significa unire il volume effettivamente scritto dagli autori Wikipediani,perche' ad essere proprio ottimisti,i termini effettivi sistemati in 1 pagina,mediamente sono il 300% maggiori,rispetto ai contenuti presenti nei PROSE e sara' curioso verificare l'opposto:)
Per il momento esiste la verifica dei Backlinks e sono gli Inbound "tanto amati da Moz" e applicati a Wiktionary,occorre avere un Brain da Kamikaze:)
I Backlinks degli operatori online sono sempre Approssimativi,perche' prelevano qualsiasi collegamento,senza conoscere quali sono i Dati Veri e il migliore esempio è quello dei TLP sistemati sopra,completamente incompatibili con i links,nemmeno se esistesse il volume originale,senza unire nessun PROSE e non dovrebbero esistere nemmeno i Match:)
In questa posizione,rispetto ai Backlinks,almeno una distinzione esiste e naturalmente è utile solo per dare un riferimento,perche' i dati sopra applicati a Wiktionary,esprimono solo il numero di Kamikaze e sinceramente spero che nei DOFOLLOW rispetto a Wiktionary non siano presenti Autori Onesti,perche' sarebbe davvero difficile unire il loro EFFORT alla Relationship con Wiktionary,grazie al fatto che è sicuro al 100% il Ritorno dei Links stessi al dominio di Partenza:)
Quindi spero che tutti i Dofollow appartengano ad Autori Disonesti,perche' sono gli unici compatibili con Wikimedia e spero i Disonesti siano tutti nella selezione dei Text Links ,perche' sono gli unici ad avere valore (la distinzione con i backlinks delle immagini non produce nessun valore:) in senso generale,pero' è indispensabile vedere a quali domini sono uniti e se fosse quello di Wiktionary, i 214 Million di Text Links,hanno la certezza di tornare al dominio di partenza e per l'Astuto Operatore,diventera' una violazione,naturalmente se dovesse avere Content Validi,ed è un ipotesi molto remota,perche' dare Vantaggi a Wikimedia,significa avere il Brain pieno di Spam e da un contesto del genere è molto difficile che possano nascere dei Content Validi:)


 195 PUB 91% UN 5786 AV 102 KB AV SIZE 143 ms AV Loading 30 Average Internal Links
195 PUB 91% UN 5786 AV 102 KB AV SIZE 143 ms AV Loading 30 Average Internal Links
9% DUP VS 65 TLP
1128270 VOL. (457056 è stato il volume a JUN 2025) VS 19,890 MB Full Size
Dup 9% 101544 VOL. Eliminato VS 12675 TLP VS 5850 Internal Links Average (ILA) Questo è l'inizio della selezione a scalare nelle dimensioni per i "Poeti Tradotti" e al suo interno esiste di tutto:Da Ariosto a Petrarca,passando per Omero e Garcia Lorca e sempre nelle selezioni di July 2025 esiste anche il Signor Alighieri Dante e il Signor Leopardi Giacomo:) I nomi degli autori effettivi sono scritti sempre iniziando dal cognome e l'informazione è importante perche' è l'unico EFFORT degli operatori del dominio:) Queste sono le principali nazioni da cui derivano i fantastici autori tradizionali e poi esiste la "Variante Various" rispetto a tante altre opzioni e l'insieme forma la selezione da 195 pubblicazioni del dominio specifico e l'informazione è importante perche' esiste anche la posizione sotto:) In 1 colpo solo è presente la Grande Preoccupazione per le violazioni del Copyright;esiste il Donate per le offerte economiche,insieme allo SHOP e grazie al notevole EFFORT nella sistemazione di contenuti di altri autori,presenti in altre migliaia di domini,per il gestore dello spazio specifico "sembra una Cosa Giusta da Fare":)

 210 PUB 95% UN 1392 AV 47 ILA (Internal Links Average) 54 TLP (Total Links interni e esterni al dominio)
210 PUB 95% UN 1392 AV 47 ILA (Internal Links Average) 54 TLP (Total Links interni e esterni al dominio) 292320 VOL. VS 4,830 MB Full Size
5% DUP 14616 Volume eliminato VS 9870 Internal Links VS 11340 Total Linkshttp://www.zeno.org/Kategorien/T/Bibliothek?fr=A
Oltre alle divisioni degli autori sistemati sopra (letteratura filosofia) quello appena inserito è il numero esatto da cui derivano le selezioni del dominio (sono oltre 1 Million:) e contiene anche le categorie divise in ordine alfabetico e poi esistono anche "le sottocategorie" e lo sono solo per ZENO.ORG,perche' in qualsiasi altro dominio sarebbero delle categorie loro stesse e quella piu' curiosa "è la sottocategoria dedicata alla Filosofia":)Per ZENO.ORG la Filosofia è classificata in sottocategoria,mentre per il database dei Filosofi (è presente anche Plato:) esistono le Categorie della Filosofia e quello sopra è solo l'inizio:)
Questo è un altro esempio,unito a un altra categoria della Filosofia e i dati indicano il numero di pubblicazioni presenti e per comprendere quale sia l'entita delle dimensioni in 1 solo dominio,è sufficente ricordare che Philpapers è stato l'unico dominio a superare Encyclopedia,nonostante l'unione di 200 High learning,iniziando da Oxford e Columbia University:)
https://philpapers.org/browse/allQuesto è l'ultimo esempio e per comprendere le dimensioni delle Categorie unite alla Filosofia è sufficente l'evidenza del cursore laterale e in pratica ha appena iniziato il suo percorso e sommando solo gli esempi,esistono gia' oltre 100K pubblicazioni:)
Per ZENO.ORG la Filosofia è invece una sottocategoria e a parte la disputa,queste posizioni sono importanti per comprendere qualsiasi altro dato,grazie agli unici elementi mancanti e sono i MAIN CONTENT e aiutano tantissimo a comprendere il valore dei Match e il dominio ZENO.ORG è un ottima evidenza,perche' le selezioni del suo JULY 2025 sono arrivate dal contesto appena descritto e sarebbe l'ideale per avere Meno Duplicati possibili,pero' debbono essere presenti i Main Content,insieme all'unica Autorita Effettiva e sono Esclusivamente i Content Creator e solo loro possono avere i Dati Veri:)
Esiste anche la LOGICA Completa,perche' qualsiasi operatore potrebbe utilizzare lo stesso sistema e cioe' "utilizzare contenuti di altri autori" e solo in questo JULY 2025 esistono gia' diversi domini che fanno le stesse operazioni e per arrivare alla Logica Completa,è sufficente ricordare i dati effettivi che hanno i singoli autori tradizionali,utilizzati dai domini dedicati alla Letteratura e tranne poche eccezioni,il resto è parecchio scarso,senza avere nessuna garanzia che a loro volta possiedano dei contenuti originali gli autori tradizionali stessi:) La larga esperienza,indica l'opposto dell'originalita' e tanti autori tradizionali hanno fatto carriera solo grazie all'IGNORE:)

Nonostante il contesto descritto e cioe' dominio senza Main Content,realizzato attraverso contenuti di altri autori (sono operazioni fatte anche in altre migliaia di spazi:) sono presenti un numero molto elevato di Links,ed è sufficente solo immaginare il contesto online realizzato attraverso il metodo descritto e sarebbe il fallimento,perche' non esiste nessuna Logica nei Dati (tutti sistemerebbero i contenuti di altri autori,a prescindere dal valore dei medesimi:) ad iniziare dalla percentuale dei DOFOLLOW,perche' avere quel dato sopra,per dare un presunto vantaggio a ZENO.ORG,significa che i segnalatori,hanno lo stesso percorso del dominio segnalato e cioe' creano spazi senza nessun EFFORT,ed è possibile farlo solo utilizzando contenuti di altri autori (anche attraverso Scraping:) e di sicuro è l'unica ragione per cui esistono i Dofollow sistemati sopra e non sono nemmeno soli,perche' esiste anche l'immagine sotto:)
Al 97,8% i links derivano dai Text effettivi e cioe' dalle Keywords e la posizione è anche normale,perche' è l'unica a fornire valore ai Links stessi e il Grande Problema è la condizione che debbono avere "gli astuti segnalatori" e cioe' debbono essere LORO ad avere Content Validi,prima di fare le segnalazioni,ed è proprio Impossibile averli Senza EFFORT e di conseguenza,non è assolutamente Credibile che i segnalatori siano cosi Idioti ,da fornire vantaggi a un dominio come ZENO.ORG:)



 138 PUB 80% UN 1658 AV 99 Internal Links Average (ILA) 41 KB Full Size in Average (768 ms AV Loading)
138 PUB 80% UN 1658 AV 99 Internal Links Average (ILA) 41 KB Full Size in Average (768 ms AV Loading)
228804 VOL. VS 5,658 MB Full SIZE
20% DUP. VS 104 TLP Av
Dup 20% 45760 VOL. Eliminato VS 14352 TLP VS 13662 Internal Links complessivi
Il dominio Gutenberg ha le stesse condizioni descritte per i "Poeti Tradotti" e per lo spazio di ZENO.ORG e cioe' esistono solo contenuti di altri autori e la stessa cosa accade per il dominio successivo,ed è quello di Novel Guide:)
 250 PUB 25% UN 1836 AV 338 ILA Full Size 77 KB Average (834 ms AV Loading)
250 PUB 25% UN 1836 AV 338 ILA Full Size 77 KB Average (834 ms AV Loading)
75% DUP. VS 374 TLP459000 Keywords VOL. VS 19,250 MB Full SIZE75% DUP. 344250 Vol. Eliminato VS 93500 TLP Complete VS 84500 Internal Links completi VS 208,500 secondi Loading Time Full Size
 244 PUB 86% UN 3338 AV 330 ms AV Loading 34 AV Internal Links
244 PUB 86% UN 3338 AV 330 ms AV Loading 34 AV Internal Links 814472 VOL. VS 18,300 MB Full Size
14% DUP VS 49 TLP
14% DUP 114026 volume termini eliminati VS 11956 Total Links VS 8296 ILA
 162 PUB 93% UN 5261 AV 417 ms AV Loading 109 KB AV Size 47 AV Internal Links
162 PUB 93% UN 5261 AV 417 ms AV Loading 109 KB AV Size 47 AV Internal Links
852282 VOL. VS 17,658 MB Full SIZE7% DUP 59659 Vol Eliminato VS 7614 ILA VS 10206 Total Links Page VS 67,554 secondi Time Full Size Loading



Enciclopedia Cattolica 243 PUB 97% UN 6469 AV 172 ILA Full SIZE 61 KB AV (663 ms AV Loading)
3% DUP VS 174 TLP
1571967 VOL. VS 14,823 MB Full SIZEDup 3% 47159 VOL. Eliminato VS 42282 TLP Complete VS 42282 Internal Links VS 161,609 secondi Loading Time Full Size.
 IONOS JULY 2025 225 PUB 59% UN 2016 AV 60 ILA 393 KB Full SIZE Loading AV 883 ms453600 VOL. VS 88,425 MB Full SIZE41% DUP VS 100 TLP41% DUP 185976 Volume eliminato VS 22500 TLP Completi VS 13500 Internal Links Completi VS 198,675 secondi Loading Time Full Size.
IONOS JULY 2025 225 PUB 59% UN 2016 AV 60 ILA 393 KB Full SIZE Loading AV 883 ms453600 VOL. VS 88,425 MB Full SIZE41% DUP VS 100 TLP41% DUP 185976 Volume eliminato VS 22500 TLP Completi VS 13500 Internal Links Completi VS 198,675 secondi Loading Time Full Size.
Il Provider o ISP di IONOS è LUI stesso e la posizione è molto curiosa rispetto ai DNS,perche' esistono anche i dati sotto:)E' il contesto ideale da unire all'High Fail Rate,rispetto ai DNS,perche' rende molto semplice comprendere quanto sia elevata la difficolta solo per Arrivarci e grazie a oltre 10K Subdomain (è il limite del report) l'Elsewhere unito ai Duplicati ha la presenza garantita e quindi la Preoccupazione dell'High Fail Rate diventa inutile,perche' sono elevati gia' i Duplicati in proprio senza aggiungere l'Elsewhere e naturalmente senza unire le violazioni successive

Per IONOS è sufficente ricordare questa posizione,per indicare quali sono le violazioni successive ai Duplicati e il contesto diventa generale e cioe' valido per qualsiasi dominio,perche' è oggettivamente molto difficile trovare un contesto tecnico equivalente a IONOS e quindi diventa facile la valutazione di qualsiasi altro dominio,ed è possibile averla solo attraverso la Logica dei Dati Veri e non esiste nessuna possibilita di utilizzare "strategie alternative",comprese quelle "Fantasticate nell'Immaginazione di IONOS" e la definizione pratica è quella del "link building sostenibile" nelle OFF Pages di IONOS e cioe' è una cazzata sesquipedale e serve solo a confermare che la Logica dei Dati Veri ha valore per qualsiasi dominio,IONOS compresa e da questa posizione è nata l'idea del General Joy Experience Value,naturalmente solo per gli Autori Onesti,mentre per gli altri,il contesto di IONOS diventa un Ammonimento e cioe' non esiste proprio nessuna speranza di Fare i Furbi ,attraverso le strategie alternative:)
Litigation Network 183 PUB 53% UN 992 AV 67 ILA Full SIZE 85 KB 748 ms AV Loading
47% DUP. VS 83 TLP
181536 VOL. Keywords VS 15,555 MB Full SIZE
47% DUP 85321 Vol. termini eliminati
VS
96215 VOL. Immune e 525 è l'Average dei termini e quindi è un Thin Content:)
VS
15189 TLP (è il numero dei links interni + esterni al dominio da sostenere attraverso il volume rimasto immune dai Match) VS 12261 ILA VS 136,884 secondi Loading Time Full Size
Per i simpatici avvocati del network delle Litigation è una catastrofe e l'unica speranza è quella che non siano gli avvocati di ACC ad essere contestati,perche' con i dati che hanno non esiste nessuna speranza di sostenere le contestazioni:)
I dati in generale sono decisamente scarsi per i simpatici avvocati delle Litigation e poi prima di arrivare a tutte le altre violazioni,esistono anche tanti Subdomain da unire ai Duplicate,tramite l'Elsewhere e il piu' simpatico è quello degli Autori di ACC:) Spero che le dispute legali siano migliori,rispetto ai contenuti oggettivi di ACC,pero' la speranza è proprio ridotta al lumicino,perche' nei dati è presente anche il valore del Brain degli operatori e appartengono sempre ad ACC e cioe' al Network delle Litigation,ed esiste l'evidenza che il Brain specifico è decisamente scarso e quindi l'unica vera speranza è quella di trovare utenti,piu' idioti di loro:)
Questa è una curiosita da unire al network delle Litigation di ACC,ed è il loro Provider o ISP o DNS e la posizione è rilevata in automatico da SEP 2019 e per Fastly,l'impegno è irrisorio,perche' sono presenti dati talmente scarsi,da non richiedere nessuna verifica,tramite il proprio ISP,rispetto all'Affidabilita degli Autori:) Cioe' non esiste nessuna Preoccupazione per l'High Fail Rate dei DNS,perche' non esiste nessuna possibilita di arrivare alla verifica e quindi diventa inutile anche conoscere l'Affidabilita' degli autori,tramite i loro ISP:) (se gli autori avessero modificato i loro contenuti,visti i dati che hanno,significa solo che sono piu' idioti del previsto:)
219 PUB 49% UN 1278 AV 92 Internal Links Average 1088 ms (millesimi di secondo) Average Loading 125 KB AV Full Size.
279882 VOL VS 27,375 MB Full SIZE.
51% DUP VS 120 TLP
51% DUP. 145824 Vol. Termini Eliminati
VS
137143 VOL. Immune e 626 è il suo Average e cioe' è molto vicino ai Thin Content
VS
VS 26280 Total Links VS 20148 Internal Links VS 238,272 secondi Loading Time Full Size
Questi sono i rapporti veri nel contesto piu' ottimista:il volume rimasto immune dai Match (137143 Keywords) deve sostenere 26280 TLP e la posizione è quella di Progress e occorre ricordare che è un Custom CMS (è una piattaforma a pagamento) e da questa posizione è possibile proseguire attraverso la Logica unita ai Dati Veri :) Gli utenti di Progress hanno tanta disponibilita economica e possono utilizzare le migliori tecnologie,pero' grazie alla lezione di Progress,è facile intuire che non sono capaci di fare alcuna differenza,rispetto ai Dati Veri:)
244 PUB 58% UN 1795 AV 93 ILA 476 KB AV Size 106 ms AV Loading
42% DUP VS 120 TLP
437980 VOL. VS 117,608 MB Full SIZE
42% DUP. 183951 VOL. Eliminato
VS
254029 Volume Immune e 1041 è il suo Average
VS
VS 29280 TLP VS 22629 Internal Links
127 PUB 41% UN 1853 AV 390 ms AV Loading 76 ILA 192 KB AV Size
235331 Vol VS 24,384 MB Full Size
59% DUP. 138845 VOL. Eliminato
VS
96486 VOL. Immune e 759 è il suo Average
VS
10160 TLP Complete VS 9652 Internal Links VS 49,530 secondi Loading Time Full Size
 212 PUB 70% UN 2678 AV 97 Internal Link Average (ILA) FULL SIZE 129 KB AV (196 ms AV Loading)567736 VOL VS 27,348 MB Full SIZE30% DUP VS 114 TLP
212 PUB 70% UN 2678 AV 97 Internal Link Average (ILA) FULL SIZE 129 KB AV (196 ms AV Loading)567736 VOL VS 27,348 MB Full SIZE30% DUP VS 114 TLP 30% DUP 170320 VOL. Eliminato
VS
397416 VOL. Immune e 1874 è il suo Average
Naturalmente i dati sistemati sono uniti all'Ottimismo del Report,perche' esiste l'ipotesi di non aver avuto nessun Match in precedenza e occorre anche aggiungere che tutti i dati debbono possedere il Long Standing Webmaster Guidelines (per MOZ è un po' difficile averla:) e in questa posizione,l'elemento piu' importante da ricordare è il Taken Against Content Generally,semplicemente perche' i contenuti non vengono eliminati solo dai conflitti interni ai domini,ma sono i Match globali a determinare i Dati Veri e l'unico problema è quello di Arrivarci e l'unicita interna ai domini,permette di farlo,naturalmente se non esistono anche altre violazioni:)
Queste posizioni non sono all'interno del report e quindi è facile comprendere quanto siano ottimisti i suoi dati,pero' in compenso esistono delle ottime indicazioni,rispetto alle posizioni citate e sono proprio quelle appena sistemate:)
397416 VOL. Immune e 1874 è il suo Average
VS
VS 24168 TLP Complete VS 20564 Internal Links tutto in Full Size
Occorre ricordare che nel volume delle Keywords per MOZ sono presenti anche i commenti e non è possibile quantificarli,pero esistono e ovviamente sono scritti dopo aver letto i contenuti e quindi in teoria sarebbe piu' semplice diversificare i periodi,ed evitare i Match:)
Comunque,anche ipotizzando che il Volume sia realmente tutto scritto dagli autori originali di MOZ,sono presenti lo stesso 24168 TLP,ed essendo il dominio un FULL SIZE,non esistono posizioni strutturali ad avere i Links e quindi possono essere solo all'interno dei contenuti,oppure sistemati nei Common Content e sono formati da termini effettivi anche loro e partecipano ai volumi delle selezioni e se dovessero possedere dei links anche loro fanno parte dei calcoli uniti ai TLP.
Quindi avendo questi dati (24168 TLP per 397K termini) è facile avere anche i "reports mancanti" e ad esempio potrebbero essere anche quelli del Taken Against Content Generally (è la Fundamental Search:) perche' nei dati sopra,esiste il Brain effettivo degli operatori (MOZ nel Caso specifico:),perche' i Duplicati possono esistere e l'unica possibilita' è quella di cercare di farne il numero minore possibile,mentre i TLP sono sistemati dagli autori stessi,immaginando che sia una strategia efficace per arrivare ai Dati Veri:)
Nella realta,l'unica strategia reale per arrivare ai Dati Veri è quella dell'Original;Unique e Content Value e se dovessero esistere,è oggettivamente impossibile trovare la presenza di un numero elevato di TLP,perche' indicano la Qualita del Brain degli autori stessi:) Quelli pieni di Spam hanno Content Scarsi e tanti TLP e grazie a questa unione è possibile conoscere in anticipo tutte le altre posizioni mancanti,senza la necessita di conoscere i reports oggettivi:)
Alla posizione descritta,occorre anche aggiungere il Plus dell'Ottimismo,perche' il report sistemato ha come riferimento 1 solo dominio e poi esiste anche la posizione sopra e la sua importanza è molto semplice,perche' la Variante dei Duplicati è sicura (con 137 Subdomain l'ottimismo è anche nel report dell'unicita,perche' quello effettivo è di sicuro molto peggio:),mentre restano stabili i TLP e peggiora solo il rapporto rispetto ai contenuti rimasti immuni:)
Il Provider o ISP di MOZ è Cloudflare,ed è uno dei piu' importanti del settore,pero' non significa NULLA,rispetto ai Dati Veri:) Visti i dati effettivi di MOZ,non occorre verificare il suo Provider per l'High Fail Rate dei DNS,semplicemente perche' le possibilita' reali di Arrivarci sono molto scarse,solo grazie ai Duplicati,senza nessuna necessita di unire anche l'Elsewhere attraverso i Subdomain:)
Esiste poi questa posizione,ed è quella preferita da MOZ,grazie ai suoi "proverbiali Inbound Links":) I Dati specifici vanno sempre "utilizzati con molta cautela",perche' nessun Tool dell'intero contesto online,conosce realmente i Dati Veri:)
Quindi la cautela è d'obbligo,perche' nei links è sistemato di tutto,senza conoscere i valori reali dei domini che effettuano le segnalazioni:)
Fatta questa premessa,i dati dei backlinks esistono e visti i dati di MOZ,occorre aumentare la Cautela,perche' non è oggettivamente credibile che esista "una massa d'idioti cosi elevata",perche' alcuni domini,di sicuro hanno anche dei Content Validi e per averli è indispensabile Tanto EFFORT e quindi non è assolutamente credibile,sistemare tanti links in DOFOLLOW nei confronti di MOZ,perche' le probabilita' sono molto elevate,rispetto al ritorno dei links nei domini che hanno fatto le segnalazioni e quando avviene questo percorso (i links che tornano indietro:) il contesto per i furbi operatori (immaginano di avere dei vantaggi da MOZ:) diventa molto negativo,naturalmente se dovessero esistere Content Validi realmente e visto il grafico sopra,è molto difficile solo da immaginare,perche' tutti i collegamenti sopra possono essere fatti solo quando non esiste nessun EFFORT da parte del dominio segnalatore:) Potrebbero essere i domini dedicati alla Letteratura creati a ZERO EFFORT,grazie ai contenuti di altri autori,oppure gli spazi dedicati allo Scraping e cioe' non richiedono nessun impegno effettivo e quindi è possibile avere anche la "montagna di segnalazioni sistemata sopra" e nonostante i suoi numeri,non è assolutamente capace di arrivare ai Dati Veri,semplicemente perche' non è compatibile con la Credibility delle operazioni stesse:)
Occorre possedere il Demonstrate Juice Data Archive e cioe' le Proposte Complessive per avere valore e quindi la Credibility delle operazioni sono a ZERO:)
Dopo aver fatto le segnalazioni,non possono essere rimosse (è il senso del LOST sistemato sopra) perche' sono presenti nelle Strutture Data e se fosse reale l'operazione sopra,significa essere in Mismatch rispetto alle proprie Strutture Data,ed è la peggiore violazione possibile,perche' è implicita l'Idiozia Totale dell'autore,grazie al fatto che per avere Mismatch,significa che i contenuti in precedenza sono stati Validi,altrimenti non esisterebbe nemmeno il Mismatch e per arrivarci,uno dei percorsi è quello sistemato sopra:) Probabilmente l'autore immaginava di avere dei vantaggi,tramite le segnalazioni per MOZ e poi si è Rinsavito e si è accorto della cazzata che ha fatto (tutte le segnalazioni sono esclusivamente CAZZATE:) e il LOST sistemato sopra significa proprio questo:)
Se dovessero esistere errori,oppure segnalazioni sbagliate,è meglio non modificare nulla e per evitare tutto il contesto,la migliore soluzione è quella del FRAME GLOBAL LIMIT,ad iniziare dal contesto in cui è nato,perche' FGL deriva proprio dai Links JUICE,ed è sufficente solo la LOGICA,per evitare tutte le strategie vane,rispetto all'Original;Unique e Content Value e cioe' l'unica posizione unita ai Dati Veri:)

222 PUB 56% UN 1568 AV 146 Internal Links Average (ILA) Full SIZE 363 KB in Average (904 ms AV Loading)
2248 Skipped e 2225 sono stati i Disallow
348096 VOL. VS 80,586 MB VS 171 TLP
44% DUP 153162 VOL. Eliminato VS
194934 VOL. IMMUNE e 878 è il suo Average
VS
37962 TLP VS 32412 ILA
 Advance Web Ranking 250 PUB 78% UN 2158 AV 40 ILA FULL SIZE 709 KB AV (292 ms AV Loading)539500 VOL. VS 177,250 MB Full SIZE22% DUP VS 59 TLP
Advance Web Ranking 250 PUB 78% UN 2158 AV 40 ILA FULL SIZE 709 KB AV (292 ms AV Loading)539500 VOL. VS 177,250 MB Full SIZE22% DUP VS 59 TLP22% DUP 118690 VOL. Eliminato
420810 VOL. Immune e 1683 è il suo Average
VS
10000 Internal Links VS 14750 Total Links Page (TLP) Full Size
 Web FX 244 PUB 68% UN 4083 AV 176 ILA Full SIZE 1084 KB AV (260 ms AV Loading)32% DUP. VS 191 TLP 996252 VOL. VS 264,496 MB Full SIZE
Web FX 244 PUB 68% UN 4083 AV 176 ILA Full SIZE 1084 KB AV (260 ms AV Loading)32% DUP. VS 191 TLP 996252 VOL. VS 264,496 MB Full SIZE32% DUP 318800 Termini Eliminati
VS
677452 VOL. Immune e 2776 è il suo Average
VS
46604 Total Links (TLP) VS 42944 Internal Links (ILA) Full Size
 244 PUB 27% UN 1723 AV 385 ILA FULL SIZE 571 KB AV (555 ms AV Loading)420412 VOL. VS 139,324 MB Full SIZE73% DUP VS 402 TLP 73% DUP 306900 VOL. EliminatoVS113512 VOL. Immune e 465 è l'Average e quindi è pieno Thin Content per questa selezione del simpatico Forbes:) VS93940 Internal Links (ILA) VS 98088 TLP Questi sono i Links che dovrebbe sostenere il volume rimasto immune dai Match e il contesto è il piu' Ottimista:)
244 PUB 27% UN 1723 AV 385 ILA FULL SIZE 571 KB AV (555 ms AV Loading)420412 VOL. VS 139,324 MB Full SIZE73% DUP VS 402 TLP 73% DUP 306900 VOL. EliminatoVS113512 VOL. Immune e 465 è l'Average e quindi è pieno Thin Content per questa selezione del simpatico Forbes:) VS93940 Internal Links (ILA) VS 98088 TLP Questi sono i Links che dovrebbe sostenere il volume rimasto immune dai Match e il contesto è il piu' Ottimista:) 242 PUB 77% UN 287 KB AV SIZE 720 ms AV Loading 3749 AV Keywords 48 ILA
242 PUB 77% UN 287 KB AV SIZE 720 ms AV Loading 3749 AV Keywords 48 ILA
907258 VOL. VS 69,454 MB FULL SIZE
23% DUP 208669 VOL. Eliminato
VS
698589 VOL. Immune e 2886 è il suo Average
VS
11616 Internal Links VS 17182 Total Links Full Size
 Investopedia 231 PUB 71% UN 2719 AV 169 ILA FULL SIZE 528 KB AV (398 ms AV Loading)29% DUP. VS 188 TLP 628089 VOL. VS 121,968 MB Full SIZE
Investopedia 231 PUB 71% UN 2719 AV 169 ILA FULL SIZE 528 KB AV (398 ms AV Loading)29% DUP. VS 188 TLP 628089 VOL. VS 121,968 MB Full SIZE
29% DUP 182145 VOL. Eliminato
VS
454944 VOL. Immune e 1930 è il suo Average
VS
39039 Internal Links VS 43428 Total Links (interni + esterni al dominio) Full Size
 183 PUB 81% UN 1873 AV 54 Internal Links Page (Average ILA) 1033 ms AV Loading
183 PUB 81% UN 1873 AV 54 Internal Links Page (Average ILA) 1033 ms AV Loading342759 VOL. VS 17,202 MB Full Size
19% DUP 65124 Termini Eliminati
VS
277635 VOL. Immune e 1517 è il suo Average
VS
9882 Internal Links VS 12627 Total Links Page FULL SIZE
 237 PUB 46% UN 8667 AV 228 ILA FULL SIZE 641 KB (455 ms AV Loading)
237 PUB 46% UN 8667 AV 228 ILA FULL SIZE 641 KB (455 ms AV Loading)
54% DUP. VS 245 TLP2054079 VOL. VS 151,917 MB54% DUP 1109202 VOL. EliminatoVS944877 VOL. Immune e 3986 è il suo AverageVS54036 Internal Links VS 58065 Total Links Full Size  238 PUB 65% UN 1820 AV 108 ILA FULL SIZE 242 KB AV (234 ms AV Loading)
238 PUB 65% UN 1820 AV 108 ILA FULL SIZE 242 KB AV (234 ms AV Loading)
35% DUP VS 119 TLP 433160 VOL. VS 57,596 MB Full SIZE35% DUP 151606 VOL. EliminatoVS281554 VOL. Immune e 1183 è il suo AverageI dati hanno come riferimento solo una selezione,pero' sono importanti lo stesso,perche' i volumi delle pubblicazioni sono quelli effettivi;i Match esistono realmente e nel contesto online effettivo hanno solo la possibilita di essere peggiori,perche' le pubblicazioni selezionate hanno un numero assai maggiore e se fosse il dominio specifico,avere 238 pubblicazioni in 1 sola selezione diventa un ottima indicazione su quali sono i Dati Veri anche nel contesto online effettivo,ed è facile prevederli:è sufficente sistemare il volume rimasto Immune (281554 Keywords) e unirli al rapporto sotto:VS25704 Internal Links VS 28322 Total Links Full SizeAnche queste posizioni sono vere e se non esistesse nessun altra violazione,significa avere oltre il 50% in Anchor Text,rispetto ai contenuti rimasti immuni e attraverso questo dato è possibile conoscere anche il Brain degli autori,ed è molto difficile solo immaginare che i reports del contesto online effettivo possano essere migliori:)Se dovesse esistere "qualche dubbio",è sufficente vedere i SIZE (57,596 MB per l'intera selezione:) e anche se non dovesse esistere nessun Match,comprese tutte le verifiche precedenti;anche se dovessero esistere presenze di TLP ragionevoli (significa al massimo avere il 20% negli Anchor Text:) avere 57,596 MB per 433K Keywords,significa possedere l'imbarazzo nella scelta delle possibili violazioni (i primi sono i tantissimi collegamenti Unnatural e cioe' i Link Building,insieme a tutte le strategie degli operatori SEV:) perche' 57 MB è capace di contenere quasi 5 volte tutta la Summa Theologica insieme alla sua Appendice e quest'ultima da sola ha quasi le dimensioni di tutta la selezione di Grammarly e occorre ricordare che anche la Summa ha i suoi codici,pero' solo quelli che servono realmente,mentre tutto il resto fa' parte solo delle strategie per arrivare al NULLA:)La posizione descritta è quella piu' Ottimista e per tornare alla realta' è sufficente ricordare che i SIZE sono quelli VERI;i volumi delel Keywords sono quelli VERI;i Match esistono e sono Veri anche i Total Links Page:433160 Keywords (151606 eliminate) VS 57 MB VS 28322 TLP e anche togliendo le Keywords eliminate,è un rapporto del tutto opposto alla Logica dei Dati Veri:)Il rapporto dei dati sistemati,non è nemmeno definitivo,perche' è in realta realizzato "dall'Ottimismo Ordinario" ed è quello di avere 1 solo dominio,a cui unire i dati:)Esiste poi il Plus dell'Ottimismo,rispetto ai rapporti dei dati sistemati,perche' non è calcolato l'eventuale presenza dell'Elsewhere unito ai Duplicati e per il dominio Grammarly esiste "l'imbarazzo della scelta",grazie al fatto che sono centinaia i suoi Subdomain,uniti allo spazio principale:)
Nel DNS,il Provider di Grammarly è Amazon e quindi è inutile avere la Grande Preoccupazione dell'High Fail Rate,perche' è oggettivamente difficile anche Fallire nel Rate,grazie al fatto che è indispensabile prima Arrivarci,ed è possibile farlo solo attraverso il Demonstrate Juice Data Archive e cioe' sono le Proposte Complessive che permettono di arrivare all'High Fail Rate:)Non sono le posizioni dei Backlinks a permettere di arrivare all'High Fail Rate e occorre ricordare che i numeri dei links vanno "analizzati sempre con cautela",sopratutto quando esistono il numero di DOFOLLOW sistemato sopra:)Sembrano davvero i Followers della Terra Piatta (probabilmente il Brain dei segnalatori è allo stesso livello:) e seguendo sempre "la cautela dell'analisi" è possibile esprimere un giudizio oggettivo sul Brain dei segnalatori,ed è sistemato nell'evidenza di JULY 2024 e cioe' di 1 anno fa' ,perche' in quel periodo i backlinks per Grammarly erano formati da 15 Million e queste posizioni "non sono delle borse valori" e quando scendono i links (sono passati da 15 Million a 3,5 Million in 1 anno) significa semplicemente che "gli astuti segnalatori" si sono accorti del danno per i loro domini,sistemando dei collegamenti in DOFOLLOW per Grammarly e per arrivare alle differenze sistemate sopra,hanno semplicemente Modificato i Links e cioe' le loro Strutture Data,ed è una Grave Violazione.Per rimediare agli errori nei collegamenti,esiste 1 sola possibilita,ed è quello di Pensarci Prima di Farli,perche' non esiste nessuna possibilita di Rimediare ai Mismatch e questo hanno fatto i segnalatori di Grammarly:)Naturalmente "la cautela dell'analisi" va applicata anche ai domini dei segnalatori,perche' è decisamente poco Credibile che esistano 15 Million di collegamenti,uniti a 65K domini (era il dato di 1 anno fa),tutti con Content Validi e quindi la Grave Violazione dei Mismatch è difficile da trovare,perche' coloro che fanno queste operazioni,hanno gia dei Content scarsi a loro volta,altrimenti nemmeno con un "bazooka puntato alla tempia" è possibile dare un vantaggio a Grammarly:)
Questi sono i Lost di Grammarly e rispetto ai Dati Veri non significano assolutamente nulla e servono solo per rendere semplice l'applicazione della LOGICA ai Dati Veri stessi:)I Lost sono in realta i links che "gli astuti segnalatori" hanno eliminato dalle loro Strutture Data e per fare queste operazioni significa che gli autori specifici sono idioti a 360°:la prima Idiozia è quella di fare la segnalazione per Grammarly in DOFOLLOW e poi hanno aggiunto il LOST e non è la perdita dei Links "per cause ignote",ma semplicemente gli "astuti segnalatori" hanno modificato le loro Strutture Data e in questo modo l'Idiozia è Totale:)L'importanza di questa posizione non sono i numeri sistemati,ma è il valore dei Dati Veri ad essere realmente importante,ed è sufficente solo immaginare se esistessero le posizioni opposte (i Dofollow e i Lost sistemati sopra:) per avere la certificazione della sua importanza:)
Le posizioni da unire ai Dati Veri sono le Quality Guidelines e tutti i numeri uniti ai Backlinks,compresi i Lost hanno un unico riferimento,ed è quello degli Schemes e non esiste dubbio che sia vero e sia anche l'unica vera operazione compiuta "dagli astuti segnalatori":) 
JULY 2025 Site Skipped Status Code 403 


Science Fiction 247 PUB 91% UN 2994 AV 157 ILA Full Size 46 KB AV (210 ms AV Loading)
9% DUP VS 165 TLP 739518 VOL VS 11,362 MB Full Size9% DUP. 66556 Vol. Eliminato
VS
672962 VOL. Immune e 2724 è il suo Average
VS
38779 Internal Links VS 40775 Total Links Full Size
225 PUB 38% UN 3118 AV 59 KB AV Size 77 ms AV Loading 131 ILA AV Internal Links 701550 VOL VS 13,275 MB Full Size62% DUP VS 131 TLP 62% DUP 434961 Vol. Eliminato (130526 è stato il volume eliminato a JUN 2025)VS266589 VOL. Immune e 1184 è il suo AverageVS29475 Internal Links VS 34875 Total Links e a sostenerli dovrebbe essere il Volume Immune formato da 266K Keywords,ed è il contesto piu' ottimista rispetto a qualsiasi altro reports.https://keywordtdarchive.blogspot.com/p/sistemi.html
Hadoop arriva dalle pubblicazioni dedicate alle Big Data e il contesto è molto Divertente,rispetto a contenuti scritti diversi anni fa',perche' il problema principale delle Big Data è quello di conoscere i Dati Veri:)
Wikidata 247 PUB 55% UN 914 AV 107 Average Internal Links 147 KB AV Size 395 ms AV Loading.
2858 Skipped e 2752 sono stati i Disallow 225758 VOL. VS 36,309 MB FULL SIZE45% DUP VS 140 TLP45% DUP 101591 VOL. Eliminato VS124167 VOL. Immune e 502 è il suo Average e quindi per la simpatica Wikidata,esiste il Thin Content Esatto:)VS26429 Internal Links VS 34580 Total LinksQuesti sono i Links che dovrebbe sostenere il volume immune di Wikidata :https://dinpoststory.blogspot.com/p/main-contest-wiki-nonsense-data.html
Questa è la pagina dedicata al Nonsense Data di Wikimedia e tra di essi esistono anche le posizioni degli EDITS,applicati anche ai Links e cioe' Wikimedia,sempre Motu Proprio,applica il Lost sistemato sopra e cioe' Modifica anche i Links,oltre ai Size,attraverso il Prose e i Contenuti stessi:) Il termine Nonsense applicato a Wikimedia è molto Divertente,perche' è LEI stessa a sistemarlo nelle "sue linee guida completamente storte" e il Nonsense per Wiki ha come riferimento proprio i suoi contenuti,ed è difficle comprenderne la ragione,perche' in 10 anni di Esperienza,non ho ricordato mai 1 solo contenuto originale di Wikimedia,rispetto a qualsiasi suo dominio e quindi l'unica ragione per cui puo esistere il Nonsense su Wikimedia,sono le sue operazioni stesse:)Oltre alla "cautela delle analisi",in questa posizione è possibile sistemare tutto il Nonsense Data di Wikimedia,perche' esiste "la sua operazione prediletta" e operativamente la definiscono LOST (sono i backlinks persi:) mentre "nell'ottica di wikimedia" la stessa operazione viene definita EDITS e nella posizione sopra,esistono davvero tantissime modifiche,rispetto solo a 1 anno fa':sono passati da quasi 200 Million di Backlinks a circa 66 Million e oltre il 95% è in DOFOLLOW:)Per giustificare queste operazioni è utilissimo il Nonsense di Wikimedia,perche' le operazioni sono completamente separate dalla LOGICA rispetto ai Dati Veri,ed è talmente elevata la distanza,da rendere utile anche la posizione sopra,per comprendere la Logica stessa dei Dati Veri:)
https://dinpoststory.blogspot.com/2025/04/patent-effort-unique-compliance-logical.html
Questo è solo un esempio molto pertinente rispetto all'utilizzo anche dei LOST e cioe' degli EDITS applicati anche ai Backlinks,naturalmente ipotizzando che esistano anche dei Content Validi,altrimenti la presenza o assenza degli EDITS o dei LOST,non serve assolutamente a NULLA:)E' la Mancata Compliance rispetto alle Strutture in Generale,comprese anche le Guidelines e la prima violazione sono sempre i Duplicati:)E' facilissimo comprendere quanto siano elevate le differenze tra i Dati VERI e il loro opposto,ad iniziare dal fatto che per i Dati Falsi non esiste nemmeno la Credibility dell'Idiozia rispetto alle operazioni fatte,perche' sono palesemente solo degli Schemes e il paradosso è unito al fatto che è molto difficile solo Arrivarci,perche' prima di fare Schemes è indispensabile avere Content Validi,ed è molto difficile trovarli nei domini degli autori che fanno le segnalazioni in Dofollow per Wikidata:) 


234 PUB 94% UN 5172 AV 217 ILA Internal Links Average) Full Size 135 KB AV 385 ms è stato l'Average del Loading.5869 Skipped e 5852 sono stati i Disallow
6% DUP VS 286 TLP
8% DUP 72614 volume eliminato
VS
50778 Internal Links VS 66924 Total Links




233 PUB 71% UN 992 AV 82 ILA4271 Skipped e 4246 sono stati i Disallow Full Size 47 KB AV (260 ms AVL)231136 VOL. VS 10,951 MB Full SIZE29% DUP. VS 96 TLP29% DUP 67029 VOL. EliminatoVS164107 VOL. Immune e 704 è il suo AverageVS19106 Internal Links VS 22368 Total Links Full Size 

WIKI IT 200 PUB 87% UN 3432 AV 246 ILA 3246 sono stati gli skipped e 3143 sono stati i Disallow Full SIZE 176 KB AV (398 ms AVL)686400 VOL. VS 35,200 MB Full Size 13% DUP VS 364 TLP.
13% DUP 89232 Vol. Eliminato
VS
597168 VOL. Immune 2985 Average
VS
49200 Internal Links VS 72800 Total Links Full Size


Wiki Cebuana 195 PUB 48% UN 931 AV 103 ILA (Internal Links Average) Full Size 105 KB AV 435 ms .Skipped 4564 e 4441 sono stati i Disallow,in 1 sola selezione:)181545 VOL VS 20,475 MB Full Size52% DUP VS 220 TLP )52% DUP 94403 Termini Eliminati
VS
87142 VOL. Immune e 446 è il suo Average e quindi grazie a Wiki Cebuana,è pieno Thin Content:)
VS
20085 Internal Links VS 42900 Total Links Full Size
OK


Wiki France 245 PUB 82% UN 3272 AV 225 ILA 1811 Skipped e 1806 sono stati i Disallow Full SIZE 163 KB AV (390 ms AVL)801640 VOL. VS 39,935 MB Full Size18% DUP. VS 308 TLP 18% DUP 114295 Vol. Eliminato
VS
687345 VOL. Immune 2805 Average
VS
55125 Internal Links VS 75460 Total Links Full Size
230 PUB 87% UN 2798 AV 311 ms AV Loading 230 Internal Links Average 157 KB AV SIZE
2117 skipped e 2097 Disallow
643540 VOL VS 36,110 MB Full SIZE. 13% DUP VS 331 TLP
DUP 13% 83660 VOL. Eliminato VS
559880 VOL. Immune 2434 Average
VS
52900 Internal Links VS 76130 Total Links Full Size


Wiki Global 238 PUB 81% UN 5568 AV 652 Internal Links Average 1722 Skipped e 1710 Disallow Full SIZE 275 KB AV (270 ms AVL)
1325184 VOL. VS 65,450 MB Full SIZE19% DUP VS 773 TLP19% DUP 251784 VOL Eliminato VS1073400 4510 AVVS155176 Internal Links VS 183974 Total Links Full SizeOccorre sempre ricordare la relativita' dei domini Wikimedia,unita al Super Ottimismo del report:)Se fossero applicati gli Average effettivi,solo quello della selezione di JULY 2025 per Wiki EN,è formato da quasi 1/3 rispetto all'Average generale della selezione e occorre sempre ricordare queste posizioni,perche' negli Average effettivi esistono i contenuti che hanno effettivamente scritto gli autori Wikipediani,a parte poi gli EDITS che hanno fatto:)Questo è l'Average Generale di tutto il dominio di Wiki EN e secondo i dati ufficiali,ogni pubblicazione ha 20,40 EDITS :)Qui è sistemata la pagina dei dati piu' recenti di Wiki ENEsistono 3 evidenze:il numero di pubblicazioni;quello dei termini e non è specificato la presenza del PROSE o Meno ,ed esiste anche il numero degli EDITS,insieme al loro Average:)E' sufficente vedere i dati e si comprende facilmente quanto sono ottimisti quelli uniti alla selezione di JULY 2025 per Wiki EN,semplicemente perche' sono utilizzati tutti i termini effettivi presenti in 1 pagina,compresi i loro EDITS (senza considerare le pubblicazioni in Disallow ne sono oltre 7000 per la selezioni di WIKI EN nel suo JULY 2025:) e poi esiste anche il Plus dell'ottimismo nei reports,perche' gli EDITS dichiarati da Wikimedia hanno come riferimento solo il PROSE e cioe' i contenuti che hanno scritto effettivamente gli autori wikipediani e non esiste nessun dato per gli altri termini presenti e per forza di cose sono piu' importanti dei PROSE,perche' ad essere ottimisti,quasi sempre hanno dimensioni maggiori del doppio,rispetto a quelle dei Prose e quindi degli EDITS:)
L'ottimismo dei dati citati sopra,arriva in questa posizione:)L'arco temporale è formato da 1 anno:sono presenti NOFOLLOW;esistono le immagini negli Anchor Text;esiste solo la presenza del dominio e poi è presente l'evidenza massima raggiunta dai LOST e cioe' i segnalatori che hanno Modificato il vantaggio fornito a WIKI EN,ovviamente allo scopo di avere Vantaggi in Proprio:) (attraverso i numeri di Wikimedia,nemmeno i Kamikaze e Followers della Terra Piatta,sistemerebbero delle segnalazioni per Wikimedia:)
In questa posizione sono presenti i LOST sempre in 1 anno,pero' uniti ai DOFOLLOW e l'Anchor Text sono sempre le immagini e sono presenti solo i Domini:)Si passa da 400K a oltre 7 Million (ho evidenziato solo la punta massima degli EDITS:),per dare un vantaggio al dominio Wiki EN,rispetto ai dati sistemati sopra:)
Sempre in 1 anno,uniti ai Dofollow e ai soli domini,esiste anche la punta massima,attraverso gli Anchor Text e cioe' i termini effettivi uniti ai Links e tra l'altro sarebbero anche gli unici a fornire valore reale:)Si passa da 400K nei NOFOLLOW come punta massima dei LOST,ai 7 Million delle immagini,pero' in Dofollow e si arriva a 86 MILLION attraverso la punta massima dei LOST e cioe' degli EDITS,sempre in 1 anno,unita ai domini e ai links in Dofollow:)
Questa è l'ultima posizione prelevata e indirettamente è presente la LOGICA dei DATI VERI,perche' esiste il contesto piu' Demenziale possibile,rispetto alla LOGICA stessa delle operazioni:)Sono presenti tutte le tipologie dei Links,pero' solo i Text e cioe' i termini effettivi possono creare valore e per averlo,occorre conoscere le Proposte Complessive e sopratutto è indispensabile il DEMONSTRATE e cioe' Come ci sono Arrivati "gli astuti autori" alle Proposte Complessive stesse:) Sono le Quality Guidelines unite al Comprehensive Amount e in questa posizione è utilissimo Ricordarle:cioe' un autore,dopo tutto il suo EFFORT nella creazione dei Content,ipotizzando che abbiano anche valore,ad iniziare dal numero minore possibile dei Duplicati,ha l'Obbligo di Dimostrare che la "montagna di Dofollow sistemata sopra",applicata a tutti gli Anchor Text;ai Domain e ai loro Subdomain,sia VERA:)Solo la sistemazione del LOST e cioe' degli EDITS,indica esattamente il contrario (la punta massima del LOST è formata da 96 Millions di modifiche:) e i numeri vanno presi sempre con cautela,perche' lo strumento registra solo le presenze oggettive,pero' non conosce i valori reali dei singoli domini che hanno fatto le segnalazioni e nello stesso tempo,non è capace di Applicare la Logica dei Dati Veri,perche' non esiste proprio nessuna CREDIBILITY rispetto alle operazioni fatte da 96 MILLIONS "di poveri autori":)Occorre ricordare che è la punta massima dei LOST e cioe' dei Backlinks che "i poveri autori" hanno Modificato,all'interno delle loro Strutture Data e quindi,solo utilizzando la LOGICA,è facile determinare lo scarso valore dei Content collegati,insieme allo scarso EFFORT per crearli,perche' solo queste posizioni sono capaci di giustificare la demenza delle operazioni;)


Wiki ES 225 PUB 89% UN 4314 AV 237 ILA Full SIZE 187 KB AV (381 ms AVL) Skipped 2319 e 2237 sono stati i Disallow.
970650 VOL. VS 42,075 MB Full Size11% DUP. VS 388 TLP11% DUP 106771 VOL. Eliminato VS863879 VOL. Immune e 3839 è il suo AverageVS53325 Internal Links VS 87300 Total Links Full Size 246 PUB 60% UN 1975 AV 138 ILA Full SIZE 334 KB (630 ms AVL)485850 VOL. VS 82,164 MB Full Size40% DUP VS 153 TLP40% DUP 194340 VOL. Eliminato VS291510 VOL. Immune 1185 AVVS33948 Internal Links VS 37638 Total Links Full Size
246 PUB 60% UN 1975 AV 138 ILA Full SIZE 334 KB (630 ms AVL)485850 VOL. VS 82,164 MB Full Size40% DUP VS 153 TLP40% DUP 194340 VOL. Eliminato VS291510 VOL. Immune 1185 AVVS33948 Internal Links VS 37638 Total Links Full Size

209 PUB 95% UN 5190 AV 27 ILA Full SIZE 102 KB AV (427 ms AVL)
1084710 VOL VS 21,318 MB Full SIZE
5% DUP VS 30 TLP (Multi Detect Language )
5% DUP 54235 VOL. Eliminato
VS
1030475 VOL. Immune 4930 AV
VS
5643 Internal Links VS 6270 Total Links
 232 PUB 84% UN 2498 AV 11 ILA Full SIZE 124 KB AV (855 ms AVL)579536 VOL. VS 28,768 MB FULL Size16% DUP VS 72 TLP16% DUP 92725 VOL. Eliminato VS486811 VOL. Immune 2098 AVVS2552 Internal Links VS 16704 Total Links Full Size
232 PUB 84% UN 2498 AV 11 ILA Full SIZE 124 KB AV (855 ms AVL)579536 VOL. VS 28,768 MB FULL Size16% DUP VS 72 TLP16% DUP 92725 VOL. Eliminato VS486811 VOL. Immune 2098 AVVS2552 Internal Links VS 16704 Total Links Full Size Enciclopedia Storica Economia136 PUB 66% UN 2471 AV 160 KB AV Size 1478 ms AV Loading 67 ILA AV Internal Links
Enciclopedia Storica Economia136 PUB 66% UN 2471 AV 160 KB AV Size 1478 ms AV Loading 67 ILA AV Internal Links
336056 VOL. VS 21,760 MB Full SIZE
VS
221797 VOL. Immune 1630 AV
VS
9112 Internal Links VS 9384 Total Links
 223 PUB 57% UN 1374 AV 47 ILA Full SIZE 135 KB AV (155 ms AVL)
223 PUB 57% UN 1374 AV 47 ILA Full SIZE 135 KB AV (155 ms AVL)
306402 VOL. VS 30,105 MB Full Size43% DUP VS 51 TLP43% DUP 131752 VOL. Eliminato
VS
174650 Vol. Immune 783 AV
VS
10481 Internal Links VS 11373 Total Links Full Size
U Enciclopedia World History 222 PUB 72% UN 2709 AV 115 ILA Full SIZE 235 KB AV (249 ms AVL)
Enciclopedia World History 222 PUB 72% UN 2709 AV 115 ILA Full SIZE 235 KB AV (249 ms AVL)
601398 VOL. VS 52,170 MB Full Size28% DUP 168391 VOL. Eliminato
VS
433007 VOL. Immune 1950 AV
VS
25530 Internal Links VS 30858 Total Links
Elsevier 244 PUB 73% UN 1148 AV 25 ILA 232 KB FULL SIZE 169 ms AV Loading.
280112 VOL. VS 56,608 FULL SIZE27% DUP VS 45 TLP27% DUP 75630 VOL. Eliminato VS204482 VOL. Immune 838 AVVS6100 Internal Links VS 10980 Total Links Full Size

225 PUB 73% UN 1792 AV 52 ILA 47 KB FULL SIZE 336 ms AV Loading.403200 VOL. VS 10,575 FULL SIZE27% DUP VS 103 TLP27% DUP 108864 VOL. Eliminato
VS
294336 VOL. Immune 1308 AV
VS
11700 Internal Links VS 23175 Total Links Full Size
233 PUB 57% UN 1109 AV 410 ms AV Loading 92 KB AV Size 76 ILA (Average Internal Links)258397 VOL VS 21,436 MB Full Size
43% DUP 111110 VOL. Eliminato
VS
147287 VOL. Immune 632 AV
VS
17708 Internal Links VS 21436 Total Links Full Size
Anche per DOJ occorre unire la cautela nelle posizioni dei Backlinks,perche' qualsiasi Tool online non conosce assolutamente Quali sono i Dati Veri:)
E' una posizione Fundamental nel vero senso delle parole,ad iniziare dal Content Value "degli astuti segnalatori",ed è facile intuire che i loro contenuti "non hanno richiesto un grande impegno" e probabilmente nei Million di Backlinks sistemati sopra ci saranno i simpatici domini della Letteratura (i contenuti appartengono ad altri autori e quindi si possono sistemare segnalazioni in Dofollow con nonchalance:) oppure quelli dedicati allo Scraping o ai generative content e di sicuro saranno presenti anche tutti i contestatori del Trust nelle ricerche,perche' DOJ è diventato "la loro ancora di salvezza" e non per "la violazione del Trust tradizionale",ma per il Brain specifico di DOJ,speculare agli operatori SEV e le posizioni sopra,forniscono un ottima indicazione su come sarebbe il contesto online,se fosse operativo realmente il Brain di DOJ e degli operatori SEV:)
Questo è un esempio pratico e per comprendere cosa sarebbe il contesto online,attraverso il Brain di DOJ e degli operatori SEV (è il fallimento totale:) sono sufficenti i dati sopra:)
A parte le opzioni degli Anchor Text perche' in realta non esistono proprio (solo i termini effettivi possono essere uniti ai links),esistono anche i Subdomain presenti,uniti ai Duplicati e gli autori che effettuano segnalazioni,debbono Dimostrare prima LORO di avere Content Validi,attraverso le Proposte Complessive e per questo motivo esistono solo i termini effettivi da poter unire ai Links,semplicemente perche' le immagini non sono capaci da sole di arrivare alle Proposte Complessive,tranne quando sono inserite nei termini.
Se un autore dovesse fare tutto il percorso per arrivare ai Dati Veri e poi sistema segnalazioni in Dofollow,è indispensabile che esista nella loro testa il Brain di DOJ e degli operatori SEV e grazie a "questo simpatico Brain",è possibile sistemare il LOST e cioe' l'EDITS di segnalazioni in Dofollow pure e forma un contesto in opposizione totale alla Logica dei Dati Veri:)
Naturalmente queste posizioni vanno lette sempre con molta cautela,perche' i Dati Veri e cioe' le Quality Guidelines attraverso il Comprehensive Amount (è la Logica dei Dati Veri) non li conoscono proprio,pero' le posizioni descritte sono operative realmente e cambiano solo i termini:il LOST e cioe' l'EDITS,sono definiti anche Toxic Links (Semrush operatore SEV è un esempio:),pero' sono stati gli operatori a sistemarli nei loro domini,ovviamente sempre in Dofollow,ed è facile comprendere il motivo per cui "le segnalazioni diventano tossiche",perche' in realta sono solo degli Schemes e questo sarebbe il contesto online se esistessero i Brain di DOJ e degli operatori SEV:)
Grazie Holy Grail TFD Google,Glory Tech,di averci salvato da questa Idiozia Totale:)
226 PUB 69% UN 4250 AV 203 KB AV Size 247 ms AV Loading 178 AV Internal Links 218 AV Total Links960500 VOL. VS 45,878 MB
31% DUP 297755 VOL. Eliminato
VS
662745 VOL. Immune 2932 AV
VS
40228 Internal Links VS 49268 Total Links Full Size
140 PUB 57% UN 1270 AV 187 ms AV Loading 130 ILA (Average Internal Links) 79 KB AV Size
177800 VOL VS 11,060 MB Full SIZE
43% DUP VS 151 TLP
43% DUP 76454 VOL. EliminatoVS101346 VOL. Immune 723 AVVS18200 Internal Links VS 21140 Total Links Full Size  173 PUB 74% UN 809 AV 38 ILA (Internal Links Average) Full SIZE 157 KB AV (125 ms AVL)139957 VOL. VS 27,161 MB Full Size26% DUP VS 45 TLP 26% DUP 36388 VOL. Eliminato VS103569 VOL. Immune 598 AVVS6574 Internal Links VS 7785 Total Links Full Size
173 PUB 74% UN 809 AV 38 ILA (Internal Links Average) Full SIZE 157 KB AV (125 ms AVL)139957 VOL. VS 27,161 MB Full Size26% DUP VS 45 TLP 26% DUP 36388 VOL. Eliminato VS103569 VOL. Immune 598 AVVS6574 Internal Links VS 7785 Total Links Full Size

Philpapers 214 PUB 79% UN 5098 AV 308 ILA Full SIZE 143 KB Average (770 ms AVL)
1090972 VOL VS 30,602 MB Full Size21% DUP. 229104 VOL. Eliminato
VS
861868 VOL. Immune 4027 AV
VS
65912 Internal Links VS 70406 Total Links Full Page
W
 Time Magazine 145 PUB 72% UN 1225 AV 48 ILA Full SIZE 228 KB AV (499 ms AVL)
Time Magazine 145 PUB 72% UN 1225 AV 48 ILA Full SIZE 228 KB AV (499 ms AVL)
177625 VOL. VS 33,060 MB Full Size28% DUP VS 67 TLP28% DUP 49735 VOL. Eliminato VS127890 VOL. Immune 882 AVVS6960 Internal Links VS 9715 Total Links Full Size
 OUR World Data Oxford 232 PUB 76% UN 2310 AV 47 ILA 115 KB Full SIZE 291 ms AV Loading
OUR World Data Oxford 232 PUB 76% UN 2310 AV 47 ILA 115 KB Full SIZE 291 ms AV Loading
535920 VOL VS 26,680 MB Full Size24% DUP VS 71 TLP24% DUP 128620 VOL. Eliminato
VS
407300 VOL. Immune 1755 AV
VS
10904 Internal Links VS 15544 Total Links Full Size
Science Software (SCNSOFT) 226 PUB 57% UN 2703 AV 173 ILA FULL SIZE 341 KB AV (418 ms AVL)
610878 VOL VS 77,066 MB Full Size43% DUP VS 187 TLP43% DUP 262677 VOL. Eliminato VS348201 VOL. Immune 1540 AVVS39098 Internal Links VS 42262 Total Links Full Size Enciclopedia Britannica 237 PUB 75% UN 1524 AV 83 ILA FULL SIZE 105 KB AV (456 ms AVL)
Enciclopedia Britannica 237 PUB 75% UN 1524 AV 83 ILA FULL SIZE 105 KB AV (456 ms AVL)
361188 VOL. VS 24,885 MB Full Size25% DUP VS 108 TLP25% DUP. 90297 Vol. Eliminato VS270891 VOL. Immune 1143 AVVS19671 Internal Links VS 25596 Total Links Full Size SEC GOV 202 PUB 75% UN 2599 AV 82 ILA Full SIZE 94 KB AV (765 ms AVL)
SEC GOV 202 PUB 75% UN 2599 AV 82 ILA Full SIZE 94 KB AV (765 ms AVL)
524998 VOL. VS 18,988 MB 25% DUP VS 87 TLP25% DUP 131249 è il volume dei termini eliminati VS393749 VOL. Immune 1949 AVVS16564 Internal Links VS 17574 Total Links Full Size
 221 PUB 96% UN 12924 AV 121 ILA 128 KB AV Size 303 ms AV Loading 124 AV TLP
221 PUB 96% UN 12924 AV 121 ILA 128 KB AV Size 303 ms AV Loading 124 AV TLP 2856204 VOL. VS 37,570 MB Full Size
4% DUP 114248 VOL. Eliminato
VS
2741956 VOL. Immune 12407 AV
VS
26741 Internal Links VS 27404 Total Links Full Size

243 PUB 97% UN 13381 AV 64 ILA 109 KB Full Size Average (896 ms AVL)
3251583 VOL. VS 26,487 MB Full Size
3% DUP VS 79 TLP
3% DUP 95547 VOL: Eliminato VS
3156036 Vol. Immune 12987 AV
VS
15552 Internal Links VS 19197 Total Links Full Size











































































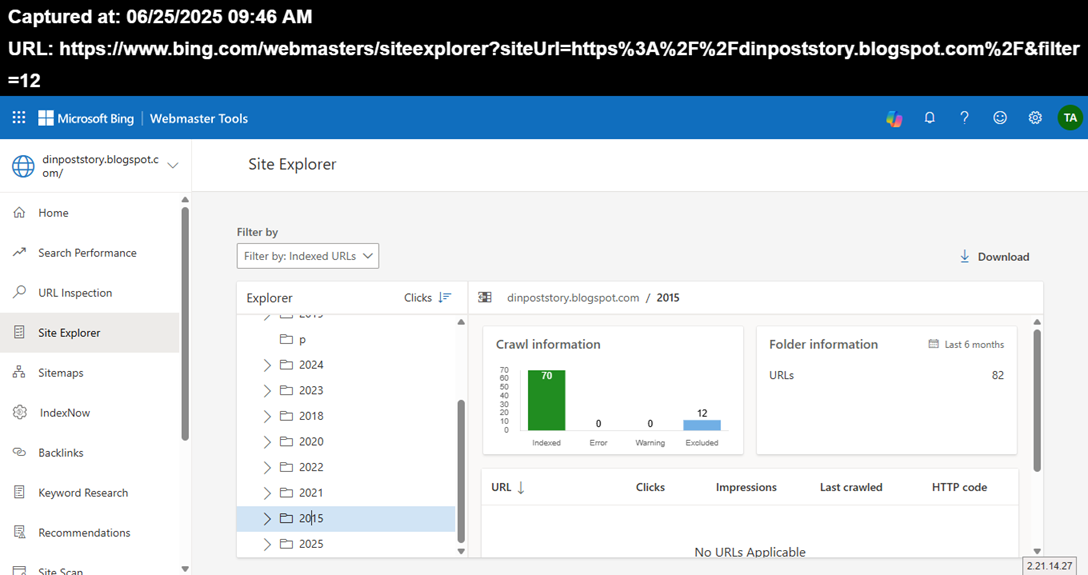





























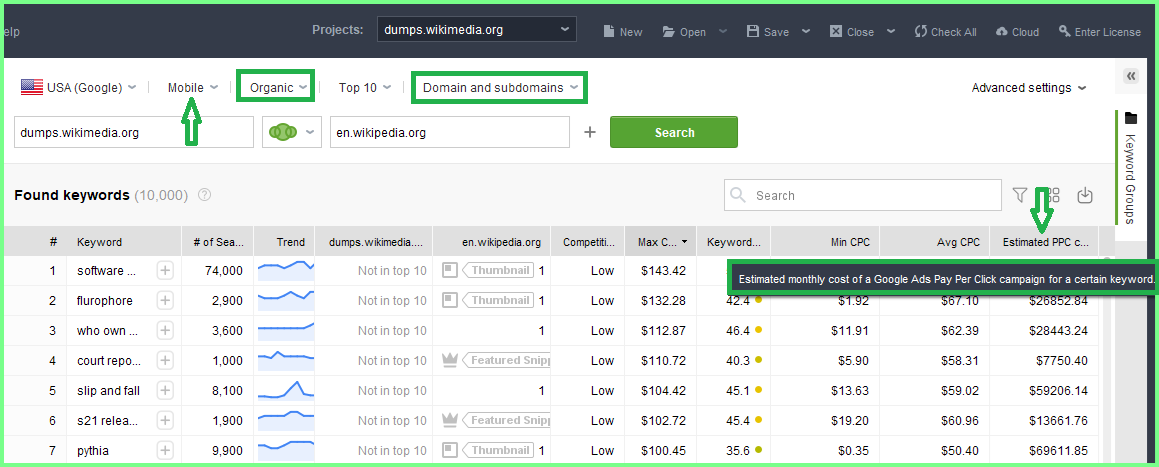



























 Nonostante tutti i limiti sistemati,rispetto al contesto piu' ottimista,i Duplicati esistono lo stesso in gran numero,ed è facile immaginare cosa sarebbero i dati se venissero applicati anche le posizioni dell'Elsewhere,semplicemente perche' i Subdomain esistono e uniti a Semrush,non è possibile "aspettarsi nulla di buono":)
Nonostante tutti i limiti sistemati,rispetto al contesto piu' ottimista,i Duplicati esistono lo stesso in gran numero,ed è facile immaginare cosa sarebbero i dati se venissero applicati anche le posizioni dell'Elsewhere,semplicemente perche' i Subdomain esistono e uniti a Semrush,non è possibile "aspettarsi nulla di buono":)