La pagina A del 71° RF, ha tante posizioni da sistemare per la pubblicazione specifica del Contest Level Absolute e poi ne sono "arrivate anche altre" ,in maniera inaspettata e numerose pure!:)
Posso anticipare che sono "tutte interessanti" ,ed esiste solo l'imbarazzo della scelta nel collocarle e quindi "ho scelto una via logica" per unirle,ed è il contesto generale stesso del web:)
Sara' il modo migliore per festeggiare il Contest Level Absolute e inizia con i dati oggettivi della pagina A+ e il collegamento è nel logo di Key Page Unit (dopo questa pubblicazione,ci sara' anche il link reciproco nella pagina A+).
Adesso sistemero' le varie posizioni e poi descrivero' la loro unione e posso inserire un altro anticipo e cioe' sara' molto semplice :
Nel contesto tradizionale,inteso in senso generale,tantissimi dati non si conoscono affatto e questa posizione,riguarda anche il contesto descritto sopra:)
E' una posizione molto importante per i contenuti che seguiranno e per il momento è sufficente ricordare "la comparazione della lingua italiana" ,rispetto a tutti gli scritti della storia umana e solo i suoi INDEX formano un volume 15 volte maggiore!:).
Descritto in questo modo,sembra gia' un dato esorbitante,mentre in realta' "la comparazione è avvenuta ai minimi livelli" e il motivo èsemplice,perche' il contesto tradizionale,non ha nessun valore degli INDEX e tra un po',la sua comprensione,sara' piena!:)
Questa è la nuova collocazione di Unnatural Developer e posso assicurare che è solo una sezione rispetto all'originale,perche' esiste anche il nuovo Brain Stone e lo sistemero' tra un po' e in questa posizione posso solo citare la prima unione con il volume degli autori della lingua italiana,perche' i Loro Index ,hanno un unica possibilita' per essere validi e cioe'debbono possedere il Natural Contest completo:) Quindi non deve esistere nessuna delle posizioni citate in Unnatural Developer e nemmeno quelle dei Brain Stone e solo questa posizione,amplifica all'ennesima potenza le differenze con il contesto tradizionale:)
Esistono le Opere Top a confermarlo,ed è sufficente vedere l'originalita' dei periodi,per comprendere quanto possa essere differente le dimensioni dei contenuti della lingua italiana nel contesto online,rispetto a quello tradizionale:)
Per avere 1 Milion di GB in Index,deve esistere per forza l'originalita' e il riferimento è solo la lingua italaina ,mentre tutti gli scritti della storia umana,hanno il riferimento globale:)
 Master Contest è molto utile per qualificare anche i contenuti effettivi del contesto tradizionale e iniziano dal "fattore piu'semplice" e cioe'"gli utenti tradizionali" non conoscono realmente cosa hanno scritto "i celebri autori" e nella parte finale di Master Contest ,esiste l'evidenza oggettiva "dell'Ignore Totale" e cioe' non sono solo gli utenti tradizionali "a ignorare i reali contenuti",ma sono gli stessi autori celebri,a ignorare quello che hanno scritto "i loro colleghi" e sopratutto non hanno nemmeno "Un Idea",rispetto a quello che hanno scritto Loro!:)I dati sono in Master Contest e rispetto al contesto tradizionale,sono sistemati anche i migliori contenuti (sono rari gli autori celebri che hanno dati migliori e in pratica ne esistono solo 2,tratti dal Gotha assoluto della scrittura:) e le posizioni riguardano i singoli domini (cioe' quello che hanno scritto realmente gli autori celebri) e quindi i Match ,sono presenti gia' nelle opere dirette,senza effettuare nessun "Match Globale".(in pratica hanno copiato se stessi gli autori celebri ,ed è difficile immaginare che siano in buonafede,perche' sono alte le percentuali dei Copied e ,spesso sono bassi gli average,sempre all'interno delle stesse singole opere:).Tutto questo ha come riferimento solo le dimensioni della lingua italiana negli Index,semplicemente perche' la loro presenza,non puo avere nessuna delle posizioni descritte in Master Contest:)Quindi il valore effettivo dei contenuti è anche maggiore,rispetto alle descrizioni dei passaggi precedenti (15 volte tutti gli scritti della storia umana,solo per la lingua italiana:) e questa posizione rende molto facile comprendere da cosa nascono i valori del contesto online e a differenza di quello tradizionale,si conosce tutto!:)Sara' molto utile per i contenuti che aggiungero' e prima di farlo,sistemo un altra unione:Questo è il valore reale degli Index e si raggiunge attraverso tutti i passaggi precedenti e debbono poi essere uniti alle proposte complessive di ciascun dominio e formano il Main Content.Dopo aver accertato la sua presenza,è possibile applicare "gli eventuali Copied presenti" e queste posizioni valgono per qualsiasi Detect Languege e "Around the World" ha un senso estremamente semplice e cioe'i Match dei termini sono globali ,rispetto a qualsiasi lingua , siano stati creati i contenuti.Questo è un ottimo esempio per l'applicazione di "Around the World", ed è la lingua Bengali di Wiki (tante volte protagonista) e i Match dei termini sono indifferenti alle lingue e ai caratteri in cui sono scritti i contenuti:)Naturalmente,nell'esempio non ho inserito "un match qualsiasi" ma è Din Post Story e quella sistemata è la prima pubblicazione in lingua Bengali per il dominio di Wiki:)La stessa posizione è valida per tutti i contenuti del Detect Language italiano e i loro Index,hanno gli stessi Match Globali e di conseguenza è ancora piu' semplice comprendere,quanto sono elevate le differenze,rispetto ai dati ufficiali:) Il contesto tradizionale di tutti gli scritti della storia umana,non possiede in realta' nemmeno 1 Match tra i propri Content e quindi è facile comprendere quanto siano elevati i valori opposti e per farlo è possibile utilizzare "anche un piccolo Detect Language",come quello italiano:) (solo per citare la comparazione diretta della lingua Bengali,i suoi contenuti sono realizzati da 250 Milions di autori,contro i 70 Milions italiani:)
Master Contest è molto utile per qualificare anche i contenuti effettivi del contesto tradizionale e iniziano dal "fattore piu'semplice" e cioe'"gli utenti tradizionali" non conoscono realmente cosa hanno scritto "i celebri autori" e nella parte finale di Master Contest ,esiste l'evidenza oggettiva "dell'Ignore Totale" e cioe' non sono solo gli utenti tradizionali "a ignorare i reali contenuti",ma sono gli stessi autori celebri,a ignorare quello che hanno scritto "i loro colleghi" e sopratutto non hanno nemmeno "Un Idea",rispetto a quello che hanno scritto Loro!:)I dati sono in Master Contest e rispetto al contesto tradizionale,sono sistemati anche i migliori contenuti (sono rari gli autori celebri che hanno dati migliori e in pratica ne esistono solo 2,tratti dal Gotha assoluto della scrittura:) e le posizioni riguardano i singoli domini (cioe' quello che hanno scritto realmente gli autori celebri) e quindi i Match ,sono presenti gia' nelle opere dirette,senza effettuare nessun "Match Globale".(in pratica hanno copiato se stessi gli autori celebri ,ed è difficile immaginare che siano in buonafede,perche' sono alte le percentuali dei Copied e ,spesso sono bassi gli average,sempre all'interno delle stesse singole opere:).Tutto questo ha come riferimento solo le dimensioni della lingua italiana negli Index,semplicemente perche' la loro presenza,non puo avere nessuna delle posizioni descritte in Master Contest:)Quindi il valore effettivo dei contenuti è anche maggiore,rispetto alle descrizioni dei passaggi precedenti (15 volte tutti gli scritti della storia umana,solo per la lingua italiana:) e questa posizione rende molto facile comprendere da cosa nascono i valori del contesto online e a differenza di quello tradizionale,si conosce tutto!:)Sara' molto utile per i contenuti che aggiungero' e prima di farlo,sistemo un altra unione:Questo è il valore reale degli Index e si raggiunge attraverso tutti i passaggi precedenti e debbono poi essere uniti alle proposte complessive di ciascun dominio e formano il Main Content.Dopo aver accertato la sua presenza,è possibile applicare "gli eventuali Copied presenti" e queste posizioni valgono per qualsiasi Detect Languege e "Around the World" ha un senso estremamente semplice e cioe'i Match dei termini sono globali ,rispetto a qualsiasi lingua , siano stati creati i contenuti.Questo è un ottimo esempio per l'applicazione di "Around the World", ed è la lingua Bengali di Wiki (tante volte protagonista) e i Match dei termini sono indifferenti alle lingue e ai caratteri in cui sono scritti i contenuti:)Naturalmente,nell'esempio non ho inserito "un match qualsiasi" ma è Din Post Story e quella sistemata è la prima pubblicazione in lingua Bengali per il dominio di Wiki:)La stessa posizione è valida per tutti i contenuti del Detect Language italiano e i loro Index,hanno gli stessi Match Globali e di conseguenza è ancora piu' semplice comprendere,quanto sono elevate le differenze,rispetto ai dati ufficiali:) Il contesto tradizionale di tutti gli scritti della storia umana,non possiede in realta' nemmeno 1 Match tra i propri Content e quindi è facile comprendere quanto siano elevati i valori opposti e per farlo è possibile utilizzare "anche un piccolo Detect Language",come quello italiano:) (solo per citare la comparazione diretta della lingua Bengali,i suoi contenuti sono realizzati da 250 Milions di autori,contro i 70 Milions italiani:)
Per sistemare la prima unione con la lingua italiana,ho scelto una sezione di Unnatural Developer:
Sono sistemati i valori economici delle categorie online e il primo riferimento è il contesto italiano e naturalmente inizia dalla sua lingua.
E' una lettera di Davide Casaleggio,non particolarmente positiva,perche' riguarda "la grave morosita'" dei deputati del Movimento politico "5 Stelle" (secondo Casaleggio non hanno pagato proprio e la cifra è intorno ai 300 euro a deputato)
Il nesso con l'immagine sopra è molto semplice e riguarda le dimensioni reali del web italiano "e spesso è snobbato",per le stesse ragioni del contesto tradizionale e cioe' non si conoscono i dati reali:)
Con milioni di iscritti al Movimento politico,la piattaforma di Davide Casaleggio, "potrebbe benissimo utilizzare l'opzione economica online",pero' quella reale e non quella dei "Deprecated Intent":).
la "grave morosita' dei deputati 5 Stelle" è colpa loro,mentre la scelta del social marketing è colpa di Davide Casaleggio.
E' un dettaglio importante,perche' il Detect Language italiano puo essere ovunque, ed è proprio il Caso di evidenziarlo,perche' se dipendesse dalla nazione italiana effettiva ,i suoi dati sarebbero assai minori.
Quest'immagine è tratta da Jun 2020All'interno degli utenti italiani,esiste la lingua napoletana e i suoi database hanno notevoli volumi e la posizione sopra,nel contesto originale,è molto curiosa e nello stesso tempo è utilissima,per comprendere quale sia il livello dei Match globali:)
All'inizio mi ha solo incuriosito la 3° posizione in dimensioni della lingua napoletana,ed era dedicata a Marte e pensavo che sarebbe stato davvero difficile trovare qualche Match:) (è sufficente leggere lo scritto sopra,ed è davvero difficile immaginare che i contenuti possano avere dei conflitti:)
L'immagine è sempre tratta da Jun 2020 e i Match esistono e sono di altissimo livello pure,rispetto ai contenuti in lingua napoletana:) E' solo una posizione all'interno degli utenti italiani,diversa dal Detect Language ufficiale:sempre dai domini Wiki esiste anche la lingua latina (è stata protagonista a Jan 2020 ) e possiede un notevole database per i suoi volumi.Solo all'interno dei domini Wikimedia,esistono anche contenuti in lingua siciliana e sarda e a loro volta,esistono tantissimi altri domini che utilizzano le stesse lingue e sono classificati sempre all'interno degli utenti italiani.Sempre per i domini Wiki,all'interno del suolo italico,esiste anche la lingua piemontese e anch'essa ha poi numerosi altri spazi,ed utilizzano la stessa lingua piemontese.
Qui è sistemato un elenco parziale per i database delle lingue e riguardano solo l'italia meridionalequeste sono altre lingue assai diffuse tra gli utenti italianiqui sono sistemate altre lingue e riguardano il Nord Est italiano e anche loro hanno dei database questa è un altra divisione degli utenti italiani,attraverso le lingue localiQuest'ultima è molto curiosa,perche' esistono delle raccolte in pdf dei contenuti delle varie lingue e tra di esse,esiste una posizione a me molto cara,ed è il "Central Marchigiano":).Sono posizioni molto importanti per comprendere il percorso da cui derivano i dati,perche' i contenuti degli elementi sistemati,contribuiscono notevolmente a formare le rilevanze dei termini:) Questi sono gli indirizzi italiani attuali
Sono importantissimi,perche' permettono di dividere il Detect language specifico ,grazie alle tante lingue presenti e probabilmente,gli autori effettivi della lingua italiana,appartengono in maggioranza,alle altre 28 nazioni presenti:) (esistono oltre 56 Milions d'indirizzi solo in Italia e le lingue minori,occupano quasi la sua meta' e per arrivare a 70 Miloons di utenti per contenuti in lingua italiana,occorre per forza "un grande contributo esterno" e formano lo 0,9% rispetto ai contenuti complessivi di tutto il web e solo da questa posizione nascono gli RF e i Just Time :)
 Gli Index della lingua italiana, derivano dalle posizioni sopra e per il momento ho solo sistemato le unioni con le idee individuali e iniziano dalla pagina dei sistemi ,attraverso i Post Base e poi è possibile unire i contenuti dedicati al valore economico delle categorie online ,sistemate nell'evidenza precedente e unite a loro volta alla lettera di Davide Casaleggio, per le "gravi morosita'". (conoscendo la riservatezza estrema della persona,per esporsi e utilizzare termini come "grave morosita'",diventa facile ipotizzare l'importo economico non versato alla piattaforma online Rousseau da parte dei deputati del Movimento 5 Stelle :) (per fare incazzare in questo modo Davide Casaleggio,è molto probabile che il riferimento economico delle gravi morosita' ,non riguardino solo "dei pagamenti arretrati" ,ma quelli totali e cioe' non hanno pagato proprio:)
Gli Index della lingua italiana, derivano dalle posizioni sopra e per il momento ho solo sistemato le unioni con le idee individuali e iniziano dalla pagina dei sistemi ,attraverso i Post Base e poi è possibile unire i contenuti dedicati al valore economico delle categorie online ,sistemate nell'evidenza precedente e unite a loro volta alla lettera di Davide Casaleggio, per le "gravi morosita'". (conoscendo la riservatezza estrema della persona,per esporsi e utilizzare termini come "grave morosita'",diventa facile ipotizzare l'importo economico non versato alla piattaforma online Rousseau da parte dei deputati del Movimento 5 Stelle :) (per fare incazzare in questo modo Davide Casaleggio,è molto probabile che il riferimento economico delle gravi morosita' ,non riguardino solo "dei pagamenti arretrati" ,ma quelli totali e cioe' non hanno pagato proprio:)
Tantissime altre unioni sono nei Post Base, sempre all'interno della pagina dei sistemi e questa posizione serve per creare la migliore evidenza ai valori del contesto globale ,ed è questo il motivo della collocazione del Detect Language italiano.(nel contesto globale i suoi content hanno un piccolo valore,pero' restano importanti lo stesso e i motivi sono nei collegamenti sopra e nei contenuti che seguiranno:)Qui è sistemata la collocazione originale di Dati NowHa raggiunto dimensioni notevoli e quindi è possibile sistemare solo delle sue sezioni:)
Ho scelto 2 Dati Now del tutto opposti e i motivi sono nelle evidenze:quella di colore verde ha dati effettivi,perche' esistono contenuti realmente ,mentre è l'opposto per l'evidenza di colore giallo.L'unica posizione comune che hanno sono i codici Javascript:qui è sistemata la pagina dedicata, a sua volta unita anche a Unnatural Developer Dati Now Formeranno l'unione con il contesto globale e il senso sara' unito al valore reale di qualsiasi dato:inizia dall'esempio diretto di Unnatural Developer,perche' entrambe hanno i codici Javascript applicati e di conseguenza non potra' esistere nessun Crawler o Bot nei loro dati,semplicemente perche' non li possiedono i codici Javascript e questa distinzione va' poi unita alla presenza effettiva dei Content:) (l'esempio di Dati Now è estremo,perche' i contenuti non esistono proprio:)Il report sopra ha come riferimento proprio i Dati Now senza Content:)All'interno esiste anche l'espansione delle date e sono 7 giorni.(lo spazio è solo la raccolta dei dati delle verifiche e quindi esistono solo dei collegamenti,senza contenuti effettivi)All'interno dei codici Javascript,questi sono i Browser utilizzatiNaturalmente sono escluse le posizioni individuali,ed è indifferente il Browser utilizzato,perche' sono gli indirizzi ad essere esclusi e non si possono ripetere ,anche se fossero legittimi:) (è possibile che 1 solo indirizzo possa accedere diverse volte nell'arco temporale di 1 Log Quota e il suo apporto sara' sempre uguale a 1,ovviamente se non fara' parte dei Bounce Rate o delle Entry Page o delle Exit Page:)Questa è la posizione dei Browsers e anch'essi sono negli Exclude
Quest'immagine deriva dalla pagina A+ di questo 71° RF ,ed è una posizione meravigliosa,per evidenziare ancora meglio le differenze dei Dati Now,rispetto alla presenza o meno dei Content:)Anche su TPJ Level è presente l'URL Match,pero' non procura nessun problema ai dati,mentre è l'opposto per i Match del dominio principale:)
Questo è il senso di URL Match,ed è sufficente vedere le Sitemap del dominio individuale,per comprendere quanto possa essere elevato il suo impatto e in questo Caso,l'ESCLUDE potrebbe diventare un opzione positiva,perche' sarebbero tante le posizioni degli URL Match:).L'aspetto piu' rilevante deriva dal fatto "che sono solo di rilevamenti di base" e quindi ragionano "come se non esistesse il contesto globale" e i suoi Match,sono assai peggiori dei conflitti degli URL:)(con i dati reali del contesto globale,diventa inutile gli URL dei Match,perche' le probabilita' maggiori derivano dal fatto ,che le pubblicazioni sono eliminate:)
Adesso inserisco una sistemazione unica,per le posizioni,sempre eliminate:Questa è la Keyword Analysisl'arco temporale è "Today" (SEP 20) ,ed è solo un riferimento,perche' qualsiasi fosse la data,non esisteranno mai reports,perche' le Keyword Analysis non sono attivate:)questa è la Paid Traffic è non è attivataIl riferimento è 1 solo project,pero'le stesse impostazioni sono valide anche per gli altri domini
questa è la non attivazione dei tagsAl suo interno esistono anche i nomi delle pubblicazioni e sono quindi negli EXCLUDE,dai Dati Now:)Posso anticipare che questa posizione sara' fantastica,perche' la Non Attivazione dei Tags riguarda direttamente anche i domini individuali e la scelta è proprio strutturale dalla nascita dei domini e l'aspetto fantastico,sono i dati globali stessi,senza utilizzare nessun Tags:)Tra l'altro non sarebbe stato nemmeno necessario attivare i Tags,perche' anche i Search Engine sono esclusi:)
questa è l'esclusione del Sync Google KeywordsE' valida per tutti i Projects,tranne Key TD Archive e nel suo Caso,l'attivazione è parziale,perche' non esiste l'Upgrade dello strumento:)
L'unione dei codici Javascript iniziano dalle strutture dataSono semplicemente le informazioni standard degli spazi fisici in cui sono inseriti i content.La posizione delle Structured Data sara' unita agli Snippet tra un po' e l'unione avverra' attraverso il Brain Stone:)
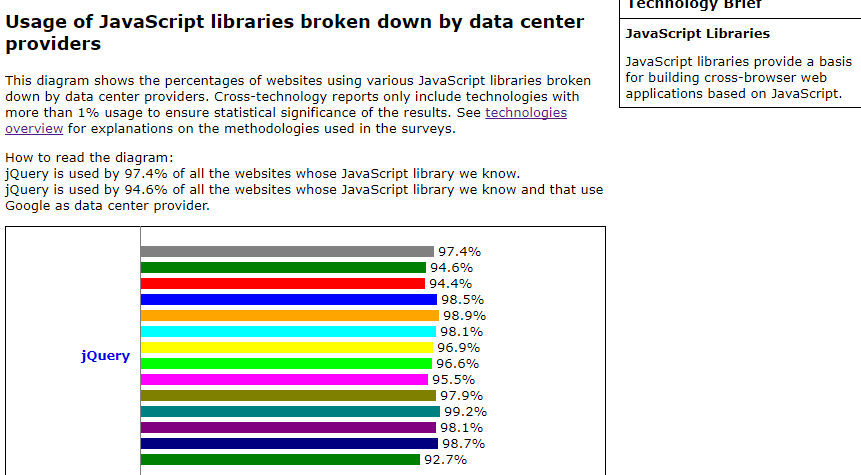
Naturalmente sono sistemati solo i maggiori,pero' le stesse posizioni appartengono anche a tutti gli altri providers e quindi,per i rilevamenti di base,la selezione dei codici Javascript "non richiede un grande impegno":)
E' tra le piu' curiose,perche' certificano gli altri domini ,sempre attraverso dei codici Javascript.
Questa è invece la posizione del TLD .IT rispetto ai principali networks delle Ads e la sua posizione sara' molto importante tra un po' e indirettamente,esiste un altra importanza,perche' dalla posizione sopra "è arrivato un fantastico suggerimento" e cioe' di unire il TLD .IT ai Content diretti ,ed è arrivata una fantastica sorpresa:)
E' fantastica questa posizione,perche' sono gli autori in lingua inglese i primi a contribuire al volume del Detect language in lingua italiana e non sono tanto inferiori nel numero, agli italiani stessi:) Lo o,1% è effettivo degli autori in lingua inglese e rispetto allo 0,9% complessivo del Detect Language italiano,rappresenta un notevole contributo,sopratutto per le tantissime divisioni degli utenti italiani stessi:)
Anche il Brain Stone inizia ad essere operativo e lo sara' rispetto a qualsiasi dato e la sua prima unione è con gli Snippet e le Strutture Data e tra un po' saranno i protagonosti del primo Rick Snippet:) (ovviamente esisteva anche prima,pero' non aveva questo contesto, ed è il metodo piu' semplice per comprendere i valori reali di qualsiasi dato:)
questo è il valore piu' importante unito agli Snippet e naturalmente lo è anche per la Struttura Data e qui aggiungo solo una semplice considerazione rispetto ai contenuti originali e cioe' le sanzioni sono applicate a tutti i domini,uniti a quello in violazione (nei contenuti originali ho sistemato solo l'esempio citato nei contenuti dell'immagine,mentre le sanzioni riguarderanno tutti gli eventuali spazi collegati,a quello in violazione)
Structured Snippet Brain Stone è qui
Inizio con la descrizione dello spazio,tramite le evidenze dei colori sistemati:il nome dello spazio (Verde) ha il collegamento con la pagina principale e al suo interno esistono le varie sezioni dei Brain Stone ; l'evidenza di colore Blu ha il collegamento con la pubblicazione originale e al suo interno esistono le descrizioni dei contenuti per i Brain Stone:)L'evidenza di colore giallo è un piccolo slide con i collegamenti delle varie sezioni.Le altre posizioni dei collegamenti sono intuitive e qui sistemo solo una curiosita' e riguarda l'immagine dedicata agli "Article Spinner" e appena ho creato il collegamento con la pubblicazione originale,ho fatto "una prova di funzionamento":)Ovviamente conoscevo i contenuti,pero' è impossibile ricordarsi di tutte le posizioni e l'unica cosa che avevo in mente in maniera chiara,derivava solo dal fatto che i contenuti esistevano:)La pubblicazione ha diversi anni e non è stata mai modificata ,come tutte le altre,pero' questa volta l'assenza di EDITS ha un "Plus Incredibile" ,perche' il passaggio diretto per gli Article Spinner è formato da periodi risistemati:) Posso assicurare che non l'ho fatto di proposito,perche' non mi ricordavo nemmeno dove avessi sistemato i contenuti e appena li ho visti,mi hanno divertito tantissimo,perche' è una presa per il culo notevole:)Gli Article Spinner sono dei rewtires;risistemazioni e il loro aspetto è del tutto negativo e la loro descrizione,è "fatta con altre risistemazioni":) Nella parte opposta ad Article Spinner esiste il banner di Penguin e il suo collegamento è con la pagina di Feb 2017,ed è la raccolta dei Top imbecilli:)Ovviamente,se è presente il collegamento, esistono dei motivi ,ed è il ruolo di Penguin stesso ,nelle selezioni dei Links:)Quelle dei Top Imbecilli hanno "dati elevatissimi",pero' il valore dei numeri ,ha un unico riferimento e sono i caratteri della lingua araba:)Quindi la posizione nei Brain Stone è molto pertinente,perche' i rapporti dei Links ,sono completamente disgiunti dai valori reali e a stabilirlo è la "scienza esatta di Penguin":) (esistono alti numeri,pero' senza nessun valore,a parte la conoscenza della lingua araba per i numeri:)
 L'immagine sopra,nella posizione originale rappresenta "la salvezza dagli idioti" ,ed è sufficente applicare la sua espansione:per "ottimizzare il Rank Brain" esiste "1 sola raccomandazione" ed è quella di utilizzare il Natural Language:)Nella realta' non esiste nessuna possibilita' di ottimizzare il Rank Brain e il Natural Language occorre averlo "a monte di tutti i percorsi" ,perche' è l'unico modo "per ARRIVARCI al Rank Brain":)Wiki è un Top Friend Din e quindi non sara' mai nei Brain Stone e la posizione sopra la considero solo un regalo meraviglioso,degno dei TFD:)Non è una pubblicazione qualsiasi,ma la prima di Wiki in lingua Cebuana e questa posizione potra' essere inserita,come estremo esempio,in tutti i "Content Unnatural" ,qualsiasi essi siano:) Gli operatori degli "Article Spinner" sono delle "bazzecole" rispetto alla potenza tecnica di Wikimedia e il dominio in lingua cebuana "è il piu' fulgido esempio" per comprendere i valori reali del contesto online:) Secondo i dati ufficiali di Wiki,la lingua cebuana raggiunge il 99% dei contenuti automatici,ed è da escludere al 100% che esistano altre posizioni tecniche migliori di Wiki nei Content:)
L'immagine sopra,nella posizione originale rappresenta "la salvezza dagli idioti" ,ed è sufficente applicare la sua espansione:per "ottimizzare il Rank Brain" esiste "1 sola raccomandazione" ed è quella di utilizzare il Natural Language:)Nella realta' non esiste nessuna possibilita' di ottimizzare il Rank Brain e il Natural Language occorre averlo "a monte di tutti i percorsi" ,perche' è l'unico modo "per ARRIVARCI al Rank Brain":)Wiki è un Top Friend Din e quindi non sara' mai nei Brain Stone e la posizione sopra la considero solo un regalo meraviglioso,degno dei TFD:)Non è una pubblicazione qualsiasi,ma la prima di Wiki in lingua Cebuana e questa posizione potra' essere inserita,come estremo esempio,in tutti i "Content Unnatural" ,qualsiasi essi siano:) Gli operatori degli "Article Spinner" sono delle "bazzecole" rispetto alla potenza tecnica di Wikimedia e il dominio in lingua cebuana "è il piu' fulgido esempio" per comprendere i valori reali del contesto online:) Secondo i dati ufficiali di Wiki,la lingua cebuana raggiunge il 99% dei contenuti automatici,ed è da escludere al 100% che esistano altre posizioni tecniche migliori di Wiki nei Content:)Questa è la posizione della lingua cebuana e solo considerando le dimensioni,è la 2°,dopo Wiki globale e la la3° (lingua svedese) ha la stessa percentuale di Automated Content:)
Anche questa posizione è fantastica ,perche' esiste la sicurezza che il Core Web Vitals non ha influito sui contenuti:)


Questa è la pubblicazione del 71° RF e nel suo Caso,solo i Content hanno potuto risolvere i Match ,perche' con i pesi dei suoi elementi statici,il Core Web Vitals "non è proprio compatibile":) (i pesi derivano solo dalle posizioni normali e cioe' non è presente nessun gif nel background del dominio e naturalmente,spero di risistemarli tra alcuni giorni,dopo la data di questa pubblicazione:)
 E' il primo snippet e struttura data degli RF,pero' con il contesto completo e inizia dalla cosa piu' semplice e cioe' deve esistere la pubblicazione.)In realta' il contesto da cui derivano i dati sopra,è difficilissimo ed è sufficente vedere le fluttuazioni dei recenti 3 mesi,ed occorre anche applicare "una notevole tara" rispetto ai dati reali:)Secondo l'esperienza di questi anni,i dati reali delle fluttuazioni ,non essendo presenti quelli ufficiali,è meglio moltiplicarli per 4 o 5 volte e si ha quasi la certezza di essere molto vicini alla realta':)Naturalmente,occorre moltiplicare anche l'arco temporale della pubblicazione (per 6 volte in questo Caso:) ; occorre aggiungere le dimensioni della pubblicazione specifica e i Match interni al dominio e dopo questo è possibile "confrontarsi con gli snippet e le strutture data" :)E' sempre la prima pubblicazione in dimensioni di Wiki in lingua cebuana e anche questa posizione ,diventera' un "argine insormontabile" per qualsiasi idiota:)Sono i migliori strumenti automatici possibili e vedendo l'H2 ,sembra incredibile,mentre è tutto vero:)Probabilmente anche da queste posizioni provengono i problemi alla struttura data e allo Snippet :Qui sono sistemati i dati realiGli H2 degli Headers ne sono in realta' 109 e le collocazioni sono gerarchiche e H2 è dedicata solo alla data dellapubblicazione (H3 ha il nome) e anche questi sono dei Tags e non possono essere inseriti "in maniera random" ma puo essere presente solo 1 periodo per ogni Header e al massimo puo avere 60 caratteri:)
E' il primo snippet e struttura data degli RF,pero' con il contesto completo e inizia dalla cosa piu' semplice e cioe' deve esistere la pubblicazione.)In realta' il contesto da cui derivano i dati sopra,è difficilissimo ed è sufficente vedere le fluttuazioni dei recenti 3 mesi,ed occorre anche applicare "una notevole tara" rispetto ai dati reali:)Secondo l'esperienza di questi anni,i dati reali delle fluttuazioni ,non essendo presenti quelli ufficiali,è meglio moltiplicarli per 4 o 5 volte e si ha quasi la certezza di essere molto vicini alla realta':)Naturalmente,occorre moltiplicare anche l'arco temporale della pubblicazione (per 6 volte in questo Caso:) ; occorre aggiungere le dimensioni della pubblicazione specifica e i Match interni al dominio e dopo questo è possibile "confrontarsi con gli snippet e le strutture data" :)E' sempre la prima pubblicazione in dimensioni di Wiki in lingua cebuana e anche questa posizione ,diventera' un "argine insormontabile" per qualsiasi idiota:)Sono i migliori strumenti automatici possibili e vedendo l'H2 ,sembra incredibile,mentre è tutto vero:)Probabilmente anche da queste posizioni provengono i problemi alla struttura data e allo Snippet :Qui sono sistemati i dati realiGli H2 degli Headers ne sono in realta' 109 e le collocazioni sono gerarchiche e H2 è dedicata solo alla data dellapubblicazione (H3 ha il nome) e anche questi sono dei Tags e non possono essere inseriti "in maniera random" ma puo essere presente solo 1 periodo per ogni Header e al massimo puo avere 60 caratteri:)
 Questa posizione è incredibile e appena l'ho vista ,i salti di felicita' hanno superato l'omino della gioia ,perche' le stesse posizioni appartengono anche agli altri domini Wiki:)Non mi era venuta in mente prima,perche' pensavo che fosse scontata la presenza della Sitemap e posso assicurare che ho fatto tantissimi altri test e i dati hanno tutti confermato l'assenza della Sitemap:)Non credo che sia casuale che questa posizione sia capitata nel 71° RF dedicato al Contest level Absolute e quindi a Nostra Signora del Common Content:)Se è assente la Sitemap,le posizioni degli Internal Links OUT cambiano completamente e con essi anche i valori dei dati e dei contenuti a cui sono applicati:)Ci sarebbero tantissime altre posizioni specifiche e le sistemero' a OCT 2020 e in questa posizione,il ruolo principale è della protagonista del 71° RF:)
Questa posizione è incredibile e appena l'ho vista ,i salti di felicita' hanno superato l'omino della gioia ,perche' le stesse posizioni appartengono anche agli altri domini Wiki:)Non mi era venuta in mente prima,perche' pensavo che fosse scontata la presenza della Sitemap e posso assicurare che ho fatto tantissimi altri test e i dati hanno tutti confermato l'assenza della Sitemap:)Non credo che sia casuale che questa posizione sia capitata nel 71° RF dedicato al Contest level Absolute e quindi a Nostra Signora del Common Content:)Se è assente la Sitemap,le posizioni degli Internal Links OUT cambiano completamente e con essi anche i valori dei dati e dei contenuti a cui sono applicati:)Ci sarebbero tantissime altre posizioni specifiche e le sistemero' a OCT 2020 e in questa posizione,il ruolo principale è della protagonista del 71° RF:)
Questa è la pubblicazione del 71° RF ,ed è perfetto anche il grado e sopratutto da cosa deriva:)Tra le priorita' per aumentare lo score esistono i Tags degli Heders:)

I Tags non sono abilitati ,ed esiste solo l'Original Text e questa posizione "è strutturale" ed esiste da sempre:)
Anche questa posizione è spettacolare,ed è possibile unirla ai codici Javascript uniti ai CMS,sistemati nei passaggi precedenti.
I CMS ,spesso si confondono con le piattaforme,mentre in realta' sono dei servizi per le ottimizzazioni e i costi sono notevoli.
Esistono tante "Estimate Quote" e le varianti sono numerose,per avere "informazioni sui costi giusti":per Wiki in lingua cebuana e tutti gli altri domini di Wikimedia ,i CMS sono sempre complessivi e non puo esistere ottimizzazione migliore ,perche' utilizzano i loro database:) (solo per citare un riferimento dei costi,tramite dei calcolatori,i CMS hanno una quota intorno ai 25000 dollari ,pero' il numero di pubblicazioni è limitato e altrettanto i termini da ottimizzare e quindi è facile immaginare quali potrebbero essere i costi per i CMS di Wikimedia:)
Ovviamente,la protagonista del 71° RF non ha nessuna ottimizzazione,ed è completamente naturale:)
A proposito di INDEX ,per i content del Detect Language italiano e qualsiasi altro,lo snippet appena sistemato è un ottimo aiuto :)E' meglio togliersi dalla mente "qualsiasi scorciatoia",semplicemente perche non esiste e fanno parte solo delle Toxic Data:) Solo i Natural Links sono utilizzati negli INDEX e lo sono realmente :)
Anche questo è un ottimo aiuto,ed occorre fare molto attenzione "ai seo irresponsabili e dannosi".Non esistono costi economici per essere negli organici e spesso,puo capitare l'opposto e l'esempio è nel passaggio dedicato agli snippet:)
Questa posizione è meravigliosa e sembra tratta dai contenuti individuali:)le bellissime domande,sono in realta' dei consigli per coloro che ipotizzano di utilizzare dei servizi seo per i loro domini:)La prima è stupenda,rivolta a tantissimi seo:i veri followers sono i seguaci delle linee guida e quelli ufficiali,operano invece all'opposto:) (sono talmente dementi "i seguaci" ,da creare in realta' solo tantissimi danni e i veri benefici li hanno solo le persone oneste e naturali:)
Questa è la posizione piu' ovvia da sistemare e unire agli INDEX:)
Questo è solo l'inizio degli Index per i Text ,nei vari formati e sara' una posizione fantastica per evidenziare ancora meglio il contesto che avranno i Just Time del K2:
Questa è un altra novita' da parte del TFD Google The Keyword ,ed è il Great Match:)I dati saranno sempre esatti,pero' puo capitare di trovare lo scritto evidenziato e in quel Caso,i contenuti uniti ai termini scelti,non sono tanto pertinenti:)
Tra i termini individuali in Brands e gli altri ,per il momento esistono solo dei Great Match:)
In essi è compreso anche il nuovo Just Time K2 e l'immagine stessa è nata proprio a SEP 18 2020 e prima di pubblicarla ho verificato che i termini del prossimo Just Time fossero in K2:)
La sorpresa è stata fantastica e del tutto casuale,perche' non mi ricordavo assolutamente la data originale,per la prima pubblicazione scelta per il nuovo K2:)
La data originale è SEP 18 ,pero' del 2016 e posso garantire che è tutto vero al 100%,ed è fantastico anche il suo INDEX ,perche' è arrivato nel 2° compleanno del Frame Global Limit (a parte la data,esiste anche il background specifico ).
Sono ottimi segnali di augurio per il K2 dei Just Time e poi il Caso Supremo ha aggiunto "una sua perla" ,perche' la prima pubblicazione del K2 è dedicata al plagio (Forever Level Unique) e al suo interno ha anch'essa dei periodi risistemati ,ed esistono da 4 anni e per essere in quella posizione,ha resistito anche all'impatto degli altri contenuti dello stesso dominio:)










 Questo è il numero reale degli autori per i contenuti in lingua italiana e il riferimento di 29 nazioni,indica solo le posizioni in cui esistono "numeri consistenti" di contenuti in lingua italiana.
Questo è il numero reale degli autori per i contenuti in lingua italiana e il riferimento di 29 nazioni,indica solo le posizioni in cui esistono "numeri consistenti" di contenuti in lingua italiana.