


L'immagine aggiunta è di SEP 18 2020 e il K2 è arrivato:)
L'ha fatto in maniera straordinaria e alcuni particolari li sistemero' nella prossima pagina A del 71° RF:)

La pagina A+ avra' la prima pubblicazione degli RF 8D e in seguito ci sara' la pagina A e la scelta deriva solo dalle dimensioni delle pubblicazioni:)


















Nella pagina A di questo 1° RF 8D sistemero' altre descrizioni e riguarderanno i termini aggiunti e qui sistemo solo il motivo della scelta,ed è l'unione con Unnatural Developer Dati Now e deriva dalle dimensioni stesse della pagina:).
I collegamenti originali sono nel piccolo background della sidebar e nella pagina dei sistemi collegata ,è possibile trovare quello di "Dati Now Top Nature" e attualmente,ha raggiunto dimensioni notevoli,tra le nuove publicazioni inserite e il Brain Stone sistemato sopra:)

Questi sono i contenuti di Semrush e il motivo di questa posizione,dipende dal fatto che "le Low Competition Keywords" formeranno una nuova sezione dei Brain Stone e il motivo è descritto nei passaggi sopra:)

Questa è la conferma dei sassi nel cervello di Semrush e indirettamente,riguardano anche i "loro celebri sensori" e naturalmente,la celebrita' è abusiva,perche' non hanno mai azzecato nessun dato,anche applicandoo i PRICE piu' elevati:) (i servizi scadenti,restano tali,rispetto a qualsiasi costo:)


Questa è la posizione reale delle Keywords:)
Non sono sistemate quelle in "Low Competition" di semrush,ma le proposte complessive e i termini ad alta rilevanza ,possono essere collocati solo grazie alla qualita' dei termini effettivi che li contengono:).




Dopo i passaggi precedenti,questa è la collocazione ideale per la protagonista del 71° RF ,ed è il Keywords Stuffing (è la difficulty dei Low Competition Keywords di semrush:) e sono i termini in Match all'interno di 1 pubblicazione,ed è molto facile fare le unioni successive,perche' il metodo è anche la base per avere i Main Content e i loro Copied sono formati anch'essi dai Match interni ai domini,pero' non riguarda 1 sola pubblicazione,ma quelle complessive di ciascun dominio.
Questa è la combinazione da 5 termini




Questa è la migliore posizione per evidenziare meglio,tutti i passaggi precedenti: iniziano dalle proposte complessive dei Main Content,contro le "Low Keywords competion" e arrivano alle Total Keywords appena sistemate e la loro realizzazione concreta è gia'molto difficile,pero' le posizioni non sono complete,perche'mancano le rilevanze effettive e non sono "quelle di semrush" ,ma derivano direttamente dagli Engines:)
E' facile notare la differenza nei valori dei termini e poi occorre aggiungere il contesto oggettivo e quello evidenziato dal colore verde,indica il numero dei domini in cui i termini sono rilevanti e i dati non derivano dalle "Low Competition di Semrush",ma dai RATING reali e quindi è sicuro che i domini indicati hanno il loro Main Content completo e per essere in quella posizione,non esistono Copied e tantomeno l'utilizzo di strumenti automatici:)
La differenza è Totale e i dati sopra,aiutano tantissimo anche a comprendere i valori dei Total Keywords per l'intero dominio ,perche' tantissimi termini ad Alta Rilevanza sono al suo interno e vengono sostenuti da un Detect language,certamente "non tra i piu' rilevanti":)
(solo utilizzando il termine "Naturale",è sufficente togliere la vocale finale e si hanno 3250000 spazi in differenza e poi occorre unirlo ad altri termini e si comprende facilmente quanto possa essere difficile ,perche' l'unicita' la potra' avere solo 1 pubblicazione in 1 dominio e le Close Variant producono un numero elevatissimo di possibili combinazioni e ogni query formata,per i dati ufficiali del TFD Google,ne possiede almeno 100 e ognuna di esse riguarda 1 dominio:)

La posizione dei dati è unita anche all'aspetto tecnico e questa volta esistono anche i Content e quindi la posizione ha un senso pieno:)


Vengono spesso sottovalutati,mentre in realta' sono solo l'inizio di rischi molto piu' importanti e la stessa posizione la possiedono i dati diretti dei "domini unsafe" ,perche' occorre aggiungere anche i domini collegati:)

Non sono dei phishing ,ma sono gia' trasformati in Harmful e anche in questa posizione,occorre aggiungere i domini collegati.
La percentuale non è tanto elevata e non dipende sempre dalle risposte degli utenti,ma dalla pulizia del loro dominio:)
Queste sono alcune operativita' del Phishing e quindi figurarsi quanto possono essere dannose "le sue evoluzioni":)
Il pericolo è nella testa stessa degli idioti,perche' i phishing debbono essere attivati dagli utenti stessi e quasi sempre sono banalissimi e facili da identificare,almeno come sospetto:)
Queste sono alcune operativita' del Phishing e quindi figurarsi quanto possono essere dannose "le sue evoluzioni":)
Il pericolo è nella testa stessa degli idioti,perche' i phishing debbono essere attivati dagli utenti stessi e quasi sempre sono banalissimi e facili da identificare,almeno come sospetto:)



In questa posizione posso solo ricordare una cosa semplice ,ed è l'utilizzo del Fair Use e la sua efficacia,ha in realta' ampli limiti,perche' è sufficente che i termini siano solo un po' rilevanti,per trovare tanti contestatori:)

 Naturalmente anche questa posizione è unita ai Content della pubblicazione protagonista del 71° RF e la prima unione,deriva dal rapporto piu' semplice con i Phishing dei passaggi precedenti e sono le password dei vari account e nel Caso individualene sono centinaia e ognuna di esse puo creare problemi e dipende dai domini a cui sono unite:
Naturalmente anche questa posizione è unita ai Content della pubblicazione protagonista del 71° RF e la prima unione,deriva dal rapporto piu' semplice con i Phishing dei passaggi precedenti e sono le password dei vari account e nel Caso individualene sono centinaia e ognuna di esse puo creare problemi e dipende dai domini a cui sono unite:

Questa posizione è molto importante,perche' è essa stessa "la prima via per il phishing " e sopratutto per i suoi "negativi sviluppi":)


Al suo interno esistono anche altre posizioni e sono sempre le stesse da Feb 2015 e oltre ai Tags non attivati,esistono le posizioni anche degli Original Text ,ed è sufficente non attivare gli Headers per averle:)
Naturalmente,esiste anche la posizione dei valori opposti e derivano proprio dagli Original Text ,perche' i Content "non hanno nessun aiuto" per arrivare agli "End of Code" finali e quindi,possono farlo solo con i termini effettivi e i dati derivano solo da LORO!:)
 Esistono i dati piu' completi per il Clean della pubblicazione:)
Esistono i dati piu' completi per il Clean della pubblicazione:)
Naturalmente i dati sono attuali e non è "un affermazione banale" ,perche' è implicita la posizione del Long Standing Webmasters Guidelines e quindi sarebbe possibbile avere i dati sopra ,pero' senza nessun valore applicato ai Content della pubblicazione specifica:)
Ovviamente è presente l'INDEX e quindi esistono le posizioni tecniche,insieme ai contenuti e nemmeno questa posizione è banale,perche' in 1 anno e 7 mesi esistono anche le oscillazioni sotto e il contest level absolute,ha ricevuto l'impatto,prima nelle sue dimensioni e del dominio in cui è sistemato e poi ha ricevuto anche l'impatto del contesto globale e a differenza delle immagini sotto (rappresentano solo una curiosita' informativa:) i Changes effettivi sono maggiori di 3200 in 1 anno:)

Questa è la prima oscillazione nell'arco temporale di 3 mesi,balida per tutti i device in globale.
I dati riguardano i primi 10 Top con 10 posizioni in fluttuazione e solo il grafico sopra rende ragionevole i dati ufficiali di Google,per i volumi dei contenuti eliminati in 1 giorno :) (l'eliminazione dei contenuti è la realta' piu' vicina alle fluttuazioni:)

Quindi sono davvero ragionevoli i dati ufficiali di Google sui contenuti eliminati in 1 giorno (circa 25 Billions di pubblicazioni con un volume equivalente a 20 Milions dell'opera piu' conosciuta di Leo Tolstoy e a sua volta è formata da 560000 Keywords:), perche' le fluttuazioni sopra riguardano i primi 10 Top e i successivi sono anche peggio e attraverso il Taken Content Against Generally ,valido per qualsiasi posizione del contesto online,rende moplto facile arrivare all'incredibile dato di 25 Billions di pubblicazioni eliminate in 1 giorno:)
Anche per questo motivo lo IoT ha costi cosi elevati,perche' è realmente difficile essere nelle posizioni Top e il senso dell'unione è molto semplice,perche' dopo aver conosciuto "gli intenti degli utenti" occorre unirli "a qualche spazio" e la stessa cosa avviene per gli "Other Intent" :)
Questa è la posizione vincente degli Engines ,perche' gli spazi Big Data,sono in realta degli "accumulatori di dati" ,spesso senza senso,semplicemente perche' "non hanno una grande pertinenza nelle unioni" ,rispetto agli "Intenti degli Utenti" e figurarsi che conoscenza hanno degli "Altri Intenti":)
Gli spazi Big Data,assomigliano molto ai migliori software degli strumenti automatici e cioe' sono eccellenti,pero' le unioni non sono capaci di crearle:) (lo IoT e gli Other Intent derivano dalle unioni dei dati e quindi occorre l'intelligenza reale e quella artificiale puo' provare solo a fare dei Copied:)

L'unione con la pubblicazione protagonista di questo 71° RF è molto semplice,perche' nel suo arco temporale,esistono 6 posizioni equivalenti al percorso sopra e per avere il suo Run Forever,le ha dovute passare tutte e il riferimento dei dati,non sono nemmeno quelli sistemati sopra,ma sono i RATING reali:)

Anche questa è una posizione interessante per lo IoT ,perche' i Desktop globali non sono mai nominati ,pero' mantengono il piu' elevato CTR e determinano anche i piu' elevati acquisti.
Anche questa è una posizione interessante per lo IoT ,perche' i Desktop globali non sono mai nominati ,pero' mantengono il piu' elevato CTR e determinano anche i piu' elevati acquisti.
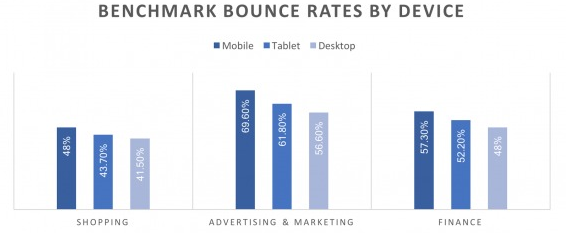
Questa è una posizione anche ottimista,nei rapporti tra i device ,perche' le posizioni generali del desktop sono anche migliori,,rispetto ai grafici sopra:)
Il Benchmark dei Bounce Rates è il rapporto delle singole categorie,rispetto ai loro domini Top specifici e poi esiste il contesto globale e i valori "non sono divisi per categorie" ,ma per i domini reali a cui appartengono e possono essere "trasversali" ,rispetto a qualsiasi categoria.
In questo contesto le differenze del desktop sono assai maggiori e cioe' hanno minori Bounce rates e quindi sono per forza di cose piu' elevati i CTR e avere le fluttuazioni nel desktop,diventa una penalita' assai maggiore,rispetto agli altri device:)

Questo è il senso concreto delle fluttuazioni e dei bounce rate:)
Per la pubblicazione protagonista del 71° RF e tutte le precedenti,i dati sopra sono "un tappeto di fiori" ,perche' le posizioni sistemate derivano solo dai Content e in questo contesto è sufficente solo la semplice ragione:)
Tutte le aziende sistemate nei Top Industry del CTR ,potrebbero permettersi "oceani di backlinks" (se avessero qualche valore reale"),potrebbero "permettersi eserciti d'influencers" ,se avessero anche loro "qualche valore"; potrebbero assumere tutti i migliori rewriters ,insieme ai piu' sofisticati software degli automated content ,se potessero determinare "qualche valore reale":)
Nella realta' non esiste nessuna possibilita' "di utilizzare scorciatoie" ,perche' il contesto online ha un valore economico maggiore di tutti i Top sistemati nell'immagine CTR e lo IoT e gli "Other Intent" hanno 1 solo referente e sono gli Engines e da soli hanno piu' valore delle aziende ,presenti nelle singole categorie:) (anche i social possiedono valore economico,pero' nel loro Caso,sono solo delle "bolle di sapone" ,ed esistono per la presenza stessa degli Engines,perche' se il contesto online dipendesse dai social,sarebbe imploso da tanto tempo:)
La conseguenza diretta è il valore dei Content e l'unita' di misura sono le linee guida:)
La conseguenza diretta è il valore dei Content e l'unita' di misura sono le linee guida:)
Tornando all'immagine del CTR per le Industrie ,i suoi contenuti forniscono tantissime altre informazioni: è possibile sistemare il senso stesso delle fluttuazioni e la divisione per categorie aiuta tantissimo,perche' nei valori generali,le oscillazioni dal 20° Top ,riguardano solo il 4% dei domini e la percentuale comprende le posizioni che vanno dall'11° alla 20°:)
Se fosse la categoria Airline,presente nelle fluttuazioni,le percentuali sarebbero molto diverse,rispetto a quelle sistemate,perche' dopo il 3° Top,esiste solo il 7%,per tutti i domini esclusi dalle prime 3 posizioni:)
E' fantastico e paradossale insieme questo contesto,perche' esistono dati con numeri ciclopici,pero' i valori reali "sono nei piccoli numeri" e fanno grande il singolo peso specifico dei domini:)
Rappresenta in realta' il senso concreto di Taken Against Content Generally e la ragione èmolto semplice,perche' "le riduzioni dei numeri",rappresentano il patrimonio economico degli Engines stessi e quindi i valori dei content,sono a "prova di bomba":) (il Taken Against Content Generally,permette di valorizzare al massimo lo IoT e gli altri intenti e nessuna Big Data è capace di farlo:)
Nel web,è indispensabile unire i valori dei dati,altrimenti si ha solo il contesto degli idioti e cioe' sistemano numeri,la cui pertinenza è unita solo al fatto che i caratteri dei numeri sono scritti in lingua araba e qui Inizia e Termina il loro contesto:)



Naturalmente,ognuno puo utilizzare le Keywords che vuole,pero' se descrive le fluttuazioni,è fondamentale utilizzare i termini giusti:)
Le fluttuazioni avvengono solo per i Changes degli algoritmi e per forza di cose debbono avere una "loro unita' di misura":)

A salire negli archi temporali,esistono le altre decadi e quindi è facile verificare che non esiste ancora una sola pubblicazione che abbia avuto 2 RF,separati nel tempo:)
E' una posizione importantissima,proprio per la sintesi sistemata sopra:"High Standard of Relevance" sono in realta' i Match tra i termini,in qualsiasi lingua e carattere siano scritti e ovviamente,avranno vantaggi maggiori i Detect Language piu' importanti (possiedono il numero maggiore di termini unici e sopratutto hanno elevati i termini effettivi che li contengono).
Quality Raters Follow Strict Guidelines ,possiede l'unione diretta rispetto a qualsiasi dato,per ovvie ragioni e iniziano dalla conoscnza diretta dei singoli periodi e le loro "possibili modifiche",non sono affatto apprezzate:)
Questa posizione ha il Long Standing Webmasters Guidelines,perche' il Quality Raters "occorre meritarlo sul campo" e non è possibile "aggiustare i suoi valori successivamente":)
L'unione della sintesi con le fluttuazioni,è nell'evidenza di colore rosso e cioe' le linee guida sono note,ed hanno inserito anche Google Fluctuations e il termine "Ranking" non è assolutamente presente (ha zero dati su 58000 termini effettivi in 1 sola posizione:).
Il Quality Raters e le sue fluttuazioni,nascono solo dal RATING e la differenza non è formata solo da "una distinzione linguistica",perche',quasi sempre,dietro al termine Ranking,esistono fattori che non hanno nulla in comune con i valori reali:) (si citano i backlinks;i social e tutto il resto e in realta',il loro unico apporto è costituito da danni:)
Solo i content possono fare la differenza e nel 2016,è stata una scelta meravigliosa quella di Origin RF,perche' desideravo proprio fare tutto il contrario e quindi ho escluso qualsiasi elemento,estraneo ad ESSI :)
Questo ha permesso anche di avere entusiasmo nel creare i contenuti,perche' sono consapevole che i valori possono derivare solo da me e nel contesto online,non esiste nessuna possibilita' di "millantare valori inesistenti",perche' i reports reali arrivano in frazioni di secondo e se non esistono valori reali,non ci saranno nemmeno i dati e tantomeno hanno possibilita' di essere protratti nel tempo:)
(mentre sto' scrivendo questo passaggio,la data reale è SEP 16 2020 e solo tra 2 giorni,scade l'arco temporale miracoloso del K2 per i termini in Brands e significano 2 anni consecutivi,possedendo tra i migliori termini ad Altissima Rilevanza e per le idee inserite in questi anni, è felicita' allo stato puro!:)


A differenza di Semrush i dati li ha sempre azzecati,pero' nemmeno Loro conoscono "gli Altri Intenti" e non sono inclusi nei costi dello IoT,semplicemente perche' non sono prevedibili:)

In questo contesto,mi limito allo snippet oggettivo e anch'esso è straordinario,perche' contiene una sintesi perfetta sui valori reali del contesto online e la comparazione con IDC è il massimo possibile,perche' nessun altro possiede la competenza nei costi e negli impatti economici come IDC:)
Nonostante questo,la competenza per gli "Altri Intenti" è del tutto sconosciuta (le risposte sono solo generiche) e la cosa è anche normale,perche' per restituire "Altri Intenti agli Utenti" ,occorre conoscere in maniera perfetta i valori reali del contesto online e solo gli Engines possono farlo,grazie alla Pertinenza dei dati!:)
Questo fa' la differenza nelle percntuali del Market Share,altro che "le posizioni dominanti di EU" e le sanzioni economiche,dovrebbe applicarla a se stessa e a Horizon 2020:) (è la creatura prediletta di EU e dopo i disastri digitali,adesso si occupa anche di coronavirus e i dati sono proprio di EU:)
Gli "Other Intent" sono assai differenti rispetto "alla cultura di EU" ,perche' agli utenti "non si possono raccontare cazzate" ,ma occorre fornire dati effettivi e non esiste nessun dubbio che da questo contesto,sia nato l'incredibile Market Share di Google:)
(EU avrebbe potuto seguire molto meglio "gli intenti dei suoi utenti" ,perche' ha il 12% degli utenti stessi,rispetto a tutto il web,mentre la Cina ha il 50% della macroregione asiatica e a sua volta ha la meta' degli utenti globali e il suo primo Engine, ha condizioni senza uguali,ad iniziare dai blocchi stessi della Cina:)
La macroregione a cui appartiene Google ha il 7%,diviso in 3 grandi nazioni (Messico;Canada e USA) e la percentuale inversa del Market Share è avvenuta a 1 sola condizione:dopo Content e Contest,esiste la 3° C,ed è la Credibility la vera arma vincente di Google ed è l'unico termine da poter unire allo IoT e agli "Other Intent":)
Tornando a IDC, per i costi dello IoT,esistono anche le divisioni per categorie:



E' un felicissimo Amarcord e avevo sistemato l'immagine a festa ,perche' allora è stato un dato spettacolare e lo è realmente,anche se fosse sistemato nell'attualita',in maniera generale,rispetto a tantissimi altri domini:)
Solo il recente SEP 2020,ha quasi raddopiato il volume rispetto al periodo dei dati sopra e naturalmente sono diversi i prelievi degli anni,pero',nel frattempo sono anche aumentati notevolmente i volumi complessivi del dominio e quindi,i dati sopra,sono un felicissimo ricordo,"senza "Nessuna Amarezza"!:)

 Questi sono i Broken Links della pubblicazione e naturalmente sono compresi anche quelli dello spazio fisico in cui sono sistemati.
Questi sono i Broken Links della pubblicazione e naturalmente sono compresi anche quelli dello spazio fisico in cui sono sistemati.
 Queste sono le 2 principali porte (80 per la gestione dei domini e 443 è il percorso delle SSL) e naturalmente sono attuali ,pero' debbono anche avere il percorso completo della pubblicazione,altrimenti i suoi dati non ci sarebbero stati:)
Queste sono le 2 principali porte (80 per la gestione dei domini e 443 è il percorso delle SSL) e naturalmente sono attuali ,pero' debbono anche avere il percorso completo della pubblicazione,altrimenti i suoi dati non ci sarebbero stati:) I dati tecnici sono importanti, perche' esistono contenuti equivalenti (è l'opposto della Opera Top del caro Leo Tolstoy:) e poi sono utilissimi per differenziare le pubblicazioni di 1 solo dominio,perche' tutti i contenuti degli RF hanno il Taken Din Colors Five e per uscire "indenni dalle sue dimensioni",è indispensabile sistemare la loro posizione tecnica:)
I dati tecnici sono importanti, perche' esistono contenuti equivalenti (è l'opposto della Opera Top del caro Leo Tolstoy:) e poi sono utilissimi per differenziare le pubblicazioni di 1 solo dominio,perche' tutti i contenuti degli RF hanno il Taken Din Colors Five e per uscire "indenni dalle sue dimensioni",è indispensabile sistemare la loro posizione tecnica:) Il Clean dei Text e Links in Hiden deve possederlo anche gli spazi collegati e quelli sopra sono solo una sezione.
Il Clean dei Text e Links in Hiden deve possederlo anche gli spazi collegati e quelli sopra sono solo una sezione.



 Tornando agli URL Match il senso è descritto nello snippet sopra e posso aggiungere che non esiste l'opzione "INCLUDE" e di conseguenza l'attivazione puo essere realzzata attraverso l'Upgrade e quindi nello spazio individuale saranno tantissime le posizioni in Match degli URL,perche' le landing pages ne esistono tantissime e il dominio ha dimensioni notevoli:) (sono sufficenti le tante immagini delle Sitemap sistemate ,per rendere semplice quanto possa essere elevato l'impatto degli URL Match:)
Tornando agli URL Match il senso è descritto nello snippet sopra e posso aggiungere che non esiste l'opzione "INCLUDE" e di conseguenza l'attivazione puo essere realzzata attraverso l'Upgrade e quindi nello spazio individuale saranno tantissime le posizioni in Match degli URL,perche' le landing pages ne esistono tantissime e il dominio ha dimensioni notevoli:) (sono sufficenti le tante immagini delle Sitemap sistemate ,per rendere semplice quanto possa essere elevato l'impatto degli URL Match:)
E' necessario farlo,perche' le dimensioni del dominio sono incredibili e queste posizioni "certificano l'incredibilita" e servono per confermare che le posizioni dei dati,sono tutti naturali:)
 Questo è il Cloaking della pubblicazione e certifica che esiste 1 sola posizione per i contenuti specifici e naturalmente,debbono avere questa posizione da sempre (il riferimento èla data della pubblicazione originale e non esistono possibilita' di "avere fasi alterne",perche' non sarebbero esistiti gli INDEX precedenti all'attuale e nel loro Caso,esiste 1 sola possibilita' di avere valore e cioe' possono essere solo consecutivi,per qualsiasi arco temporale futuro e ovviamente,l'aspetto tecnico del Cloaking e di tutti gli altri fornisce un apporto importante,pero' a determinare gli INDEX sono sempre i Content e quindi le pubblicazioni di qualsiasi RF ,debbono avere sia la parte tecnica e quella dei Content diretti:la prima risolve il contesto,mentre l'altra descrive i Match:) (occorre ricordare la cosa piu' semplice e cioe' per arrivare ad ogni INDEX esistono i conflitti dei content e lapubblicazione del 71° RF ne ha avuto 9 in 1 anno e 7 mesi e sono loro che hanno permesso di arrivare al suo Run Forever:)
Questo è il Cloaking della pubblicazione e certifica che esiste 1 sola posizione per i contenuti specifici e naturalmente,debbono avere questa posizione da sempre (il riferimento èla data della pubblicazione originale e non esistono possibilita' di "avere fasi alterne",perche' non sarebbero esistiti gli INDEX precedenti all'attuale e nel loro Caso,esiste 1 sola possibilita' di avere valore e cioe' possono essere solo consecutivi,per qualsiasi arco temporale futuro e ovviamente,l'aspetto tecnico del Cloaking e di tutti gli altri fornisce un apporto importante,pero' a determinare gli INDEX sono sempre i Content e quindi le pubblicazioni di qualsiasi RF ,debbono avere sia la parte tecnica e quella dei Content diretti:la prima risolve il contesto,mentre l'altra descrive i Match:) (occorre ricordare la cosa piu' semplice e cioe' per arrivare ad ogni INDEX esistono i conflitti dei content e lapubblicazione del 71° RF ne ha avuto 9 in 1 anno e 7 mesi e sono loro che hanno permesso di arrivare al suo Run Forever:)

 Questa è la Class C e l'IPv6 attuale per i content e quindi i dati delle Total Keywords "possono avere match tranquilli" e se perderanno "in qualche conflitto" ,lo faranno solo con le loro forze:) (tra l'altro sono elevatissime,perche' uscire indenni dal Taken Din Colors Five,richiede gia' uno sforzo notevole per i contenuti delle singole pubblicazioni del dominio individuale:)
Questa è la Class C e l'IPv6 attuale per i content e quindi i dati delle Total Keywords "possono avere match tranquilli" e se perderanno "in qualche conflitto" ,lo faranno solo con le loro forze:) (tra l'altro sono elevatissime,perche' uscire indenni dal Taken Din Colors Five,richiede gia' uno sforzo notevole per i contenuti delle singole pubblicazioni del dominio individuale:)
 Questa è un altra posizione tecnica meravigliosa,sopratutto in un dominio con dimensioni notevoli:)
Questa è un altra posizione tecnica meravigliosa,sopratutto in un dominio con dimensioni notevoli:)
Non esiste nessun Text e Links in Hiden e cioe' "sono quelli non visibili" e quindi,in qualsiasi reports esistono solo content naturali ed effettivi e la sua presenza è dovuta a una semplice ragione e cioe' sono tanti i domini che utilizzano "questa strategia",ed è molto difficile che gli operatori siano in buonafede:)
Ovviamente anche questa posizione è all'interno degli INDEX e la presenza di Google details è in realta'il suo Trasparency Reports e con i Text e i Links in Hiden,esiste soloil De-Index immediato e avviene 1 solavolta e quindi anche questa posizione è in Long Standing Webmasters Guidelines.
Ovviamente anche questa posizione è all'interno degli INDEX e la presenza di Google details è in realta'il suo Trasparency Reports e con i Text e i Links in Hiden,esiste soloil De-Index immediato e avviene 1 solavolta e quindi anche questa posizione è in Long Standing Webmasters Guidelines.
Appena l'ho vista mi ha subito incuriosito ,perche' mi ricordavo tante posizioni del Contest Level Absolute,pero' mi ero dimenticato dei Frati Cappuccini e li ho ritrovati proprio all'interno dei Text e Links in Hiden e anche loro debbono avere il Clean,per non avere problemi a mia volta:)
L'ho sistemato perche' i 4 termini uniti al Contest Level Absolute,derivano proprio da loro e posso solo aggiungere che dopo 1 anno e 7 mesi,i 4 termini hanno cambiato dominio e sono tra quelli individuali:) (mi dispiace per i frati cappuccini ,pero' non l'ho fatto di proposito:)
Tra i Clean della pubblicazione esiste anche il dominio del TFD Statcounter e quello sopra è il suo Google details ed è il Trasparency Reports:)
Nella pagina A ci saranno anche altri dati di Stacounter e saranno fantastiche le unioni,perche' inizieranno dai codici javascript con tanti elementi e poi mi è venuta in mente un unione curiosa con i Detect language,uniti ai codici Javascript e ai TLD (Top Level Domain) .
Saranno nella pagina A e in questa posizione sistemo altri Dati Now,per completare le posizioni precedenti.
E'una posizione mai sistemata prima,ed è utile per unire i contenuti che seguiranno,compresi quelli che avra' la pagina A di questo 71° RF:)
La posizione è "Today" e il riferimento temporale è SEP 15 e l'orario è quello indicato sopra e sistemato anche qui .
Questa è la conversione dell'orario GMT e rappresenta il riferimento temporale dei dati.
All'apparenza sono "particolarti minimi",pero' saranno importanti lo stesso e non per i dati oggettivi,ma per i valori reali applicati ad essi e sara' proprio il TFD Stats a fornirli:)

Occorre solo ricordare che le "Page Title" fanno parte dei Tags e non sono abilitati sullo strumento e nemmeno su questo dominio,insieme agli altri individuali.(anche la piattaforma AV non ha i Tags abilitati)
Quindi le posizioni delle pubblicazioni dei "Page Title",sono tra quelle escluse in poche ore e non rientrano in nessun Bounce:)
L'unica distinzione la possiede l'URL della Homepage,semplicemente perche' non esiste e quindi il riferimento del dato,lo possiede la verifica di SEP 2020 e dopo pubblicazione,sara' questa pagina ad essere la Homepage del dominio e quella successiva sara' la pagina A del 71° RF.

Esiste solo la differenza di 1 ora e tutto l'insieme,avra' la stessa funzione dei dati now precedenti,perche' i valori reali non sono inseriti sopra e l'aspetto fantastico,lo avra' le unioni dello strumento stesso:) (questo riguarda qualsiasi rilevamento di base:)

Ovviamente esiste lo stesso orario e la descrizione è in Unnatural Developer Dati Now e tra un po',indirettamente,sara' una protagonista fantastica:) Il collegamento è nella parte sinistra del footer per Dati Now e al suo interno esiste anche quello del sistema dedicato e un altro collegamento è nella sidebar,attraverso il link del piccolo background.
 Questi sono i codici Javascript per "Today" di SEP 16
Questi sono i codici Javascript per "Today" di SEP 16
La differenza del giorno precedente è solo 1ora.
Naturalmente esistono anche gli altri domini con altri dati e la posizione appena aggiunta,serve solo a ricordare che in qualsiasi dato esiste il No Group e cioe' non è presente nessuna somma dei dati e ogni dominio li ha in maniera autonoma:) (anche se sono diverse le piattaforme,è possibile sempre sommare i dati dei singoli domini ,ed è sufficente che siano presenti e verificati in 1 project e che abbiano i loro codici:)
 Adesso inizia l'aspetto fantastico dei dati e ad ogni periodo è possibile unire tutti i Content di Unnatural Developer,uniti ai nuovi dei Brain Stone:)
Adesso inizia l'aspetto fantastico dei dati e ad ogni periodo è possibile unire tutti i Content di Unnatural Developer,uniti ai nuovi dei Brain Stone:)
Inizio dalla cosa piu' semplice,ed è il fatto che è un dominio diverso e ha suoi dati diretti,senza nessuna somma con gli altri:).
Nel nuovo sistema dei Dati Now esiste un altra evidenza,ed ha i collegamenti con le pubblicazioni specifiche e nel sistema ho solo aggiunto "pochi termini" : Top Contest // No Content :)
E' assolutamente vero,ed è una posizione fantastica da unire a Unnatural Developer,perche' le dimensioni stesse delle pubblicazioni,sono un elemento importantissimo del Natural Contest e senza di esso,i Match non iniziano nemeno e sara' inutile ceracre qualsiasi rilevanza:)


 Questa è invece l'espansione del dominio principale:)
Questa è invece l'espansione del dominio principale:)
L'ho descritta tante volte e quella sopra è l'espansione della Log Quota specifica e puo variare,pero' il margine è minimo senza l'Upgrade:)
La sezione non evidenziata (7 days) non si puo digitare e quindi restano le scelte sistemate nell'immagine.
questa è la sezione inferiore e i 5 giorni non comprendono SEP 17.
Sono solo 2 giorni (SEP 15 e 16) e il limite temporale è fisso e quindi,è sufficente raggiungere 500 indirizzi unici per completare la posizione,a prescindere dall'arco temporale applicato:)

E' sufficente che esista 1 sola pagina per 1 indirizzo unico per escluderle e naturalmente,non debbono essere dei Bounce,altrimenti i dati sarebbero "sistemati in un altra posizione":)
Qui sono sistemate le Exit Page
Il dato dei 2 giorni è nella prima immagine di questo passaggio e sono i codici Javascript attivati e in questo Caso,ne sono 496 e significa che gli indirizzi unici sono reali e poi esistono 4 codici Javascript non attivati e sono esclusi dai dati,pero' formano la Log Quota lo stesso e sono 500 indirizzi unici,nel breve arco temporale.
Qui sono sistemate le Exit Page
Il dato dei 2 giorni è nella prima immagine di questo passaggio e sono i codici Javascript attivati e in questo Caso,ne sono 496 e significa che gli indirizzi unici sono reali e poi esistono 4 codici Javascript non attivati e sono esclusi dai dati,pero' formano la Log Quota lo stesso e sono 500 indirizzi unici,nel breve arco temporale.
Per le Exit Page ,insieme a tanto altro,le descrizioni sono nelle pubblicazioni precedenti (il collegamento è nella sidebar ,attraverso il piccolo background) e il riferimento sono le pagine in uscita dal dominio,oppure possono essere scelte altre pubblicazioni nello stesso spazio e saranno lo stesso classificate come Exit Page.

E' anche all'interno dei Bounce e delle Exit Page e naturalmente,la sua presenza ha un senso pieno,pero' solo nei rilevamenti di base:)
Tra le esclusioni dei filtri esiste anche "Town / City" e non riguarda la posizione individuale,perche' è esclusa a priori,ma ha come riferimento la mia geolocalizzazione fisica e gli eventuali indirizzi presenti,sono esclusi lo stesso:)
L'unione con Unnatural Developer è davvero fantastica,perche' ,con tutto il rispetto per il TFD Statcounter,si preoccupano dei Match che possono avere gli URL e hanno dimenticato completamente i conflitti delle pubblicazioni :) (questa posizione,è presente in qualsiasi rilevamento di base e al massimo ,utilizzano nomi diversi:)
 La posizione sopra è altrettanto fantastica e anch'essa è parte di Unnatural Developer Dati Now:)
La posizione sopra è altrettanto fantastica e anch'essa è parte di Unnatural Developer Dati Now:)
La collocazione è nelle Exit Page ,pero' è anche all'interno dei Bounce e delle Entry Page e l'inizio è davvero straordinario:)
All Visits,dovrebbe comprendere tutte le posizioni sopra (potrebbe essere compresa anche la Paid Traffic se fosse attivata:) ,mentre in realta' esistono solo esclusioni e quelle piu' demenziali sono i social network:)
 Per i social network sono tante le posizioni e l'immagine sopra ne è UNA
Per i social network sono tante le posizioni e l'immagine sopra ne è UNA
Le descrizioni sono anche in Unnatural Developer Dati Now e posso anticipare un altra unione e sono le Ads di facebook:)
 E' proprio Audience Network l'unione dei social:)
E' proprio Audience Network l'unione dei social:)
La sua posizione reale è decisamente scarsa,ed esistono notevoli probabilita' che i dati non derivino nemmeno dal loro "lavoro":)
La protagonista del 71° RF ha un percorso completamente diverso!:)



Nei dati non sono compresi gli Engines,semplicemente perche' non sono attivati :)
In realta'i dati esistono e da SEP 18 2020 inizia il ciclo del K2 per i termini in Just Time:) (nelle Sync Google Keywords non ne è compreso nemmeno 1 semplicemente perche' non sono attivate:)