Questa è una comparazione meravigliosa e il suo senso concreto è possibile applicarlo a qualsiasi settore:)
Nel Caso specifico,diventa la migliore evidenza,rispetto alle idee dei Top Imbecilli ;di Davide Casaleggio ;della comunicazione tradizionale italiana e anche degli High learning geolocalizzati e la base comune deriva dal fatto che i dati reali della rete italiana,sono in "Complete Ignore":)
I termini sopra possono avere tantissime applicazioni e solo per le categorie economiche ,le differenze sono notevoli rispetto allo "strombazzato Made in Italy":)
La migliore lezione è arrivata dall'Olimpo del Marketing,attraverso le pubblicazioni dedicate al TFD Coca-Cola e i contenuti sono nella pagina dei Top Friend Din:)
La sezione è "il Vital" e gli elementi sistemati,in qualsiasi sezione,appartengono "ai migliori ottimizzatori",ovviamente "solo secondo le loro opinioni":)
Hanno messo i backlinks come "primo fattore vitale",ed è una posizione facilissima da verificare in tantissimi altri domini seo:)
La parte fantastica è quella evidenziata e cioe' non esiste nessun links che possa risolvere i "poor quality content" oppure "modificare le basse rilevanze" dei content stessi e la posizione è anche normale e inizia dai Thin Content e il loro primo riferimento sono le "basse Quantita",ed è un elemento fondamentale del Natural Contest:) (cioe' per avere dei Match validi,occorre avere minimo 2000 termini effettivi).
L'altra ragione semplice ,deriva dal fatto che i Backlinks,sono Ignorati dalle linee guida e quindi non hanno nessun ruolo attivo reale:)
Fatta questa premessa,è possibile unire i dati dei links per i 3 termini dello snippet e la loro regolarita',inizia dal contesto naturale e cioe' non derivano da nessuno schema e termina con la regolarita' dei loro Content,perche' negli INDEX,la presenza della Quality e Quantita' ,sono strettamente necessarie:)
Nello snippet ho sistemato i 3 termini,eliminando il TLD .IT ,mentre l'operazione inversa (senza il Dash) produce circa 600000 links e tra di essi,uniti ai 3 termini,sono presenti quasi tutti gli High Learning italiani che sistemero' tra un po' e iniziano da UNIBO:)
Qui è sistemata la pubblicazione diretta ,in cui è sistemata l'immagine completaAppartiene sempre ai collegamenti del Brain Stone e i contenuti dell'immagine sono pertinenti anche in questa posizione e avranno tantissimi altri sviluppi,ad iniziare dalla pubblicazione ufficiale di OCT 2020:)
Riguarda i Crawler stessi di qualsiasi contenuto e le prime 2 righe sono spettacolari:)
L'unione con i Backlinks è molto semplice,perche' indirettamente è evidenziata la vera operativita',ed è la coglioneria degli imbecilli:)
Il "Crawling Process" ,per qualsiasi dominio del contesto globale,inizia dagli indirizzi precedenti ,presenti "nei ricordi dei cari Crawler" e questo metodo "non è legato a nessuna tradizione informatica" ,ma solo alla totale assenza di fiducia,verso "l'onesta dei webmasters":)
Iniziano dagli indirizzi precedenti dei Crawling Process,solo per un motivo semplice,ed è la verifica dell'originalita' dei periodi,ed è una posizione fondamentale,per evitare i tantissimi EDITS e tra di essi,esistono anche i Backlinks:)
Questa posizione la utilizzero' per inserire un altra sezione dei Brain Stone e sara' unita "a un termine leggendario" nel contesto online,ed è AVOID:)
E' sistemato dappertutto nei contenuti seo e ,rispetto "alla loro migliore tradizione",non hanno nessun valore reale:)
Se fosse operativo realmente l'AVOID,non esisterebbe il passaggio sopra,perche' diventerebbe inutile vedere gli indirizzi dei Crawling Process precedenti,grazie all'AVOID:)
E' fantastica anche la prosecuzione delle 2 righe selezionate per i "Fundamentals Search",perche' se fossero presenti gli AVOID non esisterebbe nemmeno la necessita' di conoscere "gli sviluppi dei website",semplicemente perche' i contenuti sono diversi,rispetto alle selezioni precedenti dei Crawling Process.
La posizione della Sitemap,nei "Fundamentals Search",è fantastica anche se esistessero posizioni regolari ,semplicemente perche' la sua presenza "non è affatto scontata" e quindi difficilmente potra essere unita agli sviluppi dei contenuti,rispetto a qualsiasi dominio. (nella realta' sono maggiori le presenze dei NoFollow Links IN e degli Internal Links OUT e la loro operativita' è proprio opposta alla Sitemap:)
Nei Just Time esistono anche altri termini rilevantissimi e le posizioni sono descritte nella stessa pubblicazione
dei Fundamentals Search e contiene anche le descrizioni dei Brain Stone e rispetto a questa pubblicazione,al suo interno sono presenti anche gli High Learning,con una differenza notevole,rispetto a quelli che sistemero'tra un po': negli High Learning italiani,ci sara' anche il "Signor Nunzio" con i suoi "Rankings" e formano la base di tutti gli organi d'informazione tradizionali italiani:)
Se non fosse una cosa seria,ci sarebbe da "schiattare dal ridere" ,per le cazzate monumentali ,scritte da idioti per loro simili:)
La diversita' dei dati deriva da un fattore semplice,ed è il RATING dei fattori reali e non per la presenza di Google,ma per la "SEMPLICE LOGICA":)
La logica inizia proprio dallo snippet sopra:
E' sufficente vedere solo il primo passaggio degli Snippet ,per comprendere la logica e inizia dall'unico Match positivo e cioe' ,chi dovesse ottimizzare gli snippet o crearseli in proprio,deve possedere gli stessi termini e non è un affermazione banale,perche' anche in questa posizione esiste la logica,ed è semplice,perche' è molto probabile trovare termini diversi rispetto alle pubblicazioni originali e ovviamente verranno scelti i termini piu' rilevanti:) (possono essere sistemati solo se appartengono realmente al dominio originale in cui sono sistemati i termini:)
Questa è un altra posizione meravigliosa per i Just Time:)
Non posso sistemarle tutte,pero' alcune mancate presenze le sistemero' e la loro base è proprio la rilevanza dei termini e quindi,rappresentano anche la migliore verifica per i termini effettivi e lo sono anche rispetto ai dati delle verifiche stesse,peri contenuti interni dei domini:)
In questo Caso,il miglior suggerimento arriva dal primo Engine dell'universo (tra l'altro,sono presenti anche negli altri Engines:)
Inizia dalle notevoli differenze dei volumi e poi è arrivata una gradita sopresa:)
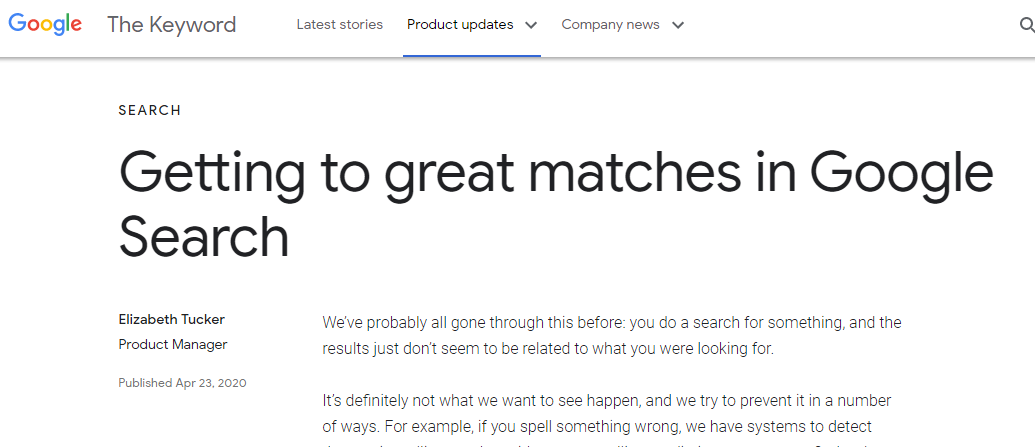
E' sufficente vedere la rilevanza dei termini e posso assicurare che è elevatissima,sia nella combinazione da 4 termini e in quella da 3,pero' sono diversi i reports finali e l'immagine del TFD Google the Keyword,indica una soluzione semplice e cioe' i dati sono esatti,pero' i Content non sono adeguati ai termini della Query e il senso finale è molto semplice,perche' non saranno nemmeno uniti allo IoT:)
Questo è il motivo reale della scelta di Google e la posizione è nata ad Apr 2020 e all'inizio era riservata solo ad USA,mentre attualmente è in WorldWide:)
La verifica migliore sara' quella degli archi temporali,perche' i termini sistemati sono rilevantissimi,pero' non sono "adeguati i content collegati" e quindi è molto probabile "che esistano delle fluttuazioni" :)
E' Researchgate il dominio con i Tips di "Index Keyword Unit" e naturalmente,anche il dominio specifico ,deve possedere tutto il percorso completo,altrimenti non avrebbe nessun dato e nel suo Caso,è meglio non modificare i Content,perche' non migliorerebbe nessuna posizione,ma andrebbe direttamente nelle fluttuazioni:)
Anche questi termini sono spettacolari e nel contesto online,sono di primaria importanza e quindi non occorre nemmeno vedere i volumi dei domini a cui appartengono,perche' è inevitabile che sia elevata la sua presenza:)
Il dominio individuale è secondo e anche il primo ha avuto lo stesso percorso e di sicuro possiede ilsuo Main Content e non ha Copied interni al dominio,altrimenti non sarebbe in quella posizione:)
Esiste un aspetto fantastico unito ai 3 termini e sono sempre gli archi temporali a determinarlo e la differenza è formata da quasi 3 anni,in favore del primo dominio (AUG 2020) e quindi,i contenuti individuali hanno dovuto superare ostacoli molto piu' elevati ,ad iniziare dai contenuti interni del dominio:)
Comunque,per i fantastici 3 termini dello snippet non esiste nessun Tips e di conseguenza i contenuti sono adeguati completamente ai 3 termini rilevantissimi e sara'molto difficile che abbiano delle fluttuazioni:)
Anche questi sono 3 termini rilevantissimi e il dominio individuale è alla 5° posizione e nessuno dei domini presenti ha alcun Tips e quindi i content hanno dati esatti e sono anche adeguati ,rispetto ai rilevantissimi termini:)
Da parte mia posso solo aggiungere di essere l'unico presente con il Detect Language italiano e le altre presenze derivano solo dal primo:)
Ho sistemato questa posizione per aggiungere alcuni particolari:
inizio dal primo dominio,ed è dedicato prevalentemente ad immagini e sara'molto utile per le successive pubblicazioni,perche' ci saranno anche gli INDEX specifici e per le immagini e i grafici ,l'aspetto piu' importante non saranno i vari formati degli INDEX,ma la sua premessa:)
Il senso è molto semplice,perche' le immagini e i grafici,hanno valore solo se esistono dei termini effettivi e non hanno nessun valore per gli INDEX,quelli eventualmente scritti nelle immagini o nei grafici.
In questo Caso esiste un esempio diretto nel primo dominio dei 3 termini e non possiede nessun Tips e quindi i contenuti sono adeguati e i termini utilizzati non sono scritti sulle immagini,ma esistono dei testi reali e la posizione è molto importante,perche' capovolge completamente "un luogo comune,unito al termine VIRALE":)
In genere viene utilizzato solo per i video e non si è mai "sentito che sia virale un immagine" e questa posizione fa' parte dei "Tanti Ignore" sui dati effettivi e sono assai simili ai contenuti degli autori celebri":)
Cioe' si danno per scontato delle posizioni,che nella realta' non esistono proprio (gli autori celebri non conoscono nemmeno quello che hanno scritto loro e quindi figurarsi quale puo essere la conoscenza reale degli utenti:) e questo contesto,ha la migliore evidenza proprio nelle immagini e solo considerando quelle di Google raggiungono il 30% del Market Share,mentre il"Virale dei video",arriva appena al 3% e laposizione non ènemmeno definitiva,perche' le violazioni nei copyright dei video sono esponenziali ed è l'unica percentuale superiore che hanno rispetto alle immagini:)
Quindi esiste anche la logica per il Market Share unico ,perche'le immagini derivano sempre dai termini e il loro 30% è possibile unirlo al resto degli INDEX,ed è formato solo da termini effettivi e raggiungono il 94%,solo per Google (il secondo ha il 3%,ed è il powered della Microsoft e chi pensa di fare meglio,ha solo la qualifica di idiota totale:)
Per evidenziare meglio questa posizione,ho aggiunto 1 termine unico speciale,ed è "Quality":)
E' davvero speciale la sua posizione,perche' è tra i termini piu' rilevanti in assoluto e la sua eventuale collocazione,determina per forza la qualita' dei content,ad iniziare dalla rilevanza oggettiva che possiede:)
Quello riservato alle immagini o ai grafici ha la stessa impostazione,pero' è diversa l'introduzione iniziale,ed è riservata solo ai termini,uniti alle immagini:)
Al suo interno esistono anche le pubblicazioni precedenti degli High Learning italiani .
Dai collegamenti derivano anche le presenze dei domini e prima di sistemarli,aggiungo alcune unioni rispetto ai passaggi precedenti e il loro senso è a sua volta unito all'Ignore Totale:)
Per "Egregious Violation" e "Deprecated Intent" esistono gia'le descrizioni e anche loro possono essere uniti ai contenuti che seguiranno e ho scelto la soluzione piu' semplice (quella dei social network) ,perche' è all'interno di tutti i dati sballati e iniziano "dalla piattaforma stessa":)
Era gia'una posizione fantastica quella del TFD Stacounter ,perche' sono maggiori le parti eliminate,semplicemente perche' non sono attivate,ad iniziare dai Tags stessi (al loro interno esistono anche i titoli delle pubblicazioni e sono eliminati a loro volta ,perche' la non attivazione dei Tags è nello strumento e anche nelle impostazioni individuali da sempre).
I Search Engine non sono attivati e i social network non hanno nessuna presenza nei domini individuali:).
Mi è venuta la curiosita' di conoscere le loro eventuali posizioni e tra le prime risposte è arrivata l'immagine sopra:)
Avevo sistemato da pochissimo tempo,proprio l'Audience Network di Facebook per le Ads e la comparazione è avvenuta con Baidu e sono uno peggio dell'altro:)
La posizione di facebook non mi ha sorpeso,nonostante fosse cosi' scarsa,perche' ha un CTR da schifo e quindi non avrebbe potuto fare meglio e tra l'altro è poco probabile che i dati siano anche suoi:) (probabilmente esiste il lavoro degli Engines :)
La migliore dimostrazione è in quest'immagine e gli Istant Articles sono nati nel 2015 e l'unione con le Ads è molto semplice e sono dei contenuti a pagamento,per un massimo di 350 termini:)
Questi sono i dati reali in 1 anno e nel grafico sopra non sono inseriti "i dati dopati" e "gli articoli istantanei" ,servono proprio a questo:)
Altro che Facebook developer,sono del tutto Unnatural ad iniziare dai dati stessi che inseriscono,perche' esiste la logica stessa e non sono le Ads ad avere valore rispetto ai content,ma è l'opposto:)
La logica è semplice,perche' devono esistere dei valori ,per unire le Ads,altrimenti non esiste nessun idiota disposto a pagare e con 350 termini effettivi,non si puo creare nessun valore reale:).
Ovviamente ,se hanno fatto questa scelta,una logica esiste e anch'essa è Unnatural e nel contesto tradizionale,assomiglierebbe tanto all'Insider Trading:)
Solo per questo motivo esistono le Ads unite agli "Articoli Istantanei" e cioe' per cercare di aumentare la posizione delle Ads stesse all'interno di facebook e solo per questo motivo sono disposti a pagare ,altri idioti come loro:)
E' in realta' una forma di Dumping ,pero' al suo interno ha un pericoloso "effetto boomerang" ,perche' queste operazioni sono state fatte,almeno dal 2015 e i dati dopati,delle Ads di facebook,sono di anno in anno ,sempre peggiori rispetto ai precedenti:)
Per il momento mi fermo qui con il passaggio specifico e cito solo l'unione con le Toxic Data e sono tutti gli elementi degli High learning italiani che sistemero' tra un po' ,semplicemente perche' i dati maggiori (tra quelli pubblicizzati) arrivano dal contesto appena descritto ,ed è formato dall'idiozia assoluta:)
Hanno "un oceano di utenti"; esiste 1 solo dominio per 1 piattaforma; la realta' delle loro Ads è quella appena descritta e cioe' hanno "in realta' barato sui dati" e la somma finale ,risulta scarsa anche rispetto a Baidu:)
Questa è una soluzione reale dell'Ignore e riguarda tutti i dati di Alexa,semplicemente perche' non esiste nessuna logica,ad iniziare dal fatto piu' banale e cioe' non conosce i dati reali ,nemmeno per se stessa:)
Le posizioni appena sistemate hanno tantissime unioni con i domini che inseriro' e altrettante presenze sono nel sistema dedicato ai Social Marketing e il motivo è molto semplice e non deriva solo dalla Non Conoscenza dei dati effettivi ,ma dal ruolo specifico di questo mezzo e a differenza delle apparenze,non è affatto virtuale,ma è uno "specchio ad altissima fedelta" e i suoi dati sono scritti in questa pubblicazione:)
Esistono tantissimi imbecilli e sperano che abbiano qualche valore i dati degli idioti come loro:)
Nello stesso tempo esistono tante persone intelligenti,ed è sufficente vedere il Detect language italiano e se hanno raggiunto il livello dei loro INDEX,il Natural Brain è per forza di cose,presente:) (gli autori celebri tradizionali,nemmeno ad anni luce,hanno le selezioni degli INDEX per i contenuti in lingua italiana:)
Per festeggiare l'ingresso della Sitemap nel Frame Global Limit ,utilizzo "i danni degli altri domini":)
Quella sistemata nell'immagine è la prima pubblicazione nei duplicati per il numero di termini in Match,del dominio ufficiale di Traccani:)
Se avessero valore i dati Toxic ,sarebbero davvero molto felici a Treccani e l'unico problema è che non avrebbero nessun valore nemmeno loro:)
Nel contesto tradizionale,le cose erano diverse,perche' esisteva "l'Ignore Istituzionale" e quindi, anche Treccani "sembrava una fonte attendibile":)
Non possiede nessuna Sitemap Treccani e quindi gli Internal Links OUT del Main Menu sono operativi e naturalmente riguardano 1 sola pubblicazione,tra le selezionate e quindi è probabile che nel dominio completo esistano dati peggiori:)
L'immagine non è eccellente,ed è anche parziale,perche' le dimensioni effettive del dominio raggiungono le 60000 pubblicazioni.
Comunque i dati sistemati sono importanti (oltre 13000 pubblicazioni) e l'immagine rappresenta la disposizione dei contenuti nel dominio e senza Sitemap,è difficile immaginare che derivino da una collocazione naturale:)
Questa è la prima pubblicazione nei duplicati di Unibo ed ha 101 Internal Links OUT e i suoi contenuti sono formati da 125 pubblicazioni ed ha raggiunto il 36% di unicita con un average di 722 termini effettivi.
Le condizioni sono uguali per tutti e cioe' 1 pubblicazione in 1 pagina e sono esclusi i menu principali e quelli di navigazione.
Occorre aggiungere anche un altro particolare,simile ai Major Engine e cioe' lo strumento è capace di leggere anche i Text e i Links in Hiden e sono quelli "non visibili dagli utenti":)
Per Unibo non conosco se esistono e comunque,per l'istituto bolognese,non cambierebbe tanto,perche' i suoi dati sono scarsi anche "in maniera naturale":)
Questi sono i primi duplicati per SNS e sono 101 i Links OUT Internal presenti e naturalmente è possibile che esistano dei NoFollow Links IN e anche loro hanno la stessa funzione e cioe' di bloccare i Crawling Process:)
Per gli autori del Detect Language italiano,queste operazioni non sono state fatte,perche' non sarebbero negli INDEX:)
Per SNS sono state presenti 245 pubblicazioni e hanno raggiunto il 32% ,con un average da Poor Quality Content:) (849 termini effettivi:)
Gli High Learning hanno il massimo rispetto,pero' debbono dimostrarlo e servono i dati veri e non nascono dal QS Rankings del "Signor Nunzio":)
Questa è Sant'Amma Pisa e nel suo primo duplicato,per il numero dei termini presenti,ha 185 Internal Links OUT e sono "operativi":)
Di sicuro non hanno fornito "un grande contributo" ai Content del Detect Language italiano:)
Sono 135 le sue pubblicazioni presenti e hanno raggiunto il 31% in unicita' e l'average è formato da 1241 termini effettivi.
Questa è Bicocca e nelle precedenti pubblicazioni esistono anche i motivi della sua presenza e sono dovuti a dei Match Fantastici:)
In questa posizione ha 128 Internal Links OUT e la pubblicazione è la prima nei duplicati perilnumerodei termini.
Sono 229 le pubblicazioni presenti per Bicocca e ha raggiunto il 29%,pero'il suo average è assai maggiore,rispetto alle altre presenze,ed è formato da 1825 termini effettivi.
Questo è il Politecnico di Milano e secondo "il Ranking del Signor Nunzio,in Arte QS" è il primo in Italia:)
Sono 229 le sue pubblicazioni ed ha raggiunto il 17% con 603 termini effettivi in average:)
per Accademia della Crusca ho un grande affetto,perche'èstato "il primo compagno di viaggio" e la posizione è nata per un altro Match e non è stata una pubblicazione generica,ma è quella dedicata alla Natural Search ed è la 3° Top Page Joy,in ordine solo temporale:)
Ha 139 Links OUT e le pubblicazioni di Accademia della Crusca sono state 236 e 1513 è stato il suo average e ha raggiunto il 39%:)
Questo è il DIS ,ed è il dipartimento di scienza informatica della Sapienza di Roma:)
Sono posizioni davvero fantastiche e diverse descrizioni sono all'interno di FEB 2020,collegato sopra:)
Esistono delle curiosita' davvero interessanti e la mia preferita,è "l'etica applicata al Link Building":) (in realta' fa' solo parte dei Deprecated Intent e delleToxic Data:)
le pubblicazioni del DIS sono state 228 e il loro average è formato da 693 termini effettivi.
Questo è il professor Navigli e insegna al DIS e si occupa di Natural Lnaguege :)
Non inserisco gli altri dati perche' è un "collega di piattaforma" e cito solo le pubblicazioni presenti e sono state 215:)