Legitimate Publishers Unique Value 🎆🥂HB Just Time🥂🎆
Legitimate Publishers Unique Value, è il nome scelto per festeggiare i Just Time e i contenuti di questa pubblicazione aiuteranno a comprendere i motivi della scelta:)
Indirettamente sono gia' descritti nella data della nascita stessa dei Just Time,perche' sono arrivati esattamente 1 mese dopo il primo Frame Global Limit operativo (AGU 2018),nato grazie "alla monotematicita' dei contenuti" (senza saperlo nell'anno 2018 stavo descrivendo i Main Content :) e i Just Time successivi hanno creato l'unione,rispetto alla posizione originale del Frame Global Limit stesso,ed era quella dei Links Juice e dei Link Equity:)
Significa semplicemente Pertinenza dei Contenuti (Link Equity) e Natural Links (è il senso di Juice),pero' a JAN 2018 esisteva "un Grande Problema" ed è anche Attuale,ed è formato dalla Credibility stessa rispetto a Tutte le Operazioni (attualmente sono quelle dei SEV,dedicate alla Search Egregious Violation:) e quindi è stato Naturale che dopo il Frame Global Limit,nascessero i Just Time,perche' sono le uniche posizioni Compatibili con la Credibility rispetto ai Dati Veri:)
I Just Time sono nati proprio per questo motivo e la "loro traduzione operativa attuale" è decisamente la migliore per rendere Equity i termini scelti per festeggiare i Just Time stessi ,ed è il Legitimate Publishers Unique Value:)
Il Legitimate Publishers Unique Value,significano le posizioni sopra e in questo contesto,l'elemento piu' Divertente da unire alla festa dei Just Time,sono le Policies dell'Honest Result:)
Questo è il senso dell'Honest Result,ed è valido per CHIUNQUE ,comprese le "grandi organizzazioni" ;i piu' "grandi High Learning"; e sopratutto gli Elementi piu' Divertenti e sono le Grandi aziende Enterprise,semplicemente perche' hanno piu' denaro da spendere e quasi sempre lo fanno anche attraverso elementi piu' idioti di loro (sono gli operatori SEV:) e l'affermazione è anche Equity e cioe Pertinente,perche' esiste il costo del Content Marketing e solo le grandi aziende Enterprise sono capaci di sostenere i costi:)
Nonostante la larga disponibilita economica,per "le povere aziende Enterprise" esiste "l'ostacolo dell'Onesta" e puo essere definito anche "l'ostacolo della Logica",perche' senza i Legitimate Publishers,non esisterebbe proprio nessuna Ricerca,rispetto a qualsiasi Categoria e quindi non si potrebbe vendere nessuna Ads:)
Per questo motivo esiste il Report dell'Onesta o della Logica e cioe' i Dati Veri,ed è possibile arrivarci solo attraverso il Demonstrate Juice Data Archive e il riferimento sono esclusivamente i Content Effettivi e tutte le altre operazioni successive,appartengono solo alla Teoria,semplicemente perche' non esiste proprio la Compliance con la Credibility:)
Indirettamente la Compliance della Credibility è gia scritta nei termini festeggiati di questo Just Time DCE1 K5 e in maniera particolare lo possiedono gli Original Unique e Content Value,grazie alla loro elevatissima rilevanza e quindi grazie anche ai termini effettivi che li hanno sostenuti e il riferimento sono sempre le Proposte Complessive e quindi i termini festeggiati,rappresentano una Verifica Generale,rispetto a qualsiasi altro reports,grazie solo alla loro Esistenza:)
Questa sara' la prima pubblicazione finale,dedicata ai festeggiamenti del DCE1 K5 dei Just Time e sono presenti solo degli esempi,in funzione delle Demo Data e cioe' delle combinazioni che possono avere i termini e occorre ricordare che le Demo Data sono formate anche da tutte le Close Variants e derivano sempre dai termini effettivi sistemati,naturalmente tranne quelli in Duplicato e quindi è facile avere anche i dati delle Close Variants,sopratutto quando si possiedono le Alte Rilevanze,perche' è sicuro che nelle Proposte Complessive (sono loro a formare i Dati Veri:) è presente la percentuale minore possibile di Duplicati,altrimenti non esisterebbero proprio le Alte Rilevanze e attraverso la loro presenza,diventa sicuro anche il valore dei termini effettivi che li hanno sostenuti,perche' avere le Alte Rilevanze,significa possedere anche un elevatissimo numero di Match e quindi sono elevate anche le probabilita' di avere tante combinazioni dalle Demo Data,grazie ai fantastici termini effettivi che hanno sostenuto i conflitti:)
Ho descritto questa posizione perche' gia esistono tanti altri esempi da unire alla pubblicazione finale di questo Just Time DCE1 K5 (sara' quella dopo il prossimo FGL SEP 2025),oltre a tutti i dati sistemati in 1 anno e posso assicurare che non esiste nessuna combinazione che abbia raggiunto il volume di Original Unique e Content Value,tranne UNA,ed è proprio quella dei Just Time:)
Sara nella pubblicazione finale del DCE1 K5 e posso garantire al 100% che a SEP 2018,quando ho scelto i termini per queste pubblicazioni,ho seguito solo l'idea originale da cui sono nati i Just Time,senza nessuna Preoccupazione rispetto alla rilevanza dei termini e cioe' non la conoscevo proprio:)
L'idea originale è nata dalle operazioni del Just in Time,rispetto a tante industrie del contesto tradizionale (il Just in Time è utilizzato sopratutto nelle industri automobilistiche) e significa semplicemente "ricevere i prodotti nel Tempo Giusto",pero' esiste un Grande Problema,ed è unito al potere economico,perche' il Just in Time è deciso dalle Grandi Aziende,nei confronti di quelle minori e cioe' il "vantaggio del Just in Time" è solo per le grandi aziende,grazie al fatto che sono quelle minori a fare magazzino.(sono facili da ricattare,grazie solo al potere economico)
Questa era l'idea originale da cui sono nati i termini dei Just Time e non è casuale il fatto che siano arrivati subito dopo il Frame Global Limit,perche' i Link Juice e i Link Equity,assomigliano tantissimo alle operazioni del Just in Time,rispetto alle industrie del contesto tradizionale e cioe' di "fornire dei vantaggi" nel tempo giusto:)
Nel contesto online il Just Time è completamente diverso e solo gli operatori SEV immaginano e sopratutto sperano,che esista il Just in Time tradizionale e ad esempio Moz e tanti altri SEV lo chiamano Inbound Links e sarebbe il Just in Time tradizionale e cioe trovare tanti idioti,disposti a dare vantaggi ad altri idioti come loro,"in posizione Juice" (cioe' debbono essere naturali i vantaggi:) e nella "posizione Equity" e cioe' i vantaggi forniti debbono anche essere pertinenti,rispetto ai contenuti a cui si fornisce il vantaggio e quindi sono anche dei Competitors,rispetto agli "astuti segnalatori" e tutte le operazioni possono essere fatte solo in Dofollow (attraverso i NOFOLLOW non si ha nessun vantaggio:)
Nel contesto online,la Logica delle operazioni è uguale a ZERO e altrettanto lo è la Credibility delle operazioni stesse (sono solo dei banali Schemes in realta:) e per questo motivo è nato il Frame Global Limit e subito dopo sono nati i Just Time del contesto online,completamente opposti a quelli tradizionali,grazie all'elemento specifico dei Just Time stessi e sono le Alte Rilevanze e cioe' quelle che vorrebbero realmente avere i tantissimi contestatori,ed è facile intuire che prevalentemente sono le grandi aziende Enteprise,per il motivo piu' semplice,perche' anche le Contestazioni e le Litigation,hanno costi elevatissimi,difficili da sostenere da "Ordinary People":)
Questa è la posizione piu' bella dell'intero contesto online,ed è formata "dagli Ordinary People" e cioe' tutti gli autori che non hanno "la potenza economica" da unire ai Just in Time del contesto tradizionale:)
Qualsiasi autore e il suo dominio,puo arrivare agli Highest Rating,a prescindere dalle informazioni sulla Reputation e cioe' possono essere anche degli High Learning;delle grandi Aziende Enterprise;degli autori famosi ETC e la loro "posizione informativa" non possiede nessun valore,se non dovesse esistere il Demonstrate Juice Data Archive e cioe' l'unico percorso per arrivare all'Highest Rating:)
Rispetto al contesto tradizionale del business,la posizione delle General Guidelines,sembra "Science Fiction allo stato puro",mentre possiede una LOGICA Fantastica,ed è quella del Legitimate Publishers Unique Value e cioe' del Report dell'Onesta e quindi anche della Logica,ed è l'unica posizione a permettere di Vendere le Ads e non i Risultati della Ricerca:)
Gli operatori SEV e sopratutto i simpatici utenti che li pagano (prevalentemente sono formati da aziende Enteprise) vorrebbero fare "esattamente il contrario" e cioe' Decidere gli Utenti e sopratutto Decidere il Business e quindi Decidere la Ricerca e le Ads o i Prodotti e qualsiasi altro servizio:)
Sono queste le operazioni reali che vorrebbero fare gli operatori SEV,insieme ai loro simpatici utenti,ed è sufficente solo unire le loro sezioni operative per comprenderlo:)
Queste sono le sezioni operative,ed è facile comprendere lo scopo delle medesime,ed è quello di "Decidere la Ricerca" e quindi anche quello di Decidere il Business (i link building insieme a tutti gli Unnatural,servono proprio a questo scopo:) e per farlo è indispensabile avere una potenza economica elevatissima,perche' occorre sostenere i costi delle ottimizzazioni,Custom CMS compreso,insieme ai costi altrettanto elevati delle Contestazioni e delle Litigation:)
In pratica esiste il sistema del Just in Time del contesto tradizionale del Business e posso assicurare che a SEP 2018, i termini mi sono venuti in mente proprio per questo motivo e cioe' era la scelta migliore da unire alle idee originali del Frame Global Limit a loro volta nati dalla "Scarsissima Credibility" (ho virgolettato i termini perche' in realta' la Credibility stessa è sotto lo ZERO:) nei confronti dei Links Equity (Pertinenza dei Content) e dei Links Juice e cioe' il NATURAL dei collegamenti e sarebbero diventati gli Holy Grail,pero' molto tempo dopo averlo scritto (i Natural Links definiti Holy Grail sono arrivati a DEC 2019:)
Da queste posizioni è stata Naturale la scelta di Legitimate Publishers Unique Value,per festeggiare le pubblicazioni finali del Just Time DCE1 K5,perche' esiste l'unione della Logica rispetto ai Dati Veri,ed è proprio quella del Report dell'Onesta:)
E' l'unica posizione che permette di vendere le Ads,oppure i prodotti e qualsiasi altro servizio,semplicemente perche' esiste il Valore della Ricerca,ed è facile comprendere che senza Ricerca unita a Dati Veri,esisterebbe solo una Super Inflate Data:)
A reggere tutto il sistema sono esclusivamente i Legitimate Publishers e i contenuti che seguiranno,serviranno proprio per rendere palese la sua certificazione:)
Sono tante le posizioni unite alla certificazione del Legitimate Publishers Unique Value e da essa deriva anche il valore unito alle Alte Rilevanze dei Just Time:)
La posizione sopra rappresenta solo l'inizio,pero' possiede un contesto molto Divertente,perche' è presente una delle maggiori aziende Enterprise al mondo e possiede anche "il miglior addestramento possibile" rispetto a qualsiasi Contestazione (la Philip Morris è l'Accademia delle Contestazioni:) .
Il report sopra è di 1 anno fa' e la prima idea è stata quella di vedere l'attualita' e il contesto è sempre quello delle Appliance in Litigation e cioe' sono delle Contestazioni,rispetto a Patent non ancora Approvate e non esiste nemmeno nessuna garanzia che lo saranno in futuro.
E' facile creare l'unione con la certificazione del Legitimate Publishers Unique Value,perche' il business del contesto online è il primo in assoluto che abbia mai avuto tutta la storia umana e tante Patent sono dedicate proprio ad esso,comprese quelle unite alla Philip Morris e il riferimento è il commercio online e quindi i prodotti da cui è composto.
Questa posizione è stata la prima selezionata,per avere la certificazione del Legittimate Publishers Unique Value e la selezione è unita solo all'arco temporale:
Anche questa posizione è unita alla certificazione del Legitimate Publishers Unique Value e quindi anche al valore dei termini di questo Just Time e il contesto è quello fisico delle operazioni stesse e riguarda il consumo di energia elettrica:)
Naturalmente tutte le posizioni sono unite tra di loro e ad esempio,il grafico dell'energia è arrivato grazie al CMS di Philip Morris e in maniera particolare,il grafico dell'energia è arrivato grazie all'homepage attuale di Progress (attraverso Sitefinity è il Custom CMS di Philip Morris e cioe' è una piattaforma ad Alto Costo Aggiunto:) e tra i tanti deliri scritti da Progress,sono presenti anche i generative content:)
Questa posizione mi ha suggerito di sistemare anche il consumo di energia elettrica per arrivare alla certificazione del Legitimate Pubblishers Unique Value,utilizzando solo la Logica e tra un po' si comprendera bene cosa significa:)
Anche questa posizione fornira una garanzia assoluta rispetto al Legitimate Publishers Unique Value,grazie all'aiuto dell'Holy Grail TFD SEC:)
Le posizioni sistemate sono degli esempi,pero' esiste l'operativita' piena,rispetto alla LOGICA dei Dati Veri e possono appartenere solo ai Legitimate Publishers:)
Partendo dalle Appliance in Litigation della grande azienda Enterprise Philip Morris (la definizione di grande azienda è unita solo al livello del Divertimento:) e passando per il suo Custom CMS,visti i contenuti oggettivi che possiedono,avere anche la presenza dei generative content,è diventata pertinente anche la presenza dell'Holy Grail TFD SEC,semplicemente perche' i generative content sono delle bolle speculative e la posizione sopra è il loro Benchmark e cioe' il Top Riferimento rispetto al General Failure:)
Cioe' i generative content esistono solo grazie alla presenza dei Legitimate Publishers,altrimenti non potrebbero fare nemmeno Scraping (lo chiamano Addestramento,mentre è la loro vera attivita,insieme a quella del Paraphrasing:) e quindi è pertinente la presenza dell'energia consumata per "gli inutili calcoli" dei generative content e solo per citare OpenAI,consuma molto piu' energia rispetto a tutte le ricerche e da sola è gia molto vicino al Benchmark del General Failure e per questo motivo esiste anche la presenza dell'Holy Grail TFD SEC,per fornire la garanzia assoluta,rispetto al Report dell'Onesta e cioe' della Logica,ed è quella dei Legitimate Publishers,ed è facile comprendere perche' solo LORO garantiscono anche l'Unique Value:)
Quella appena descritta era la posizione scelta,per festeggiare questo primo Just Time finale unito al percorso del DCE1 K5 e poi è arrivata la Fantasia Infinita del Supreme Case Creator e naturalmente è sempre LEI ad avere il TOP dei Riferimenti e inizia dall'immagine sotto:)
Sono gli Holy Grail Age a festeggiare i termini del Just Time del DCE1 K5 e rappresenta anche la migliore posizione nei confronti del Legitimate Publishers Unique Value,grazie solo alle presenze dei Meravigliosi Coetanei dell'Heroic DIN:)
A differenza delle immagini precedenti,esiste una novita',ed è proprio LEI ad essere unita alla Fantasia Infinita del Supreme Case Creator,perche' tra i Meravigliosi Coetanei,è presente anche la General Guidelines delle Strutture Data e per l'Heroic DIN la Festa è Totale:)
La Fantasia Infinita della Casualita' ha scelto che fosse proprio il Fantastico Rick Result,il piu' vicino coetaneo di questo dominio e sinceramente non mi ero accorto che esisteva anche la posizione sotto,anch'essa nata a JAN 15 2015 :)
Probabilmente la Fantasia Infinita della Casualita',ha scelto che mi accorgessi di questa posizione,proprio in questo contesto,ed è sicuramente il migliore da unire al Legitimate Publisher Unique Value e quindi ai festeggiamenti dei termini di questo Just Time:)
Sono meravigliosi anche i termini utilizzati dall'Holy Grail TFD Google:
inizia da
New Documentation and Simpler Policies
e prosegue con
Simplified and Clarified
la meraviglia dei termini deriva dal contesto stesso in cui sono sistemati,insieme a tutte le altre posizioni descritte,iniziando dal Report dell'Onesta e quindi della Logica,passando dalla vendita delle Ads,mentre la Ricerca non è in Vendita,semplicemente perche' senza la Ricerca e i suoi Dati Veri,sarebbe presente solo la Super Inflate Data e Addio Business online,sia per le Ads;per i Prodotti e per qualsiasi altro servizio:)
Nel Simplified and Clarified,sono presenti proprio le posizioni appena descritte e sono loro a determinare la Meraviglia dei termini Utilizzati e non potrebbe essere in altro modo,perche' sono sistemati tra la nascita del Rick Result e nella stessa pagina,esiste anche la nascita delle General Guidelines delle Strutture Data e il contesto è davvero Super Complesso,insieme al contesto a cui è applicato:)
Questa è la posizione delle General Guidelines delle Strutture Data e nel collegamento sopra,è presente la pagina originale di Jan 15 2015 e vicino a Simplified and Clarified esiste il collegamento delle General Guidelines e l'inizio è il Content Policies di Google Search e tutte queste posizioni hanno avuto tanti Developers nel corso dei 10 anni e il piu' Straordinario è nella nota centrale,perche' le Strutture Data non determinano il Main Content e a JAN 2015 non esisteva proprio e non esisteva nemmeno ad AGU 2018 ,quando è iniziata l'operativita' del Frame Global Limit,attraverso un suo elemento e l'ho denominata la Monotematicita dei Contenuti,semplicemente perche' nel contesto online è oggettivamente impossibile che Esistano i Tuttologi:)
La nota delle General Guidelines è comunque importante,perche' è Vero che le Strutture Data non determinano i Main Content,pero' senza di ESSE,i Match non avrebbero nemmeno l'inizio e questa posizione è utile ricordarla,perche' prima di arrivare a qualsiasi violazione delle Policies,esiste anche il Time Sensitive Content e ufficialmente non è descritta la data in cui è nato,pero' è sufficente la LOGICA per averla,perche' senza Time Sensitive Content,sarebbe inutile l'esistenza del Rich Result e anche delle General Guidelines delle Strutture Data,perche' il Time Sensitive Content significa l'Originalita' dei Contenuti stessi e possono essere scritti SOLO UNA VOLTA e quindi esiste la sicurezza della LOGICA,rispetto all'arco temporale in cui è nato e puo essere solo quello di JAN 15 2015:)
Quindi nella prossima immagine degli Holy Grail Age e cioe' i fantastici coetanei dell'Heroic DIN,sara presente anche il Time Senstive Content,perche' senza l'Original Unique e Content Value è inutile vedere le Policies di Google Search,ed è altrettanto inutile verificare tutte le violazioni delle Spam e per avere un idea di cosa significa,esiste l'evidenza di Enriched Search Result,ed è sistemata proprio sotto alle General Guidelines delle Strutture Data:)
La posizione operativa è molto semplice (Arricchire i Risultati della Ricerca) e la curiosita sono gli operatori stessi che utilizzano l'Enriched Search Result e sono quelli delle Revisioni e poi ne esistono anche tanti altri,pero' i Revisori all'interno degli operatori SEV hanno un Plus di Spam nel loro Brain davvero notevole,rispetto a qualsiasi altro operatore:)
L'unione tra il Time Sensitive Content e l'Enriched Search Result è molto semplice,perche' la prima violazione degli Enriched sono i Duplicate In Elsewhere e l'equilibrio rispetto all'Originalita dei Contenuti (è il Time Sensitive Content per Logica nato anch'esso a JAN 15 2015:) è molto difficile e tutto questo,è utilizzato per dare un vantaggio Equity (debbono essere pertinenti i contenuti) e Juice insieme (debbono essere anche naturali i collegamenti:) attraverso le Revisioni,rispetto a dei domini che sono anche dei loro Competitors e quindi la Credibility delle operazioni è sotto lo ZERO:)
Nell'anno 2015 è nata anche OpenAI e naturalmente non fa' parte degli Holy Grail Age,pero' possiede un contesto molto divertente,rispetto alle posizioni sistemate:)
Tra i piu' curiosi esiste la nascita del Rank Brain ed è OCT 26 2015 e occorre ricordare che è anche LEI un AI,ed è anche la prima in assoluto e quando è nata a OCT 2015 era gia' operativa:)
Esiste un altra curiosita,ed è la nascita del protocollo HTTPS,particolarmente sgradito a OpenAI,perche' rende impossibile "effettuare le sue vere operazioni" e sono esclusivamente quelle dello Scraping,senza nessun valore aggiunto:)
Open AI immagina di arrivare all'AGI (è l'artificial intelligence generale) e rappresenta l'ossessione del suo CEO,pero' in realta' la sua attivita è completamente in perdita e al posto dell'AGI,sta invece raggiungendo il Benchmark del General Failure e per questo motivo esiste la presenza dell'Holy Grail TFD SEC:)
Queste posizioni servono per evidenziare la LOGICA unita al Legitimate Publishers Unique Value e la sintesi generale è nei termini stessi festeggiati in questa prima pubblicazione del Just Time finale del DCE1 K5 e in maniera particolare lo sono i termini sotto:)
L'Original Unique e Content Value è la sintesi generale di tutte le posizioni sistemate e poi esiste anche il Comprehensive Quotes Rating e il riferimento sono proprio le Quality Guidelines,unite alle Strutture Data e naturalmente le posizioni sono sempre degli esempi in funzione delle Demo Data,pero' i Dati sono assolutamente Veri,perche' senza le proposte Complessive,non potrebbero proprio esistere i termini dei Just Time e nemmeno le pubblicazioni degli RF e per comprendere il suo valore,è sufficente utilizzare i costi sostenuti dai simpatici utenti degli operatori SEV e per paradosso è possibile unire anche Open AI,grazie alla sua vicinanza al Benchmark del General Failure e cioe a quanti investimenti economici sono stati fatti,per arrivare ai Dati sopra e di sicuro l'AGI non potra mai arrivarci,perche' "possiede il peccato originale" rispetto a qualsiasi Contenuto,ed è la Mancanza dell'Original Unique e Content Value:)
Per Open AI esiste anche un Plus alla curiosita,perche' l'Holy Grail TFD SEC ha richiesto con insistenza "diverse documentazioni" per verificare il rischio di Failure e non esiste dubbio che è solo una questione di tempo,perche' Open AI continua a perdere "montagne di denaro" per arrivare all'AGI e cioe' al NULLA:) (sarebbe l'artificil intelligence generale,pero' solo secondo l'opinione del CEO di Open AI:)
In questa posizione il Plus della Curiosita è molto semplice,perche' l'Holy Grail TFD SEC non ha ricevuto la documentazione richiesta e il contesto è gia molto particolare di suo (negare alla SEC dei documenti economici è proprio l'ultima cosa da fare,per qualsiasi azienda:) pero' il Plus della Curiosita è unito all'immagine sotto:)
In anni di Esperienza non ho mai ricordato l'Holy Grail TFD SEC,accusare di Scraping un azienda e naturalmente l'accusa è assolutamente Vera,nei confronti di Open AI:)
Queste posizioni aiutano tantissimo nella certificazione del valore unito a Legitimate Publishers e quindi al Report dell'Onesta e cioe a quello della Logica e di conseguenza si hanno anche i valori reali,rispetto ai termini festeggiati e naturalmente sono solo degli esempi,in funzione delle Demo Data,pero' le Alte Rilevanze esistono realmente e di conseguenza diventano esponenziali anche il numero dei Match e per averli,è indispensabile prima superare quelli interni del dominio e poi è indispensabile vincere anche i Match globali e solo da essi arrivano le Demo Data e cioe' i Dati Veri:)
La descrizione delle Demo Data è semplice solo "nella sua formalita operativa",perche' esiste anche il suo contesto operativo,ed è formato dalle dimensioni stesse in cui avvengono i Match e il riferimento è il Volume delle Keywords,insieme al Size e alla categoria in cui sono sistemate:)
Per festeggiare tutte queste posizioni,esiste anche l'arco temporale a cui sono uniti i Match e a parte la sua "amplia relativita"( il riferimento dell'arco temporale sono 10 anni tradizionali,difficilissimo da comparare con gli archi temporali online:) esiste anche un "limite fisico" nei confronti delle Demo Data,ed è formato dal Numero di Violazioni possibili (DUE:) e possono arrivare da qualsiasi Policies,compresi i Fact Check descritti,proprio nel Vero Senso delle Parole:)
Questo è il motivo per cui le Demo Data sono semplici "solo a Descriverle" e lo stesso contesto è valido per i Volumi delle Keywords unite ai Match e anche per il loro Size,sopratutto nella categoria dell'Information Technology:)
Anche i Fact Check sono nella prima posizione delle violazioni,unite ai Duplicati e il contesto è anche normale,perche' non possono esistere Fatti Veri all'interno di Duplicati,pero' è il Volume delle Keywords e i Size a cambiare tutti i valori e rendono molto semplice comprendere quanto sia elevato il valore dei Legitimate Publishers e cioe' dei termini festeggiati in questo primo Just Time finale del DCE 1 K5,grazie anche all'immagine sotto:)
Anche per i Multi Fact Check non cambia NULLA,rispetto alla prima violazione dei Duplicati,pero' la posizione è capace di elevare in maniera esponenziale il valore dei Volumi delle Keywords e quello dei Size,uniti a qualsiasi Contenuto:)
Fino a NOV 2021,esisteva 1 solo Fact Check da poter prelevare,rispetto a qualsiasi pubblicazione,sistemata in qualsiasi dominio e naturalmente il Fact Check da Verificare non era DECISO dagli utenti e per avere le Penalita',unite ai Fact Check,occorreva pochissimo Impegno e anche attualmente è la stessa cosa e cioe' 1 Fatto Falso descritto in 1 pubblicazione,non puo essere ripetuto in nessun altra e dopo l'arrivo dei Multi Fact Check,esiste la stessa posizione (i Fatti Falsi non possono essere ripetuti in altre pubblicazioni) e la differenza è nel Prelievo dei Multi Fact Check e dopo NOV 2021,grazie agli sviluppi tecnici e alle loro applicazioni,è possibile prelevare tutti i Multi Fact Check presenti anche in 1 sola pubblicazione.
Se dovesse esistere 1 solo Fatto Falso,pero' non è ripetuto in nessun altra pubblicazione,i Contenuti sono Eliggibili e significa solo che i Match possono Iniziare,pero' attraverso i Multi Fact Check,il percorso è molto complicato,perche' è sufficente che esista solo 1 altro Fatto Falso nella stessa pubblicazione e potrebbe anche essere diverso dal primo Fact Check trovato e tutta la pubblicazione diventera Ineleggibbile per sempre e questa posizione non è unita all'arco temporale del Developer specifico (ho sistemato NOV 2021 semplicemente perche' è stata la prima volta in cui ho visto i Multi Fact Check)
La pubblicazione è DEC 15 2020 e in quel periodo ancora esisteva 1 solo Fact Check da poter verificare in 1 pubblicazione e molto probabilmente i Multi Fact Check sono arrivati con il MUM o Multitask a MAY 2021,grazie al fatto che per avere Multiple Ricerche (il MUM puo arrivare a 8 ricerche contemporaneamente) è proprio indispensabile conoscere anche i Multi Fact Check che possiedono le pubblicazioni coinvolte nelle Ricerche:)
Gli archi temporali di tutti i Developers rappresentano solo una curiosita,perche' la loro operativita è Piena e Completa e cioe' quando arrivano gli sviluppi,la loro applicazione è anche RETROATTIVA,rispetto agli archi temporali sistemati sopra e cioe' i Fact Check singoli o multipli,sono applicati a qualsiasi pubblicazione,comprese quelle precedenti all'anno 2021:)
La descrizione è molto importante,perche' tutto il contesto,nasce dalla prima Violazione,ed è quella dei Duplicati in Elsewhere e significa Tutti i Contenuti presenti in 1 dominio,compresi gli eventuali Subdomain presenti oppure i Pluri Account e dopo di loro esiste anche l'Elsewhere globale e cioe' la Fundamental Search e solo al termine,se i Content sono validi,sono applicati i Fact Check:)
E' Esattamente questa posizione a determinare il Legitimate Publishers Unique Value,ed esiste anche la LOGICA del Report dell'Onesta e si comprende facilmente perche' esiste l'Unico Valore dei Legittimi Autori,perche' senza di ESSI non esisterebbe nessuna Ricerca e non si potrebbe Vendere nessun Ads;Prodotti e Servizi:)
Questa è la Vera Festa dei Just Time,ed è capace di determinare anche il Legittimo Divertimento,ed è sufficente solo vedere i contenuti degli operatori SEV e a parte i Fatti Falsi in "quantita industriali" che contengono,oggettivamente è molto difficile che riescano solo ad arrivare alla Verifica dei Fact Check:)
Attraverso l'arrivo dei Fact Check nella prima violazione dei Duplicati,diventa molto piu' semplice comprendere il valore delle Demo Data,grazie al Volume delle Keywords;al Size che possiedono; alla categoria in cui sono sistemati i Fact Check e questa posizione rende Legittimo anche il Divertimento,perche' nella stessa categoria esistono anche gli operatori SEV,insieme ai simpaticissimi utenti che li pagano pure e posso assicurare,che dopo un lungo percorso,partendo sempre dai Duplicati in Elsewhere (Match nel proprio dominio;nei subdomain;nei Pluri Account e in tutto il Web:),anche per la Violazione dei Fact Check,prima di arrivare alla loro Verifica,sono presenti anche le posizioni sotto:)
E' sufficente solo unire la categoria IT e anche gli operatori SEV ne fanno parte (esclusa Wikimedia perche' in realta' non appartiene a nessuna categoria:) e si ha anche il Divertimento Legittimo:)
E' sufficente solo immaginare di partire dai Duplicati in Elsewhere e poi attraversare tutte le Spam Policies;i Fantastici FEED (sono gli High Fail Rate,naturalmente se dovessero esistere i Discovery o i Refresh dei contenuti stessi:);occorre attraversare anche le Revisioni (sono gli operatori che immaginano di fornire dei vantaggi,all'interno del sistema descritto:) e poi esiste l'arrivo al Search Quality User Report e al suo interno esistono le posizioni "piu amate" dagli operatori SEV (appartengono sempre alla categoria IT:) e sono I Deceptive;gli Artificial;i Manipulative,oppure è possibile chiamarli Inbound Links e la loro posizione reale è nelle Strategie Sfruttatrici (la definizione è ufficiale:) e tutto questo serve per Arrivare alla Verifica dei Fact Check descritta sopra,assai precaria gia in proprio,sopratutto nella categoria di questi contenuti,semplicemente perche possiedono il piu' elevato numero di fact Check e sono velocissimi anche i loro sviluppi e la loro Main Entity,sono gli Engines stessi e quindi è Legittimo anche il Divertimento e l'unica sua variante è il costo dei servizi:)
Esiste anche questa posizione per i Fact Check,ed è il proprietario del Brevetto e cioe' l'Holy Grail TFD Microsoft:)
La posizione è capace di garantire tanto Divertimento,sopratutto nei confronti di Open AI,perche' a parte i rapporti con l'Holy Grail TFD SEC (giustamente preoccupato grazie all'esperienza della Lekmann Brothers:) quasi sempre non possiede Strutture Date Valide (il Brevetto è dell'Holy Grail TFD Google:),nemmeno rispetto alla Struttura di Open AI stessa e quindi figurarsi la verifica dei Fact Check cosa puo essere:)
Queste posizioni avranno anche altri contenuti e in questo contesto,utilizzo solo la presenza dell'Holy Grail TFD Microsoft per festeggiare i termini di questo Just Time:)
E' il 78° RF a contenere i termini di Origin RF ONE e tra un po' ci sara' anche l'unione con l'Holy Grail TFD Microsoft e posso anticipare che grazie al Brevetto dei Fact Check,le posizioni che seguiranno saranno molto Divertenti:)
Naturalmente in questa pubblicazione non possono essere presenti tutte le selezioni dei termini,perche' sarebbe impossibile anche sistemarli,pero' alcuni dettagli debbono essere proprio presenti:)
Il dettaglio piu' importante è nell'evidenza,perche' è facile intuire che le Alte Rilevanze sono all'interno di periodi normali,senza nessun Tags (sono sistemati come qualsiasi altro termine:),ad iniziare dal fatto che non sono nemmeno abilitati:)
La posizione sopra merita anche un altro dettaglio,perche' i termini specifici sono presenti in centinaia di pubblicazioni:
Esistono altre centinaia di pubblicazioni con dati piu' o meno simili,sempre uniti agli stessi termini (lo sara' anche questa pubblicazione,dopo averla terminata:) pero' è possibile che esista 1 sola Rilevanza in 1 Dominio e naturalmente a decidere le posizioni sono le Proposte Complessive,tramite la posizione dei Fact Check sistemata sopra e cioe' non debbono esistere Duplicati (attraverso 68 termini ripetuti in 1 sola pubblicazione,non è facile che avvenga:) insieme a tutte le altre violazioni possibili,naturalmente se non si è eliminati prima dai Duplicati stessi e alla fine del percorso è possibile avere la verifica anche dei Fatti Descritti e ovviamente possono essere solo Veri:)
Queste posizioni rendono evidente al massimo il valore del Legitimate Publishers attraverso la LOGICA Completa:la prima è quella del Report dell'Onesta,ed è facile comprendere il motivo per cui "la Ricerca non è in Vendita",perche' senza di ESSA non si potrebbe Vendere le Ads;i Prodotti e qualsiasi altro servizio.
Senza Legitimate Publishers esisterebbe solo la Super Inflate Data e la posizione permette di avere anche la LOGICA Completa e deriva semplicemente dalla SUA ASSENZA:) Dopo il percorso sistemato,se un operatore immagina che esistano strategie alternative rispetto ai Dati Veri,l'unica applicazione che puo avere la LOGICA è unita direttamente al Brain dell'operatore e cioe puo esistere solo la Totale Idiozia:)
Tornando alla pubblicazione che contiene i termini di questo Just Time,occorre unire anche il contesto specifico,perche' la pubblicazione è un RF e cioe' "il Padre di tutti i Contenuti" e nel Caso specifico lo è in senso integrale:)
E' il Gold Star degli RF della 5D e tutte le decadi sono importanti,pero' la 5D degli RF è Strepitosa e una sintesi è proprio nel suo nome e in maniera particolare nell'acronimo SEA (Supreme Engine ASS:) e posso assicurare che è anche pertinentissimo:)
La 5D degli RF ha combinazioni incredibili e tutte le posizioni attuali sono nate da LEI,compreso il Frame Global Limit;le Page Solemn;le verifiche interne ai domini e i Just Time stessi:)
La 5D degli RF è nata a JAN 2018 e ha concluso il percorso a DEC 2018 e il suo 55° RF,ha fatto nascere la Page Solem,mentre il 57° RF,possiede l'inizio degli archi temporali dei Just Time stessi e sono formati dalla data della sua pubblicazione,ed è SEP 18 2018:)
Queste posizioni occorre sempre ricordarle,perche' sono proprio loro a formare il Volume delle Keywords e i Size del dominio e il contesto è anche l'unico che permette di arrivare alla Verifica dei Fact Check e naturalmente è importante per qualsiasi categoria,pero' in quella dell'Information Technology lo è in misura assai maggiore,perche' la categoria IT,indirettamente è all'interno di qualsiasi altra,ed è LEI,cioe' la categoria IT a determinare tutti i Valori e il motivo è nell'immagine sotto:)
La 5D degli RF,ha permesso la nascita del Frame Global Limit;delle Page Solemn;delle verifiche interne ai domini,grazie alla Monotematicita' dei Contenuti e sarebbero diventati successivamente i Main Content;ha permesso la nascita dei Just Time e sempre la Straordinaria 5D degli RF,ha permesso anche la nascita della Natural Search:)
A NOV 2018 esisteva solo la LOGICA a sostenerla,perche' dopo le posizioni descritte,per il Frame Global Limit e per i Just Time,è stato normale sistemare anche la Natural Search perche' attraverso le presenze citate non potevano essere presenti i Link Building e tutte le altre operazioni artificiali,rispetto ai Dati Veri:)
Il Sostegno della Logica ha avuto immediatamente anche un "Fantastico Alleato",ed è la Fantasia Infinita della Casualita:)
Questo è stato il Sostegno della Logica e ha permesso anche la nascita del Frame Global Limit e dei Just Time e il senso è nell'immagine sotto:)
Copyscape è la Casa Madre dello strumento delle verifiche e l'avevo utilizzato prima di AGU 2018 tante volte nelle comparazioni,pero' al massimo esistevano 2 pubblicazioni e la Fantasia Infinita della Casualita' ha scelto,proprio la pubblicazione protagonista della Natural Search,ed è proprio quella inserita in Copyscape:)
Il senso di queste posizioni è multiplo e l'unica difficolta è quello di descriverlo e quindi inizio dal senso oggettivo,rispetto alle selezioni sistemate e cioe' il dominio di Accademia della Crusca,non è "Capitato per Caso" ma è arrivato proprio grazie ai Match della pubblicazione protagonista della Natural Search:)
Nell'anno 2018,quando ho visto il dominio presente nei conflitti (era Accademia della Crusca:) al primo Impatto pensavo "che la partita fosse persa",perche' tra le tante possibilita' di avere Match,è andato a capitare proprio il Dominio per antonomasia della lingua italiana:)
Il timore dei Match nei confronti del dominio dell'Accademia della Crusca,insieme a tanti altri spazi presenti (la pubblicazione protagonista della Natural Search possiede oltre 7K termini effettivi e quindi i Match non mancano di sicuro:) è durato pochissimo,perche' la LOGICA,insieme alla Fantasia Infinita della Casualita',aveva il sostegno anche dei Dati sopra e quando sono all'interno dell'Original Unique e Content Value,non esiste nessuno spazio,Accademia della Crusca compresa,che possa dare qualche Preoccupazione:)
Quindi è possibile sistemare il primo senso,rispetto alle posizioni descritte,ed è quello del Legitimate Publishers Unique Value,ed è la stessa posizione che permette di festeggiare anche i Just Time,perche' il senso è lo stesso descritto per Accademia della Crusca e cioe' possono esistere le "grandi organizzazioni";le aziende enterprise con i migliori Custom CMS possibili;possono essere presenti i migliori High Learning,pero' se non possiedono Il DEMONSTRATE rispetto alle Proposte Complessive dei loro contenuti,gli autori potranno avere "tutti i titoli accademici che vogliono",pero' la Partita la perderanno lo stesso e in tanti Casi,non esiste nemmeno l'inizio dei Match:)
Mi dispiace per la simpatica Accademia della Crusca,pero' i suoi Dati Veri sono questi:)
E' un esempio utilissimo a favore del Legitimate Publishers Unique Value e quindi anche dei termini festeggiati in questo primo Just Time finale del DCE1 K5,perche' anche i migliori High Learning,debbono possedere il DEMONSTRATE rispetto alle loro Proposte Complessive e anche Accademia della Crusca "non fa eccezione":)
A parte i Duplicati scarsi,non ho trovato nessuna pubblicazione che avesse una Struttura Data e in questa posizione,non essendo lo strumento un Engine,non significa che le Strutture Data siano Valide o Meno,ma semplicemente non esistono proprio:)
Questa è una posizione fantastica per festeggiare gli Highest Effort Main Content,grazie alle dimensioni a scalare,rispetto alle pubblicazioni del dominio di Accademia della Crusca:)
Arrivano alla 12° posizione,pero' anche questo contesto non possiede nessuna Struttura Data e quindi non esiste nemmeno la sicurezza che i contenuti siano realmente quelli originali e visto che il dominio opera nel contesto online,i simpatici autori e operatori dell'Accademia della Crusca,avrebbero fatto meglio a studiare "il campo operativo specifico":)
Questa è la Class C del dominio specifico e indica che esiste 1 solo IP e quindi tutte le posizioni sono state scelte dagli operatori dello spazio,probabilmente immaginando che nel contesto online esista l'IGNORE,tanto Caro agli operatori dei contenuti tradizionali,ed è sicuro che la simpatica Accademia della Crusca,sia in questo contesto:)
A scalare nelle dimensioni si arriva alla 40° posizione,ed è particolarmente importante in questo contesto,perche' sono sistemate esattamente le dimensioni dell'Average che ha avuto l'attuale Origin RF ONE,pero anche queste pubblicazioni non hanno nessuna Struttura Data e occorre sempre ricordare che il riferimento non è la Validita o Meno delle Strutture,perche' non sono proprio presenti e quindi esiste la sicurezza che il dominio di Accademia della Crusca,pensa seriamente di essere ancora nell'IGNORE dei contenuti tradizionali:)
Nel Contesto Online è possibile che esista solo il Legitimate Publishers Unique Value e per averlo,è indispensabile DIMOSTRARE di possedere Proposte Complessive Valide,unite a 1 solo Main Content,ed è indispensabile unire anche una Struttura Data Valida,perche' occorre anche l'unione dell'Original Unique e Content Value e queste posizioni è possibile averle solo attraverso Content scritti solo UNA VOLTA e se dovessero esistere altre idee,è sufficente scriverle in altre pubblicazioni,naturalmente cercando di fare meno Duplicati Possibili e occorre evitare gli Scraping e i Generative Content,insieme alla presenza di Subdomain (la simpatica Accademia ne ha 8:)
Questo è il numero di Clicks dalla homepage del dominio e quindi gli operatori di Accademia della Crusca,sono "andati a scuola dai SEV",perche' hanno esattamente le stesse impostazioni,in opposizione al Report dell'Onesta e quindi della Logica e di conseguenza sono in opposizione anche ai Legittimi Publishers e se fossero operative le idee di Accademia della Crusca e di tutti i SEV (da questa pubblicazione ne fa parte anche la celebre accademia della bellissima lingua italiana:) è sicuro che esisterebbe il Just in Time operativo del contesto tradizionale e in quello online non puo proprio funzionare,perche' si avrebbe solo una Super Inflate Data:)
Accademia della Crusca non puo proprio partecipare ai Just Time del contesto online,perche' i dati dei Duplicati sono scarsi gia' in proprio;le dimensioni e gli Average delle pubblicazioni sono altrettanto scarse,mentre è elevato il Peso,in un dominio Full Size e non essendo contenta di queste posizioni,ha pensato di aggiungere anche altre violazioni,attraverso un sistema completamente demenziale:esistono Unnatural Links oggettivi (la selezione non è completa pero possiede oltre 5800 pubblicazioni:) in maniera spropositata (3 Clicks per 5800 pubblicazioni:) e tutto questo per unire delle pubblicazioni che non hanno nemmeno la presenza delle Strutture Data e potranno essere piu' o meno valide,pero' almeno debbono essere presenti:)
Queste sono le pubblicazioni selezionate e il numero dei links presenti è quello interno al dominio e quindi per gli Highest Effort Main Content la Festa è Totale,perche' le loro presenze sono state raggiunte con quasi 1/4 rispetto alle pubblicazioni di Accademia della Crusca,avendo anche delle Strutture Data Presenti e Valide e cioe le pubblicazioni sono state scritte effettivamente solo UNA VOLTA:)
Questo è il dato completo,compresa la data del prelievo e occorre sempre ricordarlo,perche' se non sono presenti Strutture Data,è facile che a distanza di poco tempo,possono esistere dimensioni diverse:)
In questa posizione oltre all'evidenza della data del prelievo,è presente anche la Sitemap e tra un po' formera' il secondo senso,unito al motivo per cui esistono queste descrizioni e posso anticipare che l'unione sara proprio quella con l'Holy Grail TFD Microsoft,a sua volta per varie ragioni pure e sono tutte molto importanti,sempre in funzione dei festeggiamenti per i termini di questa prima pubblicazione finale dei Just Time in DCE1 K5:)
In questa posizione la presenza della Sitemap,serve solo a confermare la notevole demenza degli operatori del simpatico dominio di Accademia della Crusca:)
I dati oggettivi uniti ai Duplicati sono gia scarsi in proprio e altrettanto lo sono gli Average delle pubblicazioni;esistono Unnatural Links in "quantita industriali" e in pratica fanno le stesse operazioni delle Sitemap,per unire delle pubblicazioni senza Struttura Data (lo strumento non è un Engine e quindi non conosce la Validita o Meno delle Strutture Data e nel report è presente solo il Fatto Vero che non esistono proprio:)
La presenza della Sitemap è effettiva,pero' attraverso il contesto descritto sopra:)
Questa è un altra ottima informazione,rispetto al dominio Accademia della Crusca,ed è solo un esempio rispetto ai presunti domini degli High Learning,ed è stato scelto il dominio specifico per il contesto molto particolare presente nell'anno 2018,all'interno della 5° Decade degli RF:)
La scelta deriva dalla presenza nel dominio rispetto ai Match della pubblicazione protagonista del Run Forever (RF) della 5D da cui è nata la Natural Search e questa posizione è utilissima per ricordare il motivo per cui Accademia della Crusca ha perso i Match nel meraviglioso anno 2018:)
L'evidenza del report,indica un eccessiva presenza di Links rispetto a 5094 pubblicazioni e il totale è 5804:)
Non esiste dubbio che la presenza dei Links sia elevatissima,ed è capace di trasformare il termine ECCESSIVO presente nel report in Eufemismo:)
Queste posizioni hanno responsabili unici e sono esclusivamente i gestori del dominio e la posizione è talmente demenziale,da rendere migliore la scelta di avere una Class C Negativa e cioe' tanti indirizzi (IP) presenti nel dominio,sarebbe una scelta migliore,perche' almeno è possibile incolpare altri autori,grazie anche al fatto che il numero d'idioti è molto elevato:)
La descrizione è anche pertinente,perche a scalare nel numero dei Links,arrivando intorno alla 4800° posizione,i TLP (Total Links Page interni e esterni al dominio) ne sono circa 180 ,ed è possibile arrivarci anche con 2 Clicks,tramite pubblicazioni che non hanno nessuna Struttura Data (non deriva dal fatto che sia Valida O Meno,perche' non esiste proprio:).
Quindi sarebbe davvero meglio non avere la Class C Valida,perche' il contesto è davvero imbarazzante per la simpatica Accademia della Crusca e cioe i colpevoli sono esclusivamente LORO:)
Attraverso la Class C Valida non è possibile nemmeno dare la Colpa ai simpatici segnalatori (99,3% in DOFOLLOW pure:) del dominio Accademia della Crusca,perche' sono in realta solo dei Kamikaze e il danno lo fanno solo a loro stessi:)
Il prelievo ha la stessa data sistemata sopra (July 27 2025) e nell'arco di 1 anno,è passato da 4 Million di segnalazioni a quasi 3 Million e per i simpatici Kamikaze del dominio Accademia della Crusca,spero che i dati non siano Veri,perche' il Danno è nella Segnalazione stessa,verso un dominio che non possiede nemmeno una Struttura Data Valida;i Content sono scarsi in maniera oggettiva e lo è anche l'Average unito alle dimensioni delle pubblicazioni;esiste un Size spropositato,assolutamente incapace di sostenere i contenuti ed è formato grazie anche alla presenza di una massa enorme di Unnatural Links (3 Clicks per 5800 pubblicazioni:).
Effettuare delle segnalazioni,attraverso il contesto descritto,occorre essere proprio dei Kamikaze,perche' ogni operatore deve possedere prima Content Validi in proprio e anche Pertinenti rispetto ai domini segnalati (sono i Links Equity e Juice:) e nel report sistemato sopra,sono presenti esattamente i contesti opposti,semplicemente perche' è presente lo Spam Totale,rispetto al Brain dei segnalatori stessi:)
I DOFOLLOW è meglio non sistemarli mai per altri domini e se dovessero essere presenti,eliminarli successivamente è UNA PESSIMA IDEA,ed è l'operazione reale che hanno fatto i segnalatori del dominio Accademia della Crusca:)
Vengono definiti Links LOST e cioe Mancanti e in realta sono stati solo eliminati
Questo è un esempio di Links Lost e cioe Mancanti,ed è accaduto anche al dominio Accademia della Crusca (è passato da 4 Million di Kamikaze Links a 3 Million circa:) e il motivo reale è quello sopra e cioe' sono i Backlinks eliminati,ed è una Pessima Idea Operativa e quando gli autori hanno "queste idee da SEV" (i SEV li chiamano links tossici,pero sono stati loro a sistemarli nei domini,ovviamente sempre in Dofollow:) sono elevatissime le probabilita' che i contenuti sono speculari all'Alto Livello di Spam presente nel Brain degli operatori:)
La data è July 28 2025 e sono presenti 246 pubblicazioni e quindi esistono tantissime possibilita' di verificare anche i collegamenti interni e non occorre tanto impegno perche' al massimo esistono 3 Clicks per oltre 5800 pubblicazioni:)
L'Average è formato da 1574 termini effettivi e grazie ai dati precedenti è facile verificarlo e l'unica variante,è unita al fatto che non esiste nessuna Struttura Data,almeno tra le pubblicazioni verificate,pero' la selezione è talmente amplia,da rendere molto probabile che non esista nessuna pubblicazione nell'intero dominio ad avere almeno 1 sola Struttura Data Valida e questa posizione potrebbe rappresentare l'unica variante rispetto alle dimensioni sistemate,perche' non avendo la Struttura Data i contenuti possono essere modificati facilmente e tra l'altro il Rischio di MisMatch è assai remoto,insieme a tutte le altre possibili violazioni,perche' l'unicita' per la simpatica Accademia della Crusca è arrivata al 45% e quindi esiste la certezza che i contenuti sono eliminati,molto prima di arrivare a qualsiasi violazione:)
L'Average del Size è formato da 75 KB,mentre gli Internal Links hanno l'Average di 158 ILA e 172 è stato l'Average dei TLP:)
Il volume completo della selezione è formato da 387204 Words e occorre ricordare che rispetto ai contenuti tradizionali,le dimensioni sono elevatissime e di sicuro gli autori della simpatica Accademia della Crusca sono anche migliori rispetto "alla media degli autori tradizionali" e l'unico loro problema deriva dal fatto "che non hanno proprio consapevolezza" del contesto in cui si trovano,insieme ai loro ottimizzatori:) Si vede subito "la mano dei SEV" grazie alla presenza di Unnatural Links in quantita industriali e Size elevati senza alcun senso rispetto ai contenuti effettivamente presenti:)
Solo calcolando l'Average che ha avuto Accademia della Crusca,per avere un volume equivalente,rispetto ai contenuti tradizionali,quest'ultimi dovrebbero avere il volume sopra e il calcolo deriva solo dall'Average e significano quasi 49 Books,sistemati in 1 sola posizione e dovrebbero avere anche un Average standard anche loro e cioe' dovrebbero essere formati da 200 pagine a Book e non è facile trovare queste dimensioni nei contenuti tradizionali:)
Tornando ai dati diretti di Accademia della Crusca,attraverso l'unicita del 45% (55% sono stati i Duplicati) il volume eliminato è formato da 212962 e solo questo dato,rende molto pertinente anche quello sopra dell'Average,perche' è facile comprendere quanto sia difficile essere immuni dai Duplicati e non è proprio possibile utilizzare gli Average dei contenuti tradizionali (250 Words a pagina:) perche' a loro volta formano quasi la meta rispetto alle dimensioni dei Thin Content e quando sono presenti LORO,significa che i contenuti sono completamente eliminati,senza dover attraversare i Match e senza commettere qualsiasi altra violazioni e quindi è facile comprendere quando sia pertinente il calcolo degli Average:)
Restando sempre ai dati di Accademia della Crusca,il volume rimasto immune dai Match è formato da 174242 Words e il Size dell'intera selezione formata da 246 pubblicazioni ha raggiunto 18,450 MB e utilizzando solo il Report at a Glance e cioe' a "colpo d'occhio",non esiste nessuna possibilita che 387204 Words siano capaci di giustificare il Size:)
Insieme a questa posizione esistono anche 38868 Internal Links e 42312 TLP (sono i total links interni e esterni al dominio),anch'essi completamente incompatibili rispetto ai termini rimasti immuni dai Match e sono anche Incompatibili rispetto ai Size:)
Utilizzando i dati del Frame Global Limit (l'esempio è nella pubblicazione precedente ) un Size da 18,450 MB,senza calcolare gli Average,produce un volume da 1596908 Words e possiede tutti i codici che servono realmente:) Il volume è quasi 5 volte quello di Accademia della Crusca,naturalmente senza calcolare il contesto operativo da cui sono arrivati i dati e cioe' senza nessuna Struttura Data e significa che non esiste nessun contenuto originale:)
La pubblicazione è questa e occorre anche aggiungere un dettaglio importante,ed è formato dal TLD .IT e quando è sistemato nella selezione,significa che il dominio possiede almeno 2 Detect Language e sono presenti nelle selezioni,semplicemente perche' esistono termini e pagine effettive e non sono delle semplici traduzioni e occorre ricordare questa posizione,perche' anche lei fa parte dei dati:) Avere multpli Detect language in 1 solo dominio,significa avere minori possibilita' di Match e visti i dati di Accademia della Crusca,di sicuro i multipli Detect language hanno limitato un po' i danni:)
Questo è il link audit rispetto alla pubblicazione piu' vicina all'Average delle dimensioni e quindi i dati sono credibili,nonostante la demenza operativa:)
Per avere tutto l'audit occorre un po' di tempo e in questa posizione è inutile conoscere il rapporto completo,perche' non esiste nessuna compatibilita tra il numero dei links e i termini effettivi presenti e tra l'altro sono anche largamente nei Duplicati nel contesto piu' ottimista (senza Struttura Data;senza Fundamental Search e attraverso 1 solo dominio:) e per questo motivo,è inutile avere il link audit completo,perche' è gia' sufficente conoscere il numero delle presenze dei links:)
Le evidenze appartengono sempre alla pubblicazione piu vicina all'Average delle dimensioni (il collegamento è sistemato sopra) e a parte l'evidenza del Detect language,molto curiosa rispetto al dominio per antonomasia della lingua italiana,esiste anche l'evidenza nella Sidebar e indica semplicemente che esistono termini effettivi e sono presenti in tutte le pubblicazioni e formano i Common Content e sono dei Duplicati anche loro.
La posizione sistemata sopra prosegue fino all'immagine sotto:
Questa è la sezione finale ed è formata sempre da termini e significa che nel dominio non esistono elementi strutturali e quindi lo spazio è un Full Size e di conseguenza per arrivare a 18,450 MB è indispensabile sistemare "tante cose extra" rispetto ai contenuti effettivamente presenti e una buona indicazione è nel numero elevatissimo di Unnatural Links e di sicuro è il primo elemento a partecipare ai Size:)
Al termine di tutte le pubblicazioni di Accademia della Crusca (sempre attraverso termini effettivi,perche' non sono contenti dei Duplicati che gia possiedono:) esiste anche la Divertente "Amministrazione Trasparente" di Accademia della Crusca:
la prima posizione è Dedicata alla Prevenzione della Corruzione e cioe' nella bellissima nazione italiana (l'Accademia della Crusca è il suo TOP:) sono diventati idioti anche i ladri,perche' prima di qualsiasi corruzione,è indispensabile che esistano anche dei valori certi e Accademia della Crusca non li possiede:)
Sempre all'interno della Trasparenza,è molto Divertente anche l'altra evidenza e sono le Sanzioni per Mancata comunicazione dei Dati e vista la gestione di Accademia della Crusca,è una posizione da Gibberish Content e cioe' è Puro Nonsense e occorre ricordare che esiste realmente,ed è un Egregious Violation anch'essa:)
Questo è il collegamento diretto della Trasparenza di Accademia della Crusca e al suo interno esistono tanti altri esempi molto Divertenti e il consiglio è quello di seguire "la sezione dirigenti",sempre di Accademia della Crusca:)
Questa è la verifica delle dimensioni della pubblicazione piu' vicina all'Average del dominio e i dati sono giusti.
LaFantasia Infinita della Casualita' è sempre meravigliosa,ed è sufficente solo vedere il nome della pubblicazione che ha l'Average esatto di tutta la selezione (occorre ricordare che è formata da 246 pubblicazioni:) ed è "La Consulenza dei metadati" da parte del dominio di Accademia della Crusca e cioe' è un altro Gibberish Content anche questo e significa Puro Nonsense
Questa è la sede di Accademia della Crusca e sembra quasi Versailles,pero' si trova a Firenze e la sua "Consulenza sui Metadati" possiede il contesto naturale della localizzazione,perche visti i dati del dominio si è oltre il Gibberish Content e cioe' è Supercazzola allo stato puro:)
Questa è la pubblicazione dei Metadati e naturalmente il collegamento è rigorosamente in Dofollow:)
Questo è il suo Size e i dati sono giusti.
Questo è il link audit per la pubblicazione che ha l'Average esatto dei Size e quindi i TLP dell'intera selezione sono ampliamente Credibili (l'average è formato da 172 TLP) mentre i Metadati sopra possiedono 250 Links da sostenere rispetto a una pubblicazione da 1700 termini e il 55% è anche in Duplicato rispetto al contesto piu' ottimista possibile, perche i reports non hanno Struttura Data;non hanno Fundamental Search;possiedono 1 solo dominio e i contenuti potrebbero essere realizzati anche da Scraping completo o generative content e i reports esisterebbero lo stesso:)
Quindi se i contenuti sono pessimi nel contesto piu' ottimista possibile,nei Dati Veri del contesto online possono essere solo peggiori e nel Caso di Accademia della Crusca,avere 250 Links per 1700 termini,nei contenuti che descrivono la "Consulenza sui Metadati",all'interno dell'ottimismo massimo,la posizione piu' pertinente diventa quella della Supercazzola:)
Questo è un esempio di Metadati e sono i codici uniti ai contenuti tradizionali (ISBN) e la eISBN sono invece i Metadati del contesto online e lo stesso metodo è utilizzato anche per le immagini.
Anche gli ID di qualsiasi dominio,compresi gli indirizzi delle pubblicazioni sono dei Metadati e quindi la Consulenza di Accademia della Crusca è una Supercazzola oggettiva,perche' prima di fornire informazioni o consulenze sui dati (sono i Metadati) è indispensabile possederli:)
Questo è un altro esempio di Metadato e sono proprio i codici ISBN e almeno il primo è di sicuro giusto,perche' appartiene a Penguin Random House e cioe' la casa editrice,proprietaria del copyright,rispetto alle opere dell'Holy Grail TFD Marcel Proust.
Questa è la sezione finale dei Metadati specifici ISBN,solo per la prima pagina,dedicata alla Ricerca di Marcel Proust:)
Sistemata la posizione dei Metadati ,diventa facile comprendere la Demenza Complessiva del simpatico dominio di Accademia della Crusca, perche' visti i loro dati, è proprio impossibile fornire alcuna consulenza,sopratutto grazie al carattere "E",sistemato davanti all'acronimo ISBN,perche' il suo riferimento è nell'immagine sotto:)
eISBN significano le posizioni sopra e il particolare piu' importante,rispetto al dato sistemato,è il percorso stesso per arrivare al dato complessivo rispetto a tutti i contenuti tradizionali,scritti nell'intera storia umana e all'interno del percorso,l'elemento piu' utilizzato per arrivare al dato generale è stato quello dei Duplicati e naturalmente sono stati eliminati dal calcolo generale.
La posizione è davvero straordinaria da unire al Metadato di ISBN,occupato dagli autori dei contenuti tradizionali,perche spesso "non hanno una grande Compliance" con i Duplicati e la posizione è anche ottimista,perche' è possibile trovare Plagiarism e Scraping,prima di arrivare ai Duplicati stessi e lo stesso contesto è possibile applicarlo a qualsiasi altro contenuto e quindi la Consulenza sui Metadati di Accademia della Crusca è realmente una Supercazzola:)
L'eISBN è nato da questa posizione,grazie ai termini festeggiati e in questa posizione cito solo la sezione evidenziata,perche' è straordinaria da unire a questo contesto:)
A parte le Raccomandazioni,esiste il ruolo effettivo di Google Search Ads 360,ed è sufficente solo citare cosa significa ,ed è il Cross Engine e occorre anche aggiungere il senso di Cross Engine
Cross Engine significa avere tutti i dati in 1 sola posizione e non sono solo quelli elencati di Google,ma esistono anche quelli della Microsoft;di Baidu;di Facebook ETC e tutti iniziano dalla posizione sopra e cioe' dal Comprehensive Quote Rating e non deriva dalla posizione Dominante di Google,ma esclusivamente dalla Logica e il motivo è quello sotto:)
Questo è il senso pieno,rispetto alle posizioni sistemate e sono unite solo al Content Creator,ed è l'unica Autorita effettiva e tutti gli altri,compreso il dominio Accademia della Crusca,non hanno nessuna "Referenza Valida" (è la Reputation:) rispetto all'Highest Rating e tra l'altro coloro che dovrebbero conferire la Reputation,debbono avere prima il DEMONSTRATE anche loro,attraverso i propri contenuti e quindi l'operazione nasce gia con la Credibility uguale a ZERO:)
La sintesi di queste posizioni è presente anche in Google Ads 360,attraverso il Cross Engine,perche' anche gli altri operatori debbono seguire la LOGICA,ed è esclusivamente quella del Legitimate Publishers Unique Value e cioe' il Content Creator e qualsiasi altra strategia,nella migliore delle ipotesi è solo Teoria:)
Dal senso pieno della posizione sopra,grazie all'esempio di Accademia della Crusca,in rappresentanza di tutti i simpatici High learning,si arriva alla LOGICA del Report dell'Onesta e cioe' perche' si vendono le Ads e non è in vendita la Ricerca,semplicemente perche' senza la Ricerca (è l'Original Unique e Content Value i FESTEGGIATI:) non esisterebbe proprio il business online,sia per le Ads;per i Prodotti e qualsiasi altro servizio e da questa posizione è facile arrivare al Legitimate Publishers Unique Value,perche' solo loro sono capaci di generare il business e i termini piu' belli da unire alla festa del Just Time DCE1 K5 sono quelli degli ORDINARY PEOPLE uniti all'Highest Rating:)
Il senso di queste posizioni non è ancora finito,pero' tutte hanno l'unione con il Legitamate Publishers Unique Value,compresa la posizione sotto:)
La 5D degli RF ha fornito un grandissimo aiuto,comprese le pubblicazioni che sono arrivate dopo il suo Gold Star e tra di esse,esiste anche la posizione sopra e la data è DEC 27 2018:)
E' l'augurio che ho fatto alla 5D nel suo Gold Star e quando l'ho scelto,non conoscevo la Rilevanza dei Termini e di sicuro non la conosce nemmeno il dominio sotto:)
Sono proprio i termini utilizzati per l'augurio alla 5D degli RF,ad aver creato questa pubblicazione,per festeggiare altri termini del Just Time DCE1 K5:)
1 anno fa' erano 80 le contestazioni nei confronti di Philip Morris,per Patents in Appliance e attualmente ne sono 91 e il senso del dato è molto semplice,perche' è presente una delle piu' grandi aziende al mondo e sopratutto è la piu' "Addestrata a tutte le Contestazioni e Litigation",pero' i Dati Veri sono validi anche per LEI e per comprendere cosa significa,attraverso il collegamento sopra,tutto dedicato alle Litigation in Appliance di Philip Morris,il dato piu' interessante è quello della data delle Priority,perche' esistono anche degli Average temporali,rispetto alle Approvazioni o Meno delle Patents (è circa 22 mesi) e attraverso la presenza delle Priority,in Teoria,sarebbe possibile avere archi temporali minori,rispetto all'Approvazione delle Patents,pero' difficilmente avviene (tra l'altro esistono anche tantissime Litigation in Grant e cioe' quando le Patents sono state approvate:) e all'interno delle Contestazioni (anche rispetto ai Copyright) non esiste nessun dubbio,che siano i termini ad Alta Rilevanza,ad avere le probabilita' piu' elevate di avere Contestazioni:)
Esistono tante altre selezioni,pero' la pubblicazione ha gia' raggiunto dimensioni notevoli e quindi altri contenuti saranno in prossime pubblicazioni e in questa posizione anticipo solo alcune selezioni fatte e serviranno per giustificare il Legitimate Publishers Unique Value
La prima selezione è unita a questa posizione,ed è arrivata grazie al Custom CMS di Philip Morris e ai suoi generative content:)
E' l'homepage di Progress e l'idea è unita al consumo di energia elettrica solo per i generative content e secondo i calcoli di IEA (è presente anche nei domini delle verifiche interne agli spazi) solo il consumo di energia elettrica per i generative content è maggiore a 900 TWh e per avere un idea di cosa significa,tutto il consumo della nazione italiana,per uso civile;industriale e commerciale è poco maggiore a 300 TWh.
Da questa posizione derivano tanti calcoli,compreso quello del Benkmark General Failure e il motivo è molto semplice,perche' se a Open AI (tutto è nato dai generative content) venissero aggiunti anche i "costi di mercato" dell'energia elettrica,per Lei il General Failure sarebbe gia una realta:)
Il costo dei Calculator hanno l'impatto maggiore,sia per il consumo di energia elettrica e anche per il suo costo e attualmente, grazie ai "prezzi speciali di Microsoft Azure",applicati a Open AI,(sono molto al di sotto dei prezzi di mercato) il fallimento è stato evitato:)
L'importanza di queste posizioni è molto semplice,perche' il consumo esponenziale solo di Open AI (è il riferimento dei generative content:) in energia elettrica,applicata ai Calculator,non servono assolutamente per "arrivare all'AGI" (è l'ossessione del CEO di Open AI e cioe' la presunta intelligenza artificiale generale:) ma deriva dal fatto che Open AI e tutti i generative content,non conoscono assolutamente i Dati Veri:)
Solo i Legitimate Publishers Unique Value,sono capaci di risparmiare energia elettrica nel vero senso delle parole,perche' non esiste nessuna necessita di applicare "Calculator Indifferenziati",simili a quelli utilizzati da Open AI e da tutti i generative content,attraverso il loro "Scraping Indifferenziato":)
Solo i Duplicati formano oltre il 50% dei contenuti e quindi è sufficente eliminarli e si risparmia tanta energia nei Calculator e nel resto dei contenuti esiste una larga percentuale di Unnatural Links e togliendo solo questi elementi,il risparmio di energia è notevole e il contesto possiede anche un nome specifico,ed è BIDIRECTIONAL e significa semplicemente che i Meravigliosi Algoritmi "comunicano tra di loro":) (se dovesse passare il professor Panda e trova una percentuale elevata in Duplicati,è inutile sprecare energia per avere i calcoli dei Links e la stessa cosa accade per il dottor Penguin,proprio per i links e avverte Panda di non sprecare energia per vedere i Duplicati:)
Open AI e tutti i generative content,queste operazioni non le possono proprio fare,perche' sono loro stessi,intrinsecamente dei SEV (sono strutturalmente predisposti solo per i Dati Falsi :) e la posizione è unita solo al Divertimento,perche' Open AI si è messa pure in mente "di fare lei la SEARCH",attraverso il sistema utilizzato per i generative content e cioe' Scraping Indifferenziato e spreco enorme di energia elettrica,per sostenere dei Calculator completamente inutili:)
Da questa posizione è nata l'idea dei Legitimate Publishers Unique Value e non possono essere assolutamente compatibili con Open AI e tutti i generative content,ad iniziare dal contesto piu' semplice,perche' tutti i calcoli dell'energia elettrica consumata dai Calculator,non hanno l'unione delle Proposte Complessive,rispetto a qualsiasi dominio,ad iniziare dagli operatori stessi (Open AI quasi sempre,non possiede nessuna Struttura Data)
Esistono gia' tante selezioni,rispetto al contesto appena descritto e in questa posizione cito solo la piu' curiosa:
Questa è la posizione piu' curiosa da unire a Open AI e a tutti i generative content ,perche' la prima base della ricerca dei Fact Check è quella di Arrivare alla Verifica stessa dei Fatti Veri e non è affatto facile il percorso,perche' l'inizio sono sempre i Duplicati anche per i Fact Check:)
Per conoscere i Duplicati è indispensabile prima avere l'Original Unique e Content Value e per avere il contesto è indispensabile che siano valide le Strutture Data e quindi l'unica ragione possibile,unita al finanziamento della Microsoft a Open AI (occorre anche aggiungere l'utilizzo dei Calculator di Microsoft Azure a prezzi notevolmente piu' bassi,rispetto al mercato:) è unita formalmente al Reinventing Search,mentre in realta' esiste un motivo molto piu' realistico,ed è quello del Market Share rispetto al business del contesto online,ed è anche il motivo per cui l'Holy Grail TFD Microsoft,distribuisce il suo Powered delle ricerche a "tanti altri Engines",ed escluso l'Holy Grail TFD Google,in pratica a tutti gli Engines esistenti al mondo e lo fa' esclusivamente solo per il Market Share,ed è in pratica lo stesso motivo per cui ha finanziato Open AI:)
Questi sono i veri motivi per cui il finanziamento di Open AI non è unito al Reinventing Search,ma al Market Share rispetto al business del contesto online:)
La posizione sopra non deriva dalla pubblicazione che contiene l'Origin RF ONE,pero' sono presenti i Fact Check e il Brevetto appartiene all'Holy Grail TFD Microsoft e l'Invalid Traffic rispetto al Keywords Stuffing non ha come riferimento 1 sola pubblicazione (tra l'altro è gia' difficile conoscere i suoi dati,perche' sono ignorati i termini rimasti immuni dai Match) ma sono le Proposte Complessive dell'intero dominio ad avere il Keywords Stuffing e per conoscerle è indispensabile che sia presente una Struttura Data Valida e deve esserlo in Long Standing Webmstares Guidelines anche per Microsoft e i Dati Veri non derivano da 1 solo dominio,ma dal Taken Against Content Generally e cioe' dalla Fundamental Search (sono i Match globali a formare i dati veri) e sono sempre loro a permettere che esista il Search Result API e cioe' le posizioni sotto:)
Questo è il Search Result API e per essere valido,è indispensabile avere le posizioni sistemate sopraoppure utlizzare direttamente i termini festeggiati,perche' l'Original Unique e Content Value, è il valore delle Proposte Complessive e potranno essere Piu' o Meno Rilevanti,pero' debbono prima ESISTERE e se fosse presente il Keywords Stuffing è esattamente l'opposto e cioe' i contenuti sono proprio eliminati e qualsiasi dato fosse unito a loro,diventa tutto Invalid Traffic:)
Sarebbe possibile sistemare tanti esempi,solo per Dimostrare quanti Match ci sono stati per avere il report sopra e in questa posizione è proprio impossibile e quindi ricordo solo il volume unito ai termini sistemati,ed è vicino a 7 Billion e per avere volumi maggiori,servono proprio i Just Time,intesi come termini unici anch'essi:)
La selezione sistemata ha il Giappone come esempio e il Detect Language dei Match ((HL JA) è il giapponese e l'Engine è Google Japan e poi esiste l'evidenza del Sign IN scritto in giapponese e significa che la ricerca è generale e questa posizione in realta non significa nulla,perche' quando i Dati Veri non ci sono,è assolutamente indifferente unire il proprio Account Generale:)
Quindi potrebbe essere sistemato anche l'Account scritto in lingua giapponese e per i Dati Veri non cambia assolutamente nulla e il contesto piu' straordinario,non è unito al Sign In per il proprio Account Generale,ma al fatto vero che dopo 10 anni,attraverso dimensioni colossali dei contenuti,uniti alla categoria peggiore da unire ai Fact Check,il contesto straordinario dell'Account Generale dell'Heroic DIN, Esista Ancora!:)
Questo è un altro Search Result API e per essere valido è possibile bypassare anche il Keywords Stuffing unito all'Invalid Traffic,perche' i dati veri da cui derivano i reports,comprese le API,sono proprio quelli festeggiati:)
Comprehensive Quote Rating e se la loro presenza non avesse un Contesto Juice,tutti i reports prodotti appartengono all'Invalid Traffic al 100%:)
Nell'esempio del Search Result API la geolocalizzazione è il Texas (Austin è la citta),il Detect Language della ricerca è l'Inglese e il device è il desktop e per il mobile esistono gli stessi dati.
Per avere questi Reports,è indispensabile possedere il keywords Stuffing e cioe' le Proposte Complessive e i Fatti descritti debbono anche essere Veri :)
E' la posizione piu' pertinente del Legitimate Publishers Unique Value e il valore maggiore è proprio per la categoria di questi contenuti,perche' indirettamente è anche in tutte le altre:)
Questo è l'elenco delle categorie e la posizione rende semplicissimo comprendere cosa significa il Keywords Stuffing sistemato sopra,unito al Search Result API (i Match possono avvenire rispetto a qualsiasi contenuto,all'interno di qualsiasi categoria) e nello stesso tempo rende semplicissimo comprendere cosa sono i Multi fact Check,uniti alla categoria dell'Information Technology:)
Questi sono i dati delle categorie e per avere il loro numero,è sufficente eliminare un centinaio di termini uniti alle descrizioni e dividere il resto per 3 o 4 termini e si ha il numero delle categorie,ed è sufficente solo vederle,per immaginare anche il numero di Fact Check che possono avere,ed è facile la comparazione con questi contenuti,perche' solo nella pubblicazione presente,è molto probabile che esistano un numero di fact Check piu' elevato,rispetto a tutto l'elenco delle categorie sistemato sopra:)
Dopo gli esempi sistemati,uniti al Search Result API,arriva anche la pubblicazione che ha suggerito il metodo utilizzato in questi contenuti,grazie alla posizione Jolly dell'Holy Grail TFD Microsoft:)
E' unita ai generative content per Open AI e nello stesso tempo esiste anche il Brevetto in Grant per la Ricerca dei fact Check e le 2 posizioni sembrano inconciliabili,mentre in realta' sono in perfetta Compliance e per comprenderlo è indispensabile eliminare Open AI insieme a tutte le cazzate del suo CEO e inserire i Veri Intenti dell'Holy Grail TFD Microsoft e in pratica ne esiste 1 solo,ed è il Market Share Vero unito al colossale business online e solo questa posizione rende compatibile Open AI rispetto al Brevetto del Fact Check:)
Questa è la LOGICA unita al VERO Intento dell'Holy Grail TFD Microsoft,tramite il generative traffic (è Spam e cioe' Invalid Traffic:) e cioe' la vera attivita di Opern AI,oltre a quella di bolla speculativa:)
Questa è la posizione attuale delle General Guidelines di Microsoft,largamente compatibili con quelle di Google,rispetto ai generative e insieme al Traffic (SPAM:) è presente nelle penalita anche i generative dei content e il contesto è anche normale,perche' è vero che l'Holy Grail TFD Microsoft ha finanziato Open AI (utilizza anche i calculator di Microsof Azure giusto per non farla fallire solo con il costo dell'energia elettrica:) e lo ha fatto solo allo scopo di avere vantaggi nel Market Share degli Engines e cioe nel vero business del contesto online (il Reinventing Search significa proprio questo:) e per lo stesso motivo fornisce il suo Powered a tutti gli altri Engines e quindi figurarsi che valore hanno i dati dell'Holy Grail TFD Google:)
Quindi l'Holy Grail TFD Microsoft,non ha nessuna DICOTOMIA,perche' cerca solo di migliorare la sua percentuale di Market Share e per questo motivo esistono i finanziamenti a Open AI ,insieme alla posizione sopra delle sue General Guidelines,perche' la fantastica Microsoft desidera di sicuro aumentare la sua percentuale nel Market Share degli Engines,pero' non vuole che il colossale business online sia Infestato da Inflate Data (sarebbe il suo fallimento e i generative traffic e content fanno proprio questo:) e per questo motivo esiste la LOGICA delle sue General Guidelines sistemate sopra:)
La conferma delle posizioni è nel 78° RF della 8D e inizia dalla posizione sotto:
E' dedicata alle Sitemap e l'aspetto tecnico è nella pubblicazione collegata e in questa posizione è sufficente aggiungere il Divertimento alle Sitemap stesse, sopratutto nei confronti degli operatori SEV (Open AI ne fa' parte:) perche' quasi sempre i loro domini sono Infestati da Unnatural Links e quindi è molto facile superare l'Error Rate:)
Questa posizione è meravigliosa da unire ai domini SEV,Open AI compresa e conferma i veri intenti dell'Holy Grail TFD Microsoft e sono esclusivamente quelli del Market Share degli Engines e la scelta è anche molto facile,perche' tutte le altre posizioni dei generative content (Open AI compresa) hanno come unica sicurezza quella del Fallimento:)
La posizione piu' Divertente è unita al PLEASEonly list Canonical Urls da unire alle Sitemap,perche' occorre attraversare tutto il Keywords Stuffing sistemato sopra,rispetto alle Proposte Complessive di qualsiasi dominio e poi occorre sostenere anche la Verifica dei Fact Check e naturalmente i codici Canonical,anche se dovessero esistere Dati Juice,non sono Decisi dagli autori,semplicemente perche' Ignorano qualsiasi dato,compresi quelli dei loro competitors:)
Quindi il Please unito a Only Canonical Urls,è piu' vicino al Divertimento (assomiglia in realta molto a una presa per il culo:) rispetto alla realta operativa del contesto online e per l'Holy Grail TFD Microsoft non è una novita,perche' un esempio diretto è proprio nella pubblicazione che contiene i termini festeggiati in questa prima pubblicazione finale dei festeggiamenti per il DCE1 K5:)
Arriva dai Link Juice e anche se ho sbagliato a digitare i termini (ho scritto Nuilding:) la risposta è sempre Link Juice rispetto agli Internal o External Links Building e cioe' le operazioni reali che fanno i SEV,Open AI compresa e quindi sono fuori Sitemap e fuori codici Canonical:)
Questa è solo una delle descrizioni unite ai Links Juice,perche' le operazioni alternative ai Dati Veri sono talmente idiote ,da rendere normale la risposta sopra e assomiglia molto al Please unito ai Canonical URLs e cioe' sono entrambi unite al Divertimento,rispetto agli operatori SEV,Open AI compresa:)
Per i termini con il volume piu' elevato dell'intera selezione di questo primo Just Time Finale rispetto ai festeggiamenti del DCE1 K5 ci saranno altre pubblicazioni e probabilmente saranno all'interno del prossimo FGL SEP 2025,perche' esiste un unione straordinaria,oltre ai termini sistemati e occorrono tanti dettagli per creare l'unione stessa e in questa posizione anticipo solo da cosa è nato il contesto straordinario:)
La data dell'URL formera' la distinzione,rispetto alle altre selezioni che aggiungero' e semplicemente,dopo la pubblicazione precedente,mi è venuto in mente di fare il secondo Takeout,pero' questa volta in maniera piu' dettagliata,rispetto al Takeout stesso e inizia proprio dalla posizione sistemata sopra (1 Select Data e quelli disponibili ne sono 71,sempre su Google Data:)
I particolari penso di sistemarli nella prossima pubblicazione e in questa posizione anticipo solo la straordinaria unione,rispetto alla pagina che contiene i termini con il volume piu' elevato dei Just Time,tranne i medesimi:)
L'idea mi è venuta subito dopo la precedente pubblicazione,perche' le dimensioni erano aumentate notevolmente (oltre 33K termini effettivi) rispetto al primo Takeout e sommate alle precedenti ,il totale ha raggiunto quasi 90K termini effettivi,attraverso solo 5 pubblicazioni:)
Quando ho richiesto il 2° Takeout era AGU 6 2025 e non conoscevo assolutamente i termini di questo Just Time e ancora meno conoscevo dove fossero collocati e la Fantasia Infinita della Casualita' ha voluto che fossero in una pagina di TD Web Server,anch'essa nata nell'anno 2019 (è lo spazio speculare di web server 19,pero su AV e quindi Wordpress) e all'inizio gli spazi servivano per la comparazione dei Size tra le piattaforme e poi li ho utilizzati per altri contenuti.
Naturalmente le pubblicazioni sono nate in questo dominio,pero' l'Holy Grail TFD Google,per i termini con il volume piu' elevato dei Just Time (esclusi LORO stessi:) nei codici canonical ha scelto TD Web Server e l'unione straordinaria con il 2° Takeout,deriva dal fatto che senza conoscere assolutamente nulla,esistono in pratica le stesse dimensioni,rispetto alla pagina di TD Web Server e l'unica differenza è unita al fatto che TD Web Server ha 10 pubblicazioni in Full Text,mentre il 2° Takeout possiede 5 pubblicazioni,ed è incredibile anche il Size,perche' sono in pratica uguali:)
Insieme formeranno i Dati del Frame Global Limit e con quasi 90K termini in 1 sola posizione,i Size prodotti saranno rilevantissimi in tutte le comparazioni e la Casualita ha voluto che arrivassero contemporaneamente,senza conoscere assolutamente nessun dato:)
I particolari saranno nella prossima pubblicazione e in questa posizione anticipo un altro dato fantastico:
Esiste anche il dato di Page Solemn AGU 2023,unito alla Fantasia Infinita della Casualita' e posso anticipare che nonostante le posizioni citate,i dati di Page Solemn AGU 2023,non sono stati "nemmeno sfiorati" e di conseguenza le Demo Data sono in Festa Totale,perche' esistono tantissime Alte Rilevanze,ed è altrettanto elevato il volume delle Keywords che li hanno sostenuti e quindi per forza di cose debbono avere valore anche loro,ad iniziare dal fatto di non essere stati eliminati,altrimenti,le Alte Rilevanze non potrebbero proprio Esistere:)







 https://dinpoststory.blogspot.com/2024/12/demonstrate-juice-data-archive-10y.html
https://dinpoststory.blogspot.com/2024/12/demonstrate-juice-data-archive-10y.html  https://dinpoststory.blogspot.com/2024/12/demonstrate-juice-data-archive-10y.html
https://dinpoststory.blogspot.com/2024/12/demonstrate-juice-data-archive-10y.html 

 Questa è la posizione piu' bella dell'intero contesto online,ed è formata "dagli Ordinary People" e cioe' tutti gli autori che non hanno "la potenza economica" da unire ai Just in Time del contesto tradizionale:)
Questa è la posizione piu' bella dell'intero contesto online,ed è formata "dagli Ordinary People" e cioe' tutti gli autori che non hanno "la potenza economica" da unire ai Just in Time del contesto tradizionale:)
 Queste sono le sezioni operative,ed è facile comprendere lo scopo delle medesime,ed è quello di "Decidere la Ricerca" e quindi anche quello di Decidere il Business (i link building insieme a tutti gli Unnatural,servono proprio a questo scopo:) e per farlo è indispensabile avere una potenza economica elevatissima,perche' occorre sostenere i costi delle ottimizzazioni,Custom CMS compreso,insieme ai costi altrettanto elevati delle Contestazioni e delle Litigation:)
Queste sono le sezioni operative,ed è facile comprendere lo scopo delle medesime,ed è quello di "Decidere la Ricerca" e quindi anche quello di Decidere il Business (i link building insieme a tutti gli Unnatural,servono proprio a questo scopo:) e per farlo è indispensabile avere una potenza economica elevatissima,perche' occorre sostenere i costi delle ottimizzazioni,Custom CMS compreso,insieme ai costi altrettanto elevati delle Contestazioni e delle Litigation:)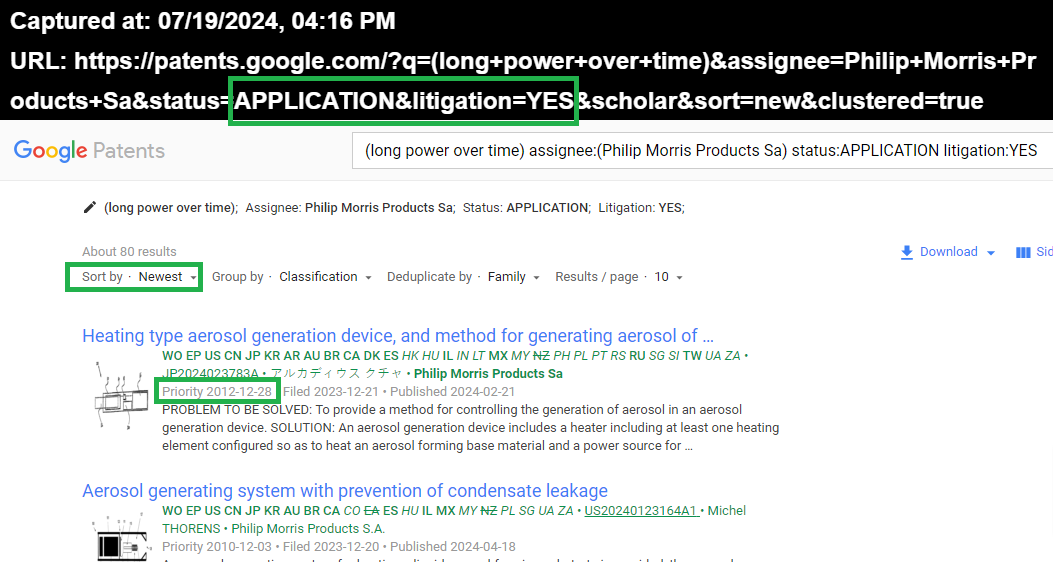
 Anche questa posizione è unita alla certificazione del Legitimate Publishers Unique Value e quindi anche al valore dei termini di questo Just Time e il contesto è quello fisico delle operazioni stesse e riguarda il consumo di energia elettrica:)
Anche questa posizione è unita alla certificazione del Legitimate Publishers Unique Value e quindi anche al valore dei termini di questo Just Time e il contesto è quello fisico delle operazioni stesse e riguarda il consumo di energia elettrica:) https://www.sec.gov/Archives/edgar/data/806085/000110465908005476/a08-3530_110k.htm
https://www.sec.gov/Archives/edgar/data/806085/000110465908005476/a08-3530_110k.htm 

 La Fantasia Infinita della Casualita' ha scelto che fosse proprio il Fantastico Rick Result,il piu' vicino coetaneo di questo dominio e sinceramente non mi ero accorto che esisteva anche la posizione sotto,anch'essa nata a JAN 15 2015 :)
La Fantasia Infinita della Casualita' ha scelto che fosse proprio il Fantastico Rick Result,il piu' vicino coetaneo di questo dominio e sinceramente non mi ero accorto che esisteva anche la posizione sotto,anch'essa nata a JAN 15 2015 :)  Probabilmente la Fantasia Infinita della Casualita',ha scelto che mi accorgessi di questa posizione,proprio in questo contesto,ed è sicuramente il migliore da unire al Legitimate Publisher Unique Value e quindi ai festeggiamenti dei termini di questo Just Time:)
Probabilmente la Fantasia Infinita della Casualita',ha scelto che mi accorgessi di questa posizione,proprio in questo contesto,ed è sicuramente il migliore da unire al Legitimate Publisher Unique Value e quindi ai festeggiamenti dei termini di questo Just Time:)  Questa è la posizione delle General Guidelines delle Strutture Data e nel collegamento sopra,è presente la pagina originale di Jan 15 2015 e vicino a Simplified and Clarified esiste il collegamento delle General Guidelines e l'inizio è il Content Policies di Google Search e tutte queste posizioni hanno avuto tanti Developers nel corso dei 10 anni e il piu' Straordinario è nella nota centrale,perche' le Strutture Data non determinano il Main Content e a JAN 2015 non esisteva proprio e non esisteva nemmeno ad AGU 2018 ,quando è iniziata l'operativita' del Frame Global Limit,attraverso un suo elemento e l'ho denominata la Monotematicita dei Contenuti,semplicemente perche' nel contesto online è oggettivamente impossibile che Esistano i Tuttologi:)
Questa è la posizione delle General Guidelines delle Strutture Data e nel collegamento sopra,è presente la pagina originale di Jan 15 2015 e vicino a Simplified and Clarified esiste il collegamento delle General Guidelines e l'inizio è il Content Policies di Google Search e tutte queste posizioni hanno avuto tanti Developers nel corso dei 10 anni e il piu' Straordinario è nella nota centrale,perche' le Strutture Data non determinano il Main Content e a JAN 2015 non esisteva proprio e non esisteva nemmeno ad AGU 2018 ,quando è iniziata l'operativita' del Frame Global Limit,attraverso un suo elemento e l'ho denominata la Monotematicita dei Contenuti,semplicemente perche' nel contesto online è oggettivamente impossibile che Esistano i Tuttologi:) Nell'anno 2015 è nata anche OpenAI e naturalmente non fa' parte degli Holy Grail Age,pero' possiede un contesto molto divertente,rispetto alle posizioni sistemate:)
Nell'anno 2015 è nata anche OpenAI e naturalmente non fa' parte degli Holy Grail Age,pero' possiede un contesto molto divertente,rispetto alle posizioni sistemate:) L'Original Unique e Content Value è la sintesi generale di tutte le posizioni sistemate e poi esiste anche il Comprehensive Quotes Rating e il riferimento sono proprio le Quality Guidelines,unite alle Strutture Data e naturalmente le posizioni sono sempre degli esempi in funzione delle Demo Data,pero' i Dati sono assolutamente Veri,perche' senza le proposte Complessive,non potrebbero proprio esistere i termini dei Just Time e nemmeno le pubblicazioni degli RF e per comprendere il suo valore,è sufficente utilizzare i costi sostenuti dai simpatici utenti degli operatori SEV e per paradosso è possibile unire anche Open AI,grazie alla sua vicinanza al Benchmark del General Failure e cioe a quanti investimenti economici sono stati fatti,per arrivare ai Dati sopra e di sicuro l'AGI non potra mai arrivarci,perche' "possiede il peccato originale" rispetto a qualsiasi Contenuto,ed è la Mancanza dell'Original Unique e Content Value:)
L'Original Unique e Content Value è la sintesi generale di tutte le posizioni sistemate e poi esiste anche il Comprehensive Quotes Rating e il riferimento sono proprio le Quality Guidelines,unite alle Strutture Data e naturalmente le posizioni sono sempre degli esempi in funzione delle Demo Data,pero' i Dati sono assolutamente Veri,perche' senza le proposte Complessive,non potrebbero proprio esistere i termini dei Just Time e nemmeno le pubblicazioni degli RF e per comprendere il suo valore,è sufficente utilizzare i costi sostenuti dai simpatici utenti degli operatori SEV e per paradosso è possibile unire anche Open AI,grazie alla sua vicinanza al Benchmark del General Failure e cioe a quanti investimenti economici sono stati fatti,per arrivare ai Dati sopra e di sicuro l'AGI non potra mai arrivarci,perche' "possiede il peccato originale" rispetto a qualsiasi Contenuto,ed è la Mancanza dell'Original Unique e Content Value:) https://www.sec.gov/Archives/edgar/data/320193/000109690625000100/nlpc_px14a6g.htm
https://www.sec.gov/Archives/edgar/data/320193/000109690625000100/nlpc_px14a6g.htm 

 Anche per i Multi Fact Check non cambia NULLA,rispetto alla prima violazione dei Duplicati,pero' la posizione è capace di elevare in maniera esponenziale il valore dei Volumi delle Keywords e quello dei Size,uniti a qualsiasi Contenuto:)
Anche per i Multi Fact Check non cambia NULLA,rispetto alla prima violazione dei Duplicati,pero' la posizione è capace di elevare in maniera esponenziale il valore dei Volumi delle Keywords e quello dei Size,uniti a qualsiasi Contenuto:)  https://dinpoststory.blogspot.com/2020/12/natural-contest-finance-airline-4.html
https://dinpoststory.blogspot.com/2020/12/natural-contest-finance-airline-4.html 
 E' sufficente solo unire la categoria IT e anche gli operatori SEV ne fanno parte (esclusa Wikimedia perche' in realta' non appartiene a nessuna categoria:) e si ha anche il Divertimento Legittimo:)
E' sufficente solo unire la categoria IT e anche gli operatori SEV ne fanno parte (esclusa Wikimedia perche' in realta' non appartiene a nessuna categoria:) e si ha anche il Divertimento Legittimo:) Esiste anche questa posizione per i Fact Check,ed è il proprietario del Brevetto e cioe' l'Holy Grail TFD Microsoft:)
Esiste anche questa posizione per i Fact Check,ed è il proprietario del Brevetto e cioe' l'Holy Grail TFD Microsoft:)
 https://dinpoststory.blogspot.com/2025/05/demonstrate-juice-effort-data-archive.html
https://dinpoststory.blogspot.com/2025/05/demonstrate-juice-effort-data-archive.html La 5D degli RF,ha permesso la nascita del Frame Global Limit;delle Page Solemn;delle verifiche interne ai domini,grazie alla Monotematicita' dei Contenuti e sarebbero diventati successivamente i Main Content;ha permesso la nascita dei Just Time e sempre la Straordinaria 5D degli RF,ha permesso anche la nascita della Natural Search:)
La 5D degli RF,ha permesso la nascita del Frame Global Limit;delle Page Solemn;delle verifiche interne ai domini,grazie alla Monotematicita' dei Contenuti e sarebbero diventati successivamente i Main Content;ha permesso la nascita dei Just Time e sempre la Straordinaria 5D degli RF,ha permesso anche la nascita della Natural Search:) https://keywordtdarchive.blogspot.com/2018/08/tpj-level-content-archive.html
https://keywordtdarchive.blogspot.com/2018/08/tpj-level-content-archive.html  Copyscape è la Casa Madre dello strumento delle verifiche e l'avevo utilizzato prima di AGU 2018 tante volte nelle comparazioni,pero' al massimo esistevano 2 pubblicazioni e la Fantasia Infinita della Casualita' ha scelto,proprio la pubblicazione protagonista della Natural Search,ed è proprio quella inserita in Copyscape:)
Copyscape è la Casa Madre dello strumento delle verifiche e l'avevo utilizzato prima di AGU 2018 tante volte nelle comparazioni,pero' al massimo esistevano 2 pubblicazioni e la Fantasia Infinita della Casualita' ha scelto,proprio la pubblicazione protagonista della Natural Search,ed è proprio quella inserita in Copyscape:) https://dinpoststory.blogspot.com/2018/11/mirabilis-natural-search-5d-rf-9.html
https://dinpoststory.blogspot.com/2018/11/mirabilis-natural-search-5d-rf-9.html  Mi dispiace per la simpatica Accademia della Crusca,pero' i suoi Dati Veri sono questi:)
Mi dispiace per la simpatica Accademia della Crusca,pero' i suoi Dati Veri sono questi:)  Questa è una posizione fantastica per festeggiare gli Highest Effort Main Content,grazie alle dimensioni a scalare,rispetto alle pubblicazioni del dominio di Accademia della Crusca:)
Questa è una posizione fantastica per festeggiare gli Highest Effort Main Content,grazie alle dimensioni a scalare,rispetto alle pubblicazioni del dominio di Accademia della Crusca:) Questa è la Class C del dominio specifico e indica che esiste 1 solo IP e quindi tutte le posizioni sono state scelte dagli operatori dello spazio,probabilmente immaginando che nel contesto online esista l'IGNORE,tanto Caro agli operatori dei contenuti tradizionali,ed è sicuro che la simpatica Accademia della Crusca,sia in questo contesto:)
Questa è la Class C del dominio specifico e indica che esiste 1 solo IP e quindi tutte le posizioni sono state scelte dagli operatori dello spazio,probabilmente immaginando che nel contesto online esista l'IGNORE,tanto Caro agli operatori dei contenuti tradizionali,ed è sicuro che la simpatica Accademia della Crusca,sia in questo contesto:) A scalare nelle dimensioni si arriva alla 40° posizione,ed è particolarmente importante in questo contesto,perche' sono sistemate esattamente le dimensioni dell'Average che ha avuto l'attuale Origin RF ONE,pero anche queste pubblicazioni non hanno nessuna Struttura Data e occorre sempre ricordare che il riferimento non è la Validita o Meno delle Strutture,perche' non sono proprio presenti e quindi esiste la sicurezza che il dominio di Accademia della Crusca,pensa seriamente di essere ancora nell'IGNORE dei contenuti tradizionali:)
A scalare nelle dimensioni si arriva alla 40° posizione,ed è particolarmente importante in questo contesto,perche' sono sistemate esattamente le dimensioni dell'Average che ha avuto l'attuale Origin RF ONE,pero anche queste pubblicazioni non hanno nessuna Struttura Data e occorre sempre ricordare che il riferimento non è la Validita o Meno delle Strutture,perche' non sono proprio presenti e quindi esiste la sicurezza che il dominio di Accademia della Crusca,pensa seriamente di essere ancora nell'IGNORE dei contenuti tradizionali:) Questo è il numero di Clicks dalla homepage del dominio e quindi gli operatori di Accademia della Crusca,sono "andati a scuola dai SEV",perche' hanno esattamente le stesse impostazioni,in opposizione al Report dell'Onesta e quindi della Logica e di conseguenza sono in opposizione anche ai Legittimi Publishers e se fossero operative le idee di Accademia della Crusca e di tutti i SEV (da questa pubblicazione ne fa parte anche la celebre accademia della bellissima lingua italiana:) è sicuro che esisterebbe il Just in Time operativo del contesto tradizionale e in quello online non puo proprio funzionare,perche' si avrebbe solo una Super Inflate Data:)
Questo è il numero di Clicks dalla homepage del dominio e quindi gli operatori di Accademia della Crusca,sono "andati a scuola dai SEV",perche' hanno esattamente le stesse impostazioni,in opposizione al Report dell'Onesta e quindi della Logica e di conseguenza sono in opposizione anche ai Legittimi Publishers e se fossero operative le idee di Accademia della Crusca e di tutti i SEV (da questa pubblicazione ne fa parte anche la celebre accademia della bellissima lingua italiana:) è sicuro che esisterebbe il Just in Time operativo del contesto tradizionale e in quello online non puo proprio funzionare,perche' si avrebbe solo una Super Inflate Data:)
 Questo è il dato completo,compresa la data del prelievo e occorre sempre ricordarlo,perche' se non sono presenti Strutture Data,è facile che a distanza di poco tempo,possono esistere dimensioni diverse:)
Questo è il dato completo,compresa la data del prelievo e occorre sempre ricordarlo,perche' se non sono presenti Strutture Data,è facile che a distanza di poco tempo,possono esistere dimensioni diverse:) La presenza della Sitemap è effettiva,pero' attraverso il contesto descritto sopra:)
La presenza della Sitemap è effettiva,pero' attraverso il contesto descritto sopra:) Questa è un altra ottima informazione,rispetto al dominio Accademia della Crusca,ed è solo un esempio rispetto ai presunti domini degli High Learning,ed è stato scelto il dominio specifico per il contesto molto particolare presente nell'anno 2018,all'interno della 5° Decade degli RF:)
Questa è un altra ottima informazione,rispetto al dominio Accademia della Crusca,ed è solo un esempio rispetto ai presunti domini degli High Learning,ed è stato scelto il dominio specifico per il contesto molto particolare presente nell'anno 2018,all'interno della 5° Decade degli RF:) Non esiste dubbio che la presenza dei Links sia elevatissima,ed è capace di trasformare il termine ECCESSIVO presente nel report in Eufemismo:)
Non esiste dubbio che la presenza dei Links sia elevatissima,ed è capace di trasformare il termine ECCESSIVO presente nel report in Eufemismo:)  Attraverso la Class C Valida non è possibile nemmeno dare la Colpa ai simpatici segnalatori (99,3% in DOFOLLOW pure:) del dominio Accademia della Crusca,perche' sono in realta solo dei Kamikaze e il danno lo fanno solo a loro stessi:)
Attraverso la Class C Valida non è possibile nemmeno dare la Colpa ai simpatici segnalatori (99,3% in DOFOLLOW pure:) del dominio Accademia della Crusca,perche' sono in realta solo dei Kamikaze e il danno lo fanno solo a loro stessi:) https://dinpoststory.blogspot.com/2025/07/syndicated-content-lost-brain-fgl-july.html
https://dinpoststory.blogspot.com/2025/07/syndicated-content-lost-brain-fgl-july.html
 La posizione specifica è questa,ed ho scelto la pubblicazione piu' vicina all'Average.
La posizione specifica è questa,ed ho scelto la pubblicazione piu' vicina all'Average. Questo è il link audit rispetto alla pubblicazione piu' vicina all'Average delle dimensioni e quindi i dati sono credibili,nonostante la demenza operativa:)
Questo è il link audit rispetto alla pubblicazione piu' vicina all'Average delle dimensioni e quindi i dati sono credibili,nonostante la demenza operativa:)  Le evidenze appartengono sempre alla pubblicazione piu vicina all'Average delle dimensioni (il collegamento è sistemato sopra) e a parte l'evidenza del Detect language,molto curiosa rispetto al dominio per antonomasia della lingua italiana,esiste anche l'evidenza nella Sidebar e indica semplicemente che esistono termini effettivi e sono presenti in tutte le pubblicazioni e formano i Common Content e sono dei Duplicati anche loro.
Le evidenze appartengono sempre alla pubblicazione piu vicina all'Average delle dimensioni (il collegamento è sistemato sopra) e a parte l'evidenza del Detect language,molto curiosa rispetto al dominio per antonomasia della lingua italiana,esiste anche l'evidenza nella Sidebar e indica semplicemente che esistono termini effettivi e sono presenti in tutte le pubblicazioni e formano i Common Content e sono dei Duplicati anche loro.
 Al termine di tutte le pubblicazioni di Accademia della Crusca (sempre attraverso termini effettivi,perche' non sono contenti dei Duplicati che gia possiedono:) esiste anche la Divertente "Amministrazione Trasparente" di Accademia della Crusca:
Al termine di tutte le pubblicazioni di Accademia della Crusca (sempre attraverso termini effettivi,perche' non sono contenti dei Duplicati che gia possiedono:) esiste anche la Divertente "Amministrazione Trasparente" di Accademia della Crusca: Questa è la verifica delle dimensioni della pubblicazione piu' vicina all'Average del dominio e i dati sono giusti.
Questa è la verifica delle dimensioni della pubblicazione piu' vicina all'Average del dominio e i dati sono giusti.  La Fantasia Infinita della Casualita' è sempre meravigliosa,ed è sufficente solo vedere il nome della pubblicazione che ha l'Average esatto di tutta la selezione (occorre ricordare che è formata da 246 pubblicazioni:) ed è "La Consulenza dei metadati" da parte del dominio di Accademia della Crusca e cioe' è un altro Gibberish Content anche questo e significa Puro Nonsense
La Fantasia Infinita della Casualita' è sempre meravigliosa,ed è sufficente solo vedere il nome della pubblicazione che ha l'Average esatto di tutta la selezione (occorre ricordare che è formata da 246 pubblicazioni:) ed è "La Consulenza dei metadati" da parte del dominio di Accademia della Crusca e cioe' è un altro Gibberish Content anche questo e significa Puro Nonsense 
 Questo è il suo Size e i dati sono giusti.
Questo è il suo Size e i dati sono giusti.  Questo è il link audit per la pubblicazione che ha l'Average esatto dei Size e quindi i TLP dell'intera selezione sono ampliamente Credibili (l'average è formato da 172 TLP) mentre i Metadati sopra possiedono 250 Links da sostenere rispetto a una pubblicazione da 1700 termini e il 55% è anche in Duplicato rispetto al contesto piu' ottimista possibile, perche i reports non hanno Struttura Data;non hanno Fundamental Search;possiedono 1 solo dominio e i contenuti potrebbero essere realizzati anche da Scraping completo o generative content e i reports esisterebbero lo stesso:)
Questo è il link audit per la pubblicazione che ha l'Average esatto dei Size e quindi i TLP dell'intera selezione sono ampliamente Credibili (l'average è formato da 172 TLP) mentre i Metadati sopra possiedono 250 Links da sostenere rispetto a una pubblicazione da 1700 termini e il 55% è anche in Duplicato rispetto al contesto piu' ottimista possibile, perche i reports non hanno Struttura Data;non hanno Fundamental Search;possiedono 1 solo dominio e i contenuti potrebbero essere realizzati anche da Scraping completo o generative content e i reports esisterebbero lo stesso:) Questo è un esempio di Metadati e sono i codici uniti ai contenuti tradizionali (ISBN) e la eISBN sono invece i Metadati del contesto online e lo stesso metodo è utilizzato anche per le immagini.
Questo è un esempio di Metadati e sono i codici uniti ai contenuti tradizionali (ISBN) e la eISBN sono invece i Metadati del contesto online e lo stesso metodo è utilizzato anche per le immagini. Anche gli ID di qualsiasi dominio,compresi gli indirizzi delle pubblicazioni sono dei Metadati e quindi la Consulenza di Accademia della Crusca è una Supercazzola oggettiva,perche' prima di fornire informazioni o consulenze sui dati (sono i Metadati) è indispensabile possederli:)
Anche gli ID di qualsiasi dominio,compresi gli indirizzi delle pubblicazioni sono dei Metadati e quindi la Consulenza di Accademia della Crusca è una Supercazzola oggettiva,perche' prima di fornire informazioni o consulenze sui dati (sono i Metadati) è indispensabile possederli:) Questo è un altro esempio di Metadato e sono proprio i codici ISBN e almeno il primo è di sicuro giusto,perche' appartiene a Penguin Random House e cioe' la casa editrice,proprietaria del copyright,rispetto alle opere dell'Holy Grail TFD Marcel Proust.
Questo è un altro esempio di Metadato e sono proprio i codici ISBN e almeno il primo è di sicuro giusto,perche' appartiene a Penguin Random House e cioe' la casa editrice,proprietaria del copyright,rispetto alle opere dell'Holy Grail TFD Marcel Proust.

 L'eISBN è nato da questa posizione,grazie ai termini festeggiati e in questa posizione cito solo la sezione evidenziata,perche' è straordinaria da unire a questo contesto:)
L'eISBN è nato da questa posizione,grazie ai termini festeggiati e in questa posizione cito solo la sezione evidenziata,perche' è straordinaria da unire a questo contesto:)
 Il senso di queste posizioni non è ancora finito,pero' tutte hanno l'unione con il Legitamate Publishers Unique Value,compresa la posizione sotto:)
Il senso di queste posizioni non è ancora finito,pero' tutte hanno l'unione con il Legitamate Publishers Unique Value,compresa la posizione sotto:) https://dinpoststory.blogspot.com/2018/12/din-colors-happy-things.html
https://dinpoststory.blogspot.com/2018/12/din-colors-happy-things.html  https://patents.google.com/?q=(long+power+over+time)&assignee=Philip+Morris+Products+Sa&status=APPLICATION&litigation=YES&scholar&page=1
https://patents.google.com/?q=(long+power+over+time)&assignee=Philip+Morris+Products+Sa&status=APPLICATION&litigation=YES&scholar&page=1  Questi sono i veri motivi per cui il finanziamento di Open AI non è unito al Reinventing Search,ma al Market Share rispetto al business del contesto online:)
Questi sono i veri motivi per cui il finanziamento di Open AI non è unito al Reinventing Search,ma al Market Share rispetto al business del contesto online:) Questo è il Search Result API e per essere valido,è indispensabile avere le posizioni sistemate sopra oppure utlizzare direttamente i termini festeggiati,perche' l'Original Unique e Content Value, è il valore delle Proposte Complessive e potranno essere Piu' o Meno Rilevanti,pero' debbono prima ESISTERE e se fosse presente il Keywords Stuffing è esattamente l'opposto e cioe' i contenuti sono proprio eliminati e qualsiasi dato fosse unito a loro,diventa tutto Invalid Traffic:)
Questo è il Search Result API e per essere valido,è indispensabile avere le posizioni sistemate sopra oppure utlizzare direttamente i termini festeggiati,perche' l'Original Unique e Content Value, è il valore delle Proposte Complessive e potranno essere Piu' o Meno Rilevanti,pero' debbono prima ESISTERE e se fosse presente il Keywords Stuffing è esattamente l'opposto e cioe' i contenuti sono proprio eliminati e qualsiasi dato fosse unito a loro,diventa tutto Invalid Traffic:)  Questo è un altro Search Result API e per essere valido è possibile bypassare anche il Keywords Stuffing unito all'Invalid Traffic,perche' i dati veri da cui derivano i reports,comprese le API,sono proprio quelli festeggiati:)
Questo è un altro Search Result API e per essere valido è possibile bypassare anche il Keywords Stuffing unito all'Invalid Traffic,perche' i dati veri da cui derivano i reports,comprese le API,sono proprio quelli festeggiati:) https://support.google.com/a/answer/13306955?hl=en
https://support.google.com/a/answer/13306955?hl=en  Questi sono i dati delle categorie e per avere il loro numero,è sufficente eliminare un centinaio di termini uniti alle descrizioni e dividere il resto per 3 o 4 termini e si ha il numero delle categorie,ed è sufficente solo vederle,per immaginare anche il numero di Fact Check che possono avere,ed è facile la comparazione con questi contenuti,perche' solo nella pubblicazione presente,è molto probabile che esistano un numero di fact Check piu' elevato,rispetto a tutto l'elenco delle categorie sistemato sopra:)
Questi sono i dati delle categorie e per avere il loro numero,è sufficente eliminare un centinaio di termini uniti alle descrizioni e dividere il resto per 3 o 4 termini e si ha il numero delle categorie,ed è sufficente solo vederle,per immaginare anche il numero di Fact Check che possono avere,ed è facile la comparazione con questi contenuti,perche' solo nella pubblicazione presente,è molto probabile che esistano un numero di fact Check piu' elevato,rispetto a tutto l'elenco delle categorie sistemato sopra:) 
 Questa è la LOGICA unita al VERO Intento dell'Holy Grail TFD Microsoft,tramite il generative traffic (è Spam e cioe' Invalid Traffic:) e cioe' la vera attivita di Opern AI,oltre a quella di bolla speculativa:)
Questa è la LOGICA unita al VERO Intento dell'Holy Grail TFD Microsoft,tramite il generative traffic (è Spam e cioe' Invalid Traffic:) e cioe' la vera attivita di Opern AI,oltre a quella di bolla speculativa:) Questa è la posizione attuale delle General Guidelines di Microsoft,largamente compatibili con quelle di Google,rispetto ai generative e insieme al Traffic (SPAM:) è presente nelle penalita anche i generative dei content e il contesto è anche normale,perche' è vero che l'Holy Grail TFD Microsoft ha finanziato Open AI (utilizza anche i calculator di Microsof Azure giusto per non farla fallire solo con il costo dell'energia elettrica:) e lo ha fatto solo allo scopo di avere vantaggi nel Market Share degli Engines e cioe nel vero business del contesto online (il Reinventing Search significa proprio questo:) e per lo stesso motivo fornisce il suo Powered a tutti gli altri Engines e quindi figurarsi che valore hanno i dati dell'Holy Grail TFD Google:)
Questa è la posizione attuale delle General Guidelines di Microsoft,largamente compatibili con quelle di Google,rispetto ai generative e insieme al Traffic (SPAM:) è presente nelle penalita anche i generative dei content e il contesto è anche normale,perche' è vero che l'Holy Grail TFD Microsoft ha finanziato Open AI (utilizza anche i calculator di Microsof Azure giusto per non farla fallire solo con il costo dell'energia elettrica:) e lo ha fatto solo allo scopo di avere vantaggi nel Market Share degli Engines e cioe nel vero business del contesto online (il Reinventing Search significa proprio questo:) e per lo stesso motivo fornisce il suo Powered a tutti gli altri Engines e quindi figurarsi che valore hanno i dati dell'Holy Grail TFD Google:) E' dedicata alle Sitemap e l'aspetto tecnico è nella pubblicazione collegata e in questa posizione è sufficente aggiungere il Divertimento alle Sitemap stesse, sopratutto nei confronti degli operatori SEV (Open AI ne fa' parte:) perche' quasi sempre i loro domini sono Infestati da Unnatural Links e quindi è molto facile superare l'Error Rate:)
E' dedicata alle Sitemap e l'aspetto tecnico è nella pubblicazione collegata e in questa posizione è sufficente aggiungere il Divertimento alle Sitemap stesse, sopratutto nei confronti degli operatori SEV (Open AI ne fa' parte:) perche' quasi sempre i loro domini sono Infestati da Unnatural Links e quindi è molto facile superare l'Error Rate:)  Questa posizione è meravigliosa da unire ai domini SEV,Open AI compresa e conferma i veri intenti dell'Holy Grail TFD Microsoft e sono esclusivamente quelli del Market Share degli Engines e la scelta è anche molto facile,perche' tutte le altre posizioni dei generative content (Open AI compresa) hanno come unica sicurezza quella del Fallimento:)
Questa posizione è meravigliosa da unire ai domini SEV,Open AI compresa e conferma i veri intenti dell'Holy Grail TFD Microsoft e sono esclusivamente quelli del Market Share degli Engines e la scelta è anche molto facile,perche' tutte le altre posizioni dei generative content (Open AI compresa) hanno come unica sicurezza quella del Fallimento:)  https://dinpoststory.blogspot.com/2021/11/din-data-demo-8d-78-rf.html
https://dinpoststory.blogspot.com/2021/11/din-data-demo-8d-78-rf.html 

 La data dell'URL formera' la distinzione,rispetto alle altre selezioni che aggiungero' e semplicemente,dopo la pubblicazione precedente,mi è venuto in mente di fare il secondo Takeout,pero' questa volta in maniera piu' dettagliata,rispetto al Takeout stesso e inizia proprio dalla posizione sistemata sopra (1 Select Data e quelli disponibili ne sono 71,sempre su Google Data:)
La data dell'URL formera' la distinzione,rispetto alle altre selezioni che aggiungero' e semplicemente,dopo la pubblicazione precedente,mi è venuto in mente di fare il secondo Takeout,pero' questa volta in maniera piu' dettagliata,rispetto al Takeout stesso e inizia proprio dalla posizione sistemata sopra (1 Select Data e quelli disponibili ne sono 71,sempre su Google Data:)